Your Base Model Is Smarter Than You Think: And Here's How to Prove It

There's a quiet assumption baked into most of the recent excitement around reasoning models: that the impressive gains you see from systems like DeepSeek-R1 or similar RL-trained models come from something genuinely new: novel capabilities that the base model simply didn't have before training. A new paper challenges that assumption pretty directly, and the results are hard to ignore.
The core claim: you can match RL-post training performance on reasoning tasks without any training at all, just by being smarter about how you sample from the base model.
The Setup: What Is RL-Post training Actually Doing?
To understand why this matters, a quick refresher. The dominant way to improve LLM reasoning right now is reinforcement learning with verifiable rewards (RLVR). You give the model a math or coding problem, it generates an answer, an automated verifier checks if it's correct, and you update the model's weights to make it more likely to produce correct answers in the future. The algorithm most associated with this is GRPO (Group Relative Policy Optimization), which has been central to the DeepSeek-Math and related lines of work.
Models trained this way see big jumps on benchmarks like MATH500 and HumanEval, making them quite impressive. But researchers have been arguing about why it works. One camp says RL is teaching the model fundamentally new reasoning strategies. Another says it's mostly just distribution sharpening, ie**.** the model already knew how to solve these problems, RL just made it more likely to actually try the right approach on the first shot.
The paper sides firmly with the second camp and then goes further, proposing an algorithm that achieves the same sharpening effect without touching the model weights at all.
The Key Idea: Power Distributions
The insight starts with a simple mathematical observation. If you have a probability distribution p over sequences and you exponentiate it (computing p^α for some α > 1) you end up with a "sharpened" version of the original distribution. High-probability sequences get relatively more weight, low-probability sequences get relatively less. This is exactly what you'd want if you believe the base model already assigns higher probability to correct reasoning traces, just not high enough probability for them to dominate in standard sampling.
This sharpened distribution is called the power distribution p^α, and the claim is that sampling from it should give you something similar to what RL-posttraining produces.
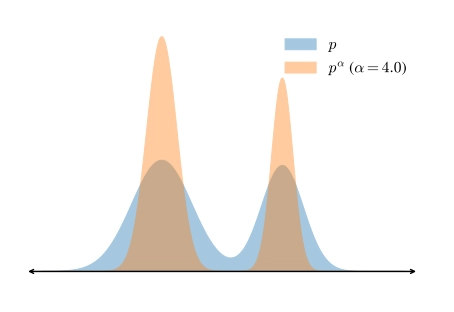
Why Not Just Use Temperature?
Here's where it gets technically interesting. You might think: "I already know about temperature sampling, can't I just lower the temperature to get the same effect?" The answer is no, and the paper proves it.
Low-temperature sampling works by exponentiating the conditional next-token distribution at each step. But sampling from the full power distribution p^α requires weighting token choices by the sum of exponentials over all future continuations:
These are not the same thing. Temperature sampling computes an "exponent of sums," while the power distribution requires a "sum of exponents." The difference matters in practice.
The intuitive consequence: low-temperature sampling tends to prefer tokens with many plausible futures (even if each individual future is mediocre), while power distribution sampling prefers tokens that commit to fewer but higher-quality futures. This is exactly the kind of planning behaviour you want for reasoning tasks, where taking a wrong fork early can doom the entire response.
The paper formalizes this with a "pivotal token" argument: some tokens in a reasoning chain are critical branch points. A token that seems locally reasonable but leads to a low-likelihood completion is exactly what temperature sampling fails to avoid, but what power sampling is designed to penalize.
The Algorithm: MCMC to the Rescue
Sampling from p^α directly is computationally intractable since it would require summing over all possible token continuations, which is exponentially large. The paper gets around this with Metropolis-Hastings (MH), a classic Markov chain Monte Carlo technique.
The key property of MH is that you can approximately sample from an unnormalized distribution (which p^α is, since you can compute relative probabilities without the normalizing constant) using a simpler "proposal distribution." The algorithm:
- Start with an initial sequence.
- Randomly select a position t in the sequence and resample everything from position t onward using the base model.
- Accept or reject the new sequence based on the ratio of p^α values between the new and old sequences.
- Repeat.
If the new sequence has higher p^α, it gets accepted with high probability. If it's worse, it might still be accepted (with some probability proportional to how much worse it is), which prevents the chain from getting stuck.
You only need the base model log-probabilities: no verifier, no reward model, nothing extra.
Making It Work for Autoregressive Models
Naive MH on long sequences would be very slow to mix (there's a well-known problem where the Markov chain takes an exponentially long time to explore the space if initialized poorly). The paper's practical solution is to process the sequence in blocks, building up from shorter to longer sequences:
- First, sample and MCMC-refine the first B tokens.
- Then extend by B tokens, run MCMC on the full prefix so far.
- Continue until the sequence is complete.
This progressive approach avoids pathological initializations and makes the mixing time much more tractable. The total token count generated scales roughly as (N_MCMC × T²) / (4B), so the computational cost is controllable.
In their experiments, the algorithm generates about 8.84× as many tokens as standard inference — comparable in cost to running one epoch of GRPO training.
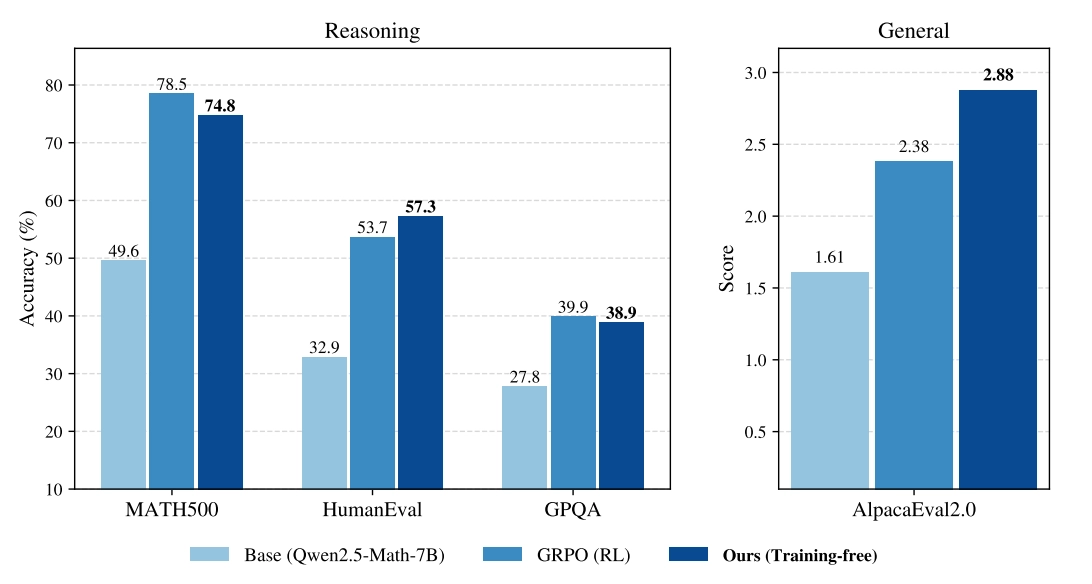
The Results
The numbers speak for themselves. Testing on three base models (Qwen2.5-Math-7B, Qwen2.5-7B, and Phi-3.5-mini-instruct) across MATH500, HumanEval, GPQA, and AlpacaEval 2.0:
| MATH500 | HumanEval | GPQA | AlpacaEval | |
|---|---|---|---|---|
| Base (Qwen2.5-Math-7B) | 49.6% | 32.9% | 27.8% | 1.61 |
| GRPO (RL) | 78.5% | 53.7% | 39.9% | 2.38 |
| Power Sampling (theirs) | 74.8% | 57.3% | 38.9% | 2.88 |
On MATH500, the benchmark GRPO was specifically trained on, power sampling gets within ~4 points. On HumanEval and AlpacaEval, it actually outperforms GRPO, despite seeing no training signal at all. On GPQA, they're essentially tied.
The results hold across model families, which suggests this isn't a quirk of one particular architecture or training run.
The Diversity Advantage
One of the most interesting secondary findings has to do with diversity. A known downside of RL-posttraining is that it narrows the model's output distribution. The model becomes more likely to produce a small set of high-confidence responses, which is great for single-shot accuracy but bad if you want to explore multiple possible solutions.
This is visible in pass@k performance: if you sample k responses and ask "did at least one get it right?", RL models plateau quickly because their samples are highly similar to each other. Base models do better at high k because they generate more varied responses.
Power sampling gets the best of both worlds. Since it's explicitly sampling from the base model distribution (just a sharpened version of it), it retains meaningful diversity. In the paper's pass@k plots on MATH500, power sampling strictly dominates both GRPO and the base model at every value of k from 1 to 16. At large k, it converges to the base model's upper bound (as expected), but at small k it matches GRPO's single-shot accuracy.
This matters practically: if you're building a system that generates and evaluates multiple candidate responses, power sampling may be significantly better than using an RL-postrained model.
Why This Is Surprising (and What It Implies)
The paper is careful not to overclaim. Power sampling doesn't beat RL on in-domain tasks by a wide margin, and there's still a gap on MATH500. But the fact that a training-free, verifier-free, dataset-free algorithm comes this close forces a rethink of what RL is actually contributing.
If most of the gain from RL-posttraining is recoverable through smarter sampling, then the "novel capabilities" narrative loses a lot of its force. The knowledge and reasoning ability were already in the base model — RL was mostly changing the probability that those capabilities get expressed in a single forward pass.
This also has practical implications. RL training is expensive and finicky — it requires curated datasets, careful hyperparameter tuning, and access to a reliable verifier or reward model (which isn't available for many domains). Power sampling needs none of that. You just need the base model and some extra inference compute.
The paper's framing puts it well: this suggests that inference-time compute is a more underexplored axis than we've appreciated, and that building better samplers might be a more general path to improved reasoning than fine-tuning — especially in domains where ground-truth verifiers don't exist.
Open Questions
That said, there are some things worth noting as limitations or open questions:
Computational cost is non-trivial. At ~9× standard inference cost, power sampling isn't free. Whether that's acceptable depends heavily on your use case and budget.
The hyperparameter α matters, but is robust. The paper finds α = 4.0 works well, and performance is relatively stable above α = 2.0, which is reassuring. But it's still a parameter to tune.
It hasn't been tested on frontier-scale models. The experiments use 7B-parameter models. Whether the same dynamics hold for 70B+ models, or for models that have already undergone extensive instruction tuning, is an open question.
The relationship to RL isn't fully resolved. Power sampling demonstrates that sharpening is achievable without training, but doesn't fully explain why RL and power sampling converge to similar places. Understanding the theoretical connection more precisely would be valuable.
The Bottom Line
This is a genuinely thought-provoking result. The idea that careful inference-time sampling can approximate the effect of thousands of gradient steps is both surprising and, in retrospect, maybe not so shocking — if you believe that capable base models already contain the reasoning patterns you want, the question was always whether standard decoding was an efficient way to surface them.
The answer, apparently, is no. And the fix is an elegant application of ideas from statistical physics and Monte Carlo methods that have been around for decades, just never applied in this way.
Whether power sampling becomes practically widely adopted depends on whether the compute cost is acceptable at scale. But as a scientific result about the nature of base model capabilities, it's a compelling piece of evidence that the reasoning revolution may be less about training new skills and more about finding better ways to use what's already there.
Check the paper here: Reasoning with Sampling: Your Base Model is Smarter Than You Think


