When Your AI Transcription Turns "Tasty Burger" Into "Nasty Murder"

Introducing Maxim AI's first Voice Evaluators: SNR and WER
We've all been there. You're relying on AI transcription for that crucial customer call analysis, and suddenly "increase our market share" becomes "increase our marker chair." While these mix-ups might seem amusing, they represent a serious challenge that's plaguing the entire Voice AI industry.
Why Audio Quality is a Big Challenge Voice AI
The industry is waking up to the audio quality crisis. Just this March, OpenAI rolled out significant noise cancellation updates to their models - a clear signal that even the biggest players recognize poor audio quality as a fundamental bottleneck in Voice AI systems.
Here's what's really happening behind the scenes:
Voice AI Hallucinations: When audio quality degrades, AI systems don't just make transcription errors - they hallucinate entirely.
The Cascade Effect: Bad transcriptions poison everything downstream - intent detection, sentiment analysis, keyword extraction, etc., all suffer when the foundation is built on garbled audio.
The Reactive Problem: By the time you notice the audio was bad, it's too late. One inference down - you've already shown a broken experience, spent credits, and triggered a costly chain of reprocessing and patchwork.
Today, we're excited to announce Maxim AI's first two Voice Evaluators, designed to tackle this exact problem: SNR (Signal-to-Noise Ratio) for noise detection and WER (Word Error Rate) for transcription accuracy monitoring.
What Our Research Reveals About Audio Quality Impact
Our research across five leading transcription models - OpenAI whisper-1, Google gemini-2.5-pro, OpenAI gpt-4o-transcribe, ElevenLabs Scribe v1, and AssemblyAI Universal reveals just how dramatic this impact can be. It confirms what the industry is scrambling to address: a direct correlation between audio SNR and AI performance -
- At 5 dB SNR: Word Error Rates skyrocket above 30%, making transcriptions nearly unusable
- At 25 dB SNR: Error rates drop to single digits or low teens
- The sweet spot: Even a 5-10 dB improvement in audio quality can reduce errors by 20-40%
Fascinating Model Behavior Pattern: Our analysis reveals an interesting split in how different model types handle extreme noise:
- In severe noise conditions (0-10 dB SNR): Specialized transcription models like ElevenLabs Scribe v1 and AssemblyAI Universal show surprising resilience, often outperforming general-purpose LLMs
- In moderate to clean conditions (above 10 dB SNR): The pattern flips - general-purpose models like Google gemini-2.5-pro and OpenAI gpt-4o-transcribe / whisper-1 take the lead with superior accuracy
- Overall, gemini-2.5-pro consistently outperforms other models in moderately noisy conditions, often achieving WERs 10-15% lower than competitors.
WER vs SNR for Transcription Models
Meet Your New Audio Quality Guards
Maxim SNR Evaluator
The SNR evaluator works like a bouncer for your transcription pipeline - it checks audio quality before you spend money processing it. Using blind estimation (no clean sample reference needed), it instantly tells you:
- Calculated SNR: Precise measurement in decibels
- Quality Label: Business-friendly labels like "Good," "Acceptable," "Poor," or "Very Bad"
Maxim WER Evaluator
While SNR catches problems upfront, the WER evaluator keeps your transcription accuracy in check by comparing outputs against ground truth, helping you:
- Monitor model performance across different audio conditions
- Compare transcription services objectively
- Identify drift in transcription quality over time
- Optimize model selection based on your specific use cases
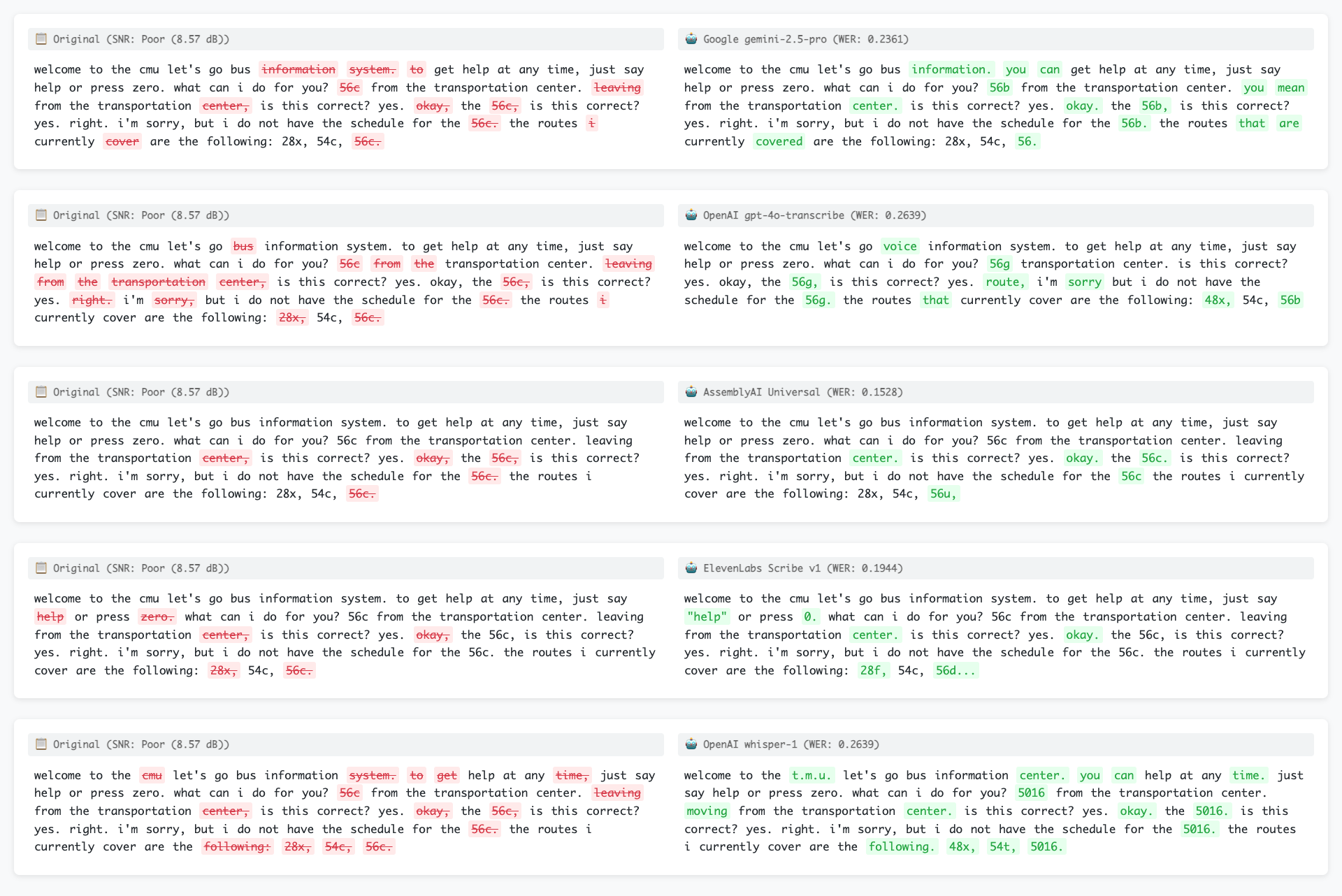
Below is a real-world audio example where the SNR evaluator flags the audio as “Poor”, and the WER evaluator highlights the downstream transcription errors - showcasing how the two work in tandem to catch and explain downstream Voice AI quality issues!
See Them in Action
Want to see real evaluation outputs? Check out these live examples from our platform:
SNR Evaluation Report: View Live Report →
See how our SNR evaluator categorizes audio samples and predicts transcription challenges
WER Evaluation Report: View Live Report →Compare transcription accuracy across different models and audio conditions
Ready to Take Control of Your Audio Quality?
Whether you're building voice assistants, analyzing customer calls, or transcribing meetings, audio quality shouldn’t be an afterthought. Our SNR and WER evaluators give you the insight and confidence to deliver reliable, cost-effective Voice AI experiences.
Get started today:
- ⚡ Quick Start: Sign up for free evaluation credits
- 🔧 Easy Integration: RESTful APIs & SDKs with comprehensive documentation
- 📊 Instant Insights: Real-time AI quality assessments and monitoring
- 💡 Expert Support: Our team helps optimize your evaluation strategy


