What GenSE Gets Right For LLM-Assisted Speech Enhancement 🎙️

Speech enhancement, the art of cleaning up noisy, muffled, or degraded audio, has traditionally been the domain of signal processing algorithms and convolutional networks. But what if we treated speech cleaning like a language problem instead?
That's exactly what researchers from Northwestern Polytechnical University and Nanyang Technological University did with GenSE (Generative Speech Enhancement), a system that uses transformer-based language models to restore clean speech from noisy audio. And the results? They're beating state-of-the-art methods by significant margins.
The Core Insight: Speech as Tokens, Enhancement as Translation
The key breakthrough is conceptual. Instead of treating speech enhancement as a continuous signal processing problem, GenSE frames it as a discrete token prediction task: like translating from "noisy speech tokens" to "clean speech tokens."
Here's how it works:
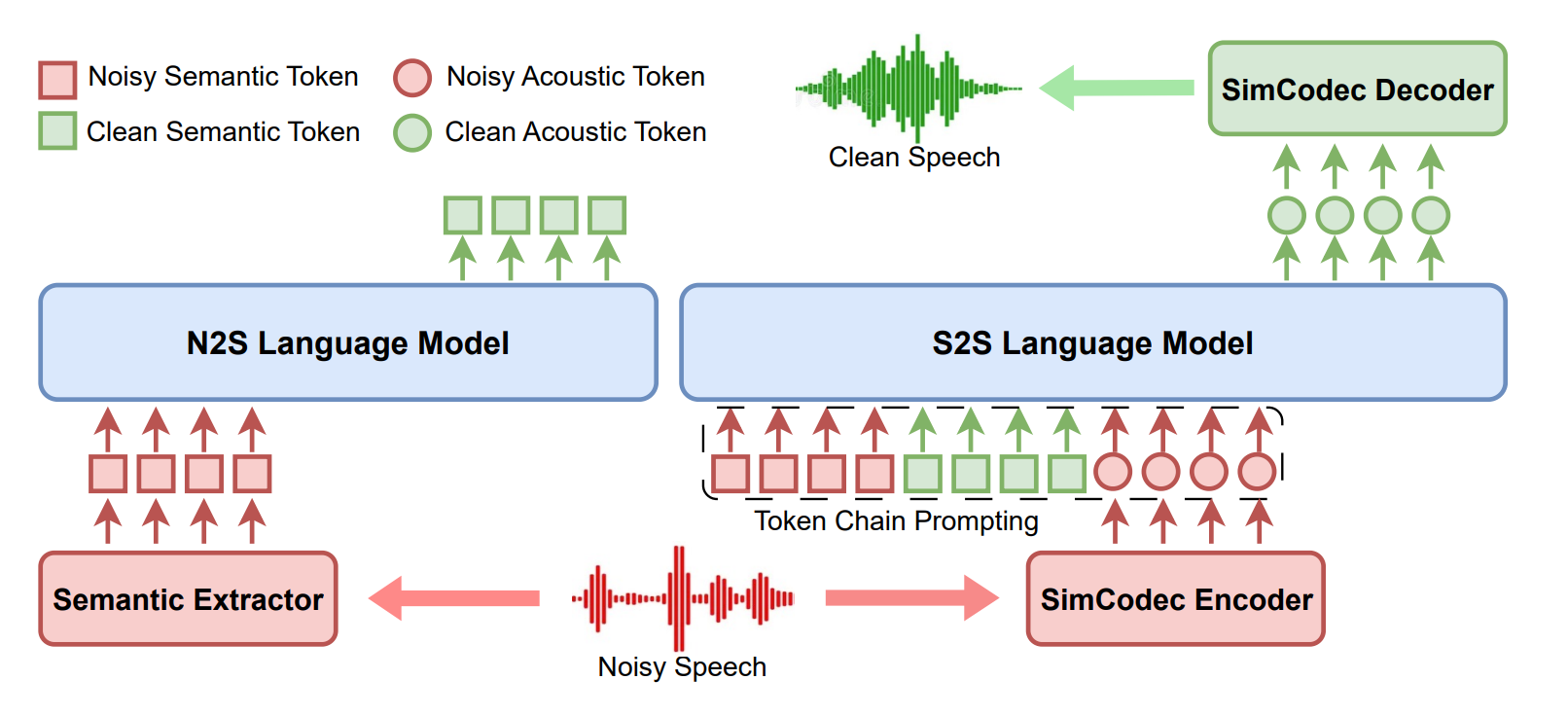
- Dual tokenization strategy : The system converts audio into two complementary discrete representations:
- Semantic tokens (1024-dimension codebook): Extracted using XLSR-300M, these capture phonetic and linguistic content at 20ms frames through k-means clustering of transformer representations
- Acoustic tokens (8192-dimension codebook): Generated by SimCodec at 50-100 Hz, preserving waveform details needed for high-fidelity reconstruction
- Hierarchical language model architecture : Two separate decoder-only transformers handle different aspects:
- N2S module: Autoregressive LM that transforms noisy semantic tokens into clean semantic tokens using next-token prediction
- S2S module: Generates clean acoustic tokens conditioned on both semantic representations plus noisy acoustic tokens.
- Token chain prompting: The S2S module concatenates noisy semantics + clean semantics + noisy acoustics as context, ensuring speaker timbre consistency during enhancement
- SimCodec reconstruction: Single-quantizer decoder converts acoustic tokens back to 16kHz waveform
SimCodec and the Quantization Challenge
The biggest technical hurdle for LM-based audio processing has always been tokenization efficiency. Standard neural audio codecs like EnCodec use residual vector quantization (RVQ) with 8 quantizers, each with 1024-size codebooks. This produces 600-900 tokens per second, which understandably, is a nightmare for transformer training.
The researchers solved this with SimCodec, a custom neural audio codec that uses just one quantizer but maintains quality through a clever "reorganization process":
Stage 1 - Group Quantization: Instead of residual quantization (where later quantizers handle residuals), SimCodec uses group quantization with two smaller codebooks (512 each). This ensures more balanced information distribution across quantizers, unlike RVQ where the first quantizer captures most information.
Stage 2 - Reorganization Process:
- Analyze codebook usage statistics from Stage 1
- Select the top N most-used embeddings from quantizer 1 and top K from quantizer 2
- Pairwise concatenate these embeddings to create a new codebook of size N×K (typically 8192)
- Initialize new projection layers and fine-tune with this reorganized single quantizer
- Result: High-quality reconstruction with 50-100 tokens per second instead of 600-900
The key insight: instead of trying to train a massive single quantizer from scratch (which leads to poor codebook utilization and training instability), they bootstrap from a well-trained dual-quantizer system. The codec uses GAN-based training optimization and achieves achieves 3.05 PESQ at 1.3kbps with only 100 tokens/second, a 9x decrease in sequence length which makes training actually feasible.

Why Hierarchical Modeling?
The decision to use two separate language models instead of a single end-to-end system is a crucial architectural choice that addresses fundamental challenges in noisy speech processing.
The problem with end-to-end approaches is that noise corrupts the input audio, both semantic and acoustic tokenization become unreliable. A single model trying to handle both denoising and generation simultaneously faces a complex optimization landscape with competing objectives.
GenSE's Hierarchical Solution:
- N2S Module (Noise-to-Semantic):
- 12-layer decoder-only transformer with 512 hidden dimensions
- Processes concatenated sequences: [noisy_semantic_tokens, clean_semantic_tokens]
- Focus: pure denoising in semantic space where noise effects are already filtered by XLSR's robustness
- S2S Module (Semantic-to-Speech):
- 24-layer decoder-only transformer with 1024 hidden dimensions
- Input: token chain prompt combining all available context
- Output: clean acoustic tokens for high-fidelity reconstruction
- Focus: generation conditioned on clean semantic content
Token Chain Prompting Mechanism: The S2S module receives a carefully constructed context sequence:
[noisy_sem_1, ..., noisy_sem_T, clean_sem_1, ..., clean_sem_T, noisy_ac_1, ..., noisy_ac_T, clean_ac_1, ...]
This design ensures the model has access to:
- Clean semantic content (what should be said)
- Original speaker characteristics (from noisy acoustic tokens)
- Temporal alignment information across modalities
Why Semantic-First Processing Works
Traditional speech enhancement methods work purely on acoustic signals. They don't "understand" what's being said, so they can struggle with complex scenarios where context matters.
GenSE, by contrast, explicitly models semantic content first. The system knows what words are being spoken before it worries about acoustic details. This semantic awareness helps it:
- Maintain speaker identity more consistently
- Handle domain shifts better (works on new types of noise it wasn't trained on)
- Preserve linguistic content even in challenging conditions
The results back this up. When tested on the CHiME-4 dataset (real-world noise recordings), GenSE shows much smaller performance drops than conventional methods when faced with unfamiliar noise types.
The Results: Significant Improvements
The evaluation is comprehensive, testing on both standard metrics and human perception:
Objective metrics: GenSE achieves the best scores on DNSMOS (Microsoft's speech quality metric), speaker similarity measures, and intelligibility tests. The performance bump is significant, often 15-40% better than previous state-of-the-art.
Subjective evaluation: Human listeners consistently prefer GenSE's output over competing methods for both naturalness and speaker similarity.
Generalization: When tested on completely different noise conditions, GenSE maintains performance much better than deterministic approaches.
The Broader Context: LLMs Beyond Text
This work sits in a growing trend of applying large language model architectures to domains beyond text. We've seen similar approaches in computer vision, protein folding, and now audio processing.
The pattern is consistent: convert your domain-specific data into discrete tokens, then let transformer architectures work their magic. But the key insight here is that the tokenization strategy matters enormously. SimCodec's efficiency gains are what make the whole approach practical.
The Challenges AHead
The main limitation is inference speed. Autoregressive generation means processing tokens one by one, which is too slow for real-time applications. The authors suggest alternating token prediction patterns and model quantization as potential solutions.
But even in its current form, GenSE represents a meaningful advance in speech enhancement, showing that the transformer revolution isn't limited to text generation.
The Technical Takeaway
GenSE demonstrates three key principles for applying language models to non-text domains:
- Tokenization is critical: How you convert continuous signals to discrete tokens determines everything downstream
- Hierarchical modeling helps: Separating semantic and acoustic processing reduces complexity
- Domain adaptation works: Pre-trained models (like XLSR for speech representations) provide strong foundations
For researchers working on multimodal AI or anyone interested in how transformers might reshape traditional signal processing, GenSE offers a compelling proof of concept. The semantic understanding that comes naturally to language models might be exactly what many engineering domains have been missing.
Check out the paper here: https://openreview.net/pdf?id=1p6xFLBU4J


