VITA-Audio: Making AI Voice Assistants Actually Feel Instant

Have you ever noticed that frustrating pause when you ask your voice assistant a question? You speak, there's a beat of silence, and then it finally starts responding. That delay might seem minor, but it breaks the natural flow of conversation and reminds you that you're talking to a machine, not a person.
A new research paper introduces VITA-Audio, a breakthrough that could make AI voice interactions feel truly instantaneous. Let's dive into how they're solving one of the biggest bottlenecks in conversational AI.
The Latency Problem
Modern speech AI systems are impressive. They can understand context, generate human-like responses, and even capture emotion in their voice. But there's a hidden technical challenge that plagues nearly all of them: first token latency.
When these systems generate speech, they produce it as a series of small audio chunks called "tokens." Traditional models generate these tokens one at a time, sequentially. This means:
- Generate the first audio token → wait
- Generate the second token → wait
- Generate the third token → wait
- And so on...
For streaming applications where you want audio to start playing immediately, that initial wait for the first token creates a noticeable lag. In real-time conversations, even a fraction of a second matters.
Enter VITA-Audio: Thinking Ahead Instead of One Word at a Time
The researchers behind VITA-Audio decided to break that paradigm. Instead of generating one audio token at a time, they sought to generate multiple in a single forward pass through the model. This is where their key innovation comes in: Multiple Cross-Modal Token Prediction.
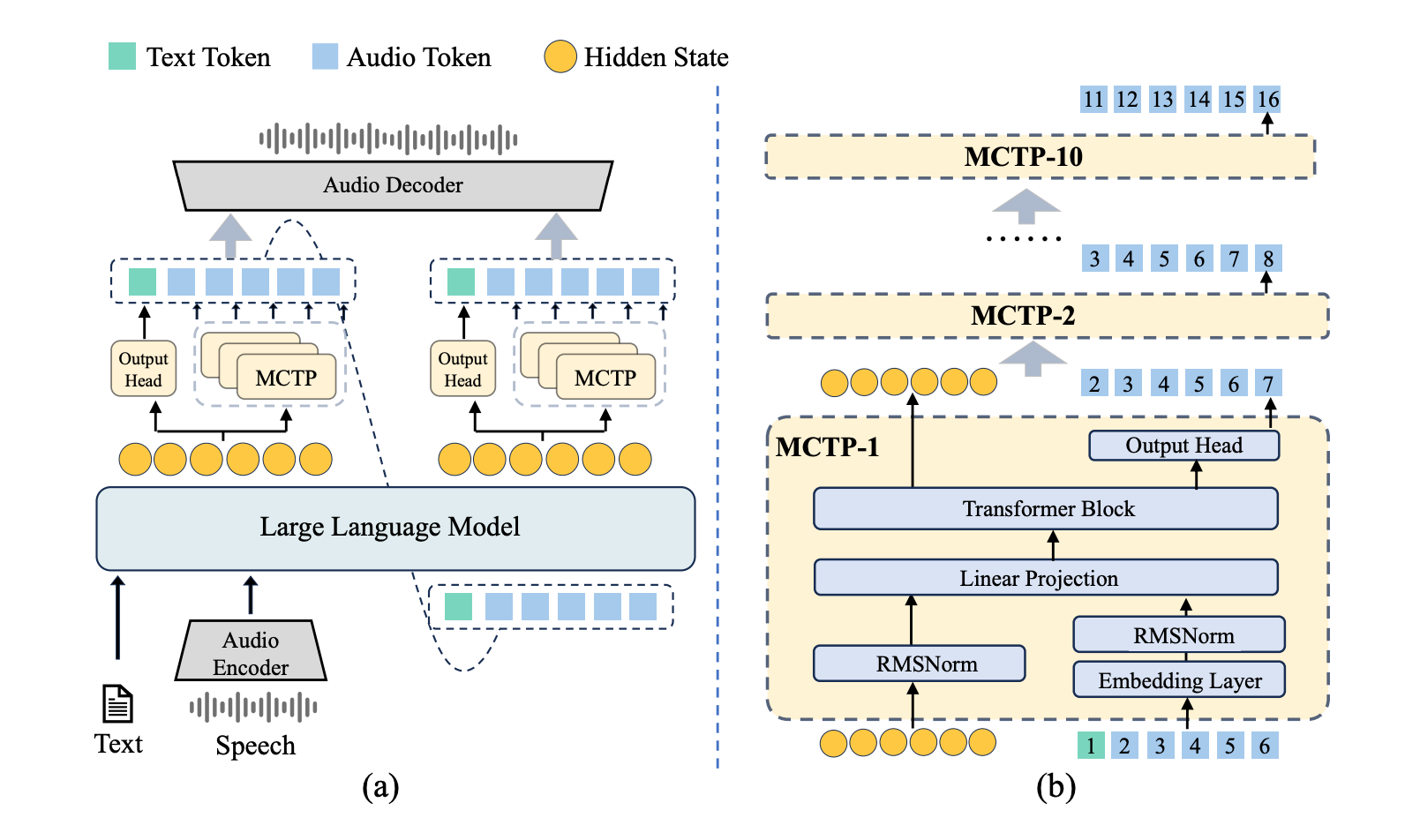
How MCTP Works
Think of it like the difference between:
- Traditional approach: A speaker who thinks of each word individually before saying it
- MCTP approach: A speaker who plans out the next few words in their head and speaks them fluidly
By generating multiple audio tokens at once, VITA-Audio dramatically reduces the time it takes to:
- Produce the first bit of audio (critical for perceived responsiveness)
- Generate the complete response (overall inference speed)
And here's the impressive part: they achieved this while keeping the system lightweight and efficient. Many speedup techniques come at the cost of massive computational requirements, but VITA-Audio was designed with practicality in mind.
Smart Training: Learning to Be Fast
Speed without quality is useless. You can't just tell a model to "generate faster" and expect good results. The VITA-Audio team developed a four-stage progressive training strategy that gradually teaches the model how to accelerate its generation while maintaining audio quality.
This progressive approach is like teaching someone to speed-read: you don't just tell them to read faster; you train them systematically to process information more efficiently without losing comprehension.
Here's how the researchers progressively built up VITA-Audio's capabilities:
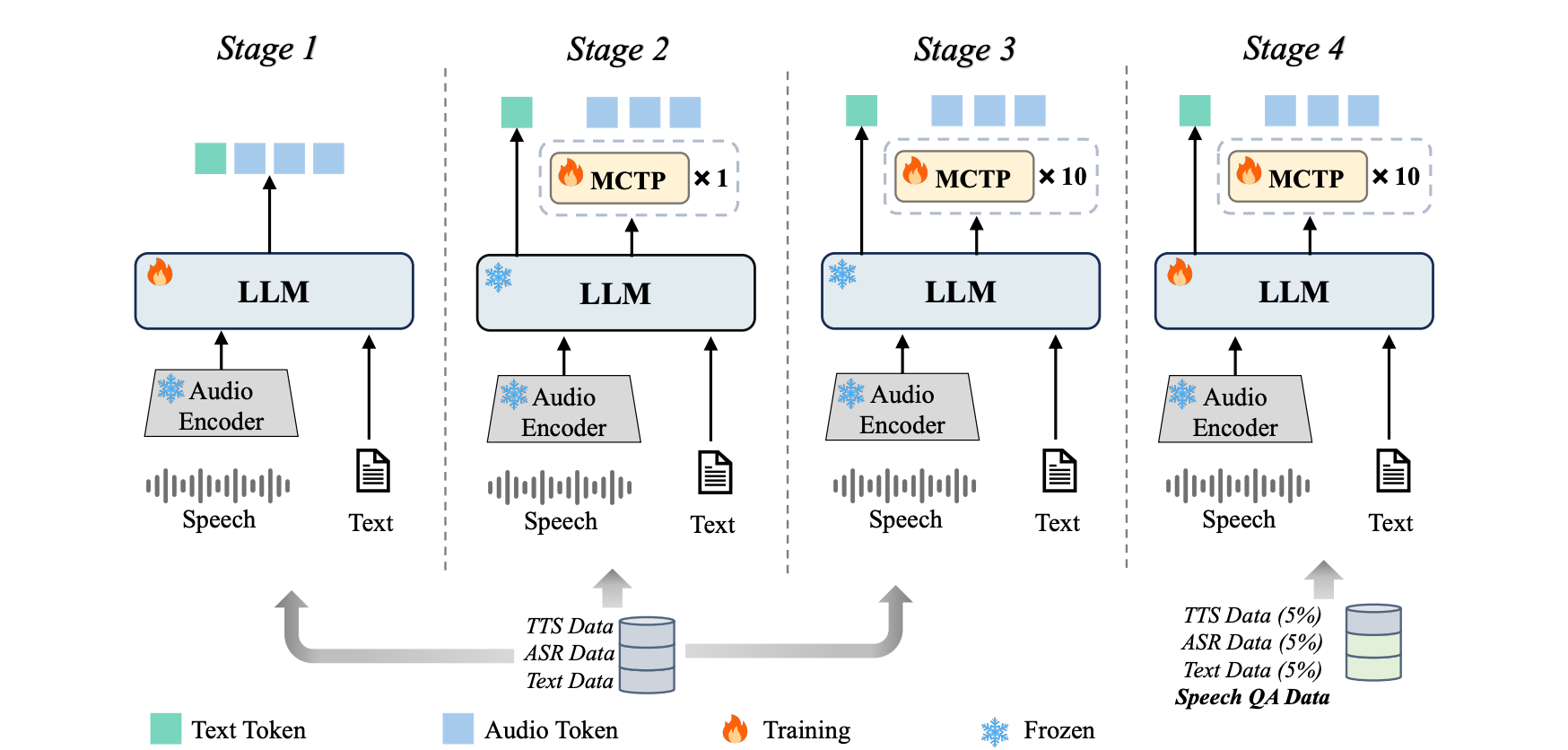
Stage 1: Audio-Text Alignment
In this foundational stage, the model learns to understand and generate audio based on a pretrained language model. The researchers freeze the audio encoder and decoder and focus on training the LLM using three types of data:
- ASR data (Automatic Speech Recognition - converting speech to text)
- TTS data (Text-to-Speech - converting text to speech)
- Text-only data (pure language understanding)
At this stage, the LLM's output can be either pure text tokens or audio tokens. Think of this as teaching the model the basic vocabulary and grammar of both text and audio, establishing that fundamental connection between the two modalities.
Stage 2: Single MCTP Module Training
Now things get interesting. The researchers introduce a single MCTP module and train it to predict just one additional audio token based on the LLM's outputs and hidden states. This is done using the same dataset from Stage 1.
Crucially, they use a technique called "gradient detachment" from the LLM. This means the MCTP module learns without forcing changes back into the main language model, allowing it to specialize in its task without disrupting what the LLM already knows.
This stage is like teaching someone to think one word ahead while speaking: not a huge leap, but an important foundation for what comes next.
Stage 3: Multiple MCTP Modules Training
Here's where the magic happens. The researchers scale from one MCTP module to multiple modules, each predicting a token at its designated position. Each module builds on the outputs and hidden states from the previous module, creating a chain of predictions.
The challenge? Each MCTP module needs to model a different distribution, and training them all simultaneously is difficult because their optimization objectives don't naturally align. By progressively training them (rather than all at once), the researchers reduce this convergence difficulty.
The result: the model can predict 10 audio tokens directly from historical inputs and LLM hidden states without requiring additional LLM forward passes. That's a 10x increase in tokens per forward pass compared to traditional approaches!
Stage 4: Supervised Fine-Tuning
In the final stage, the model is fine-tuned on speech QA datasets, along with smaller amounts of TTS, ASR, and text-only data. This gives VITA-Audio true speech-to-speech dialogue capability.
Different learning rates are used for the MCTP modules versus the main LLM, allowing each component to optimize at its own pace. This stage polishes the model's conversational abilities and ensures it can handle real-world dialogue scenarios.
Why This Progressive Approach Works
The brilliance of this four-stage strategy lies in its gradual complexity scaling. Rather than overwhelming the model with the full task from day one, each stage builds upon the previous one:
- First, establish basic audio-text understanding
- Then, teach single-token prediction
- Next, scale to multiple tokens
- Finally, refine for real conversations
Experimental results show minimal degradation between speech-to-text and speech-to-speech modes, with a performance drop of only 9%. This demonstrates that the training strategy successfully maintains quality while achieving significant speed improvements.
Cross-Modal Intelligence: Understanding Text and Speech Together
One of the fascinating aspects of VITA-Audio is how well it understands the relationship between text and audio. The model shows strong correlations between text tokens and their corresponding audio representations.
Even more impressive? When researchers masked out irrelevant parts of the text, the model still generated appropriate audio. This demonstrates robust cross-modal understanding. The model genuinely "gets" how language and speech connect, rather than just mechanically converting one to the other.
Why This Matters
VITA-Audio isn't just an incremental improvement: it addresses a fundamental bottleneck in conversational AI systems. Here's why it's significant:
1. Natural Conversations
Reduced latency makes interactions feel more natural and human-like. When responses come instantly, users can maintain the flow of conversation without awkward pauses.
2. Real-Time Applications
For use cases like live translation, customer service bots, or accessibility tools, every millisecond counts. VITA-Audio makes these applications more viable and user-friendly.
3. Efficiency at Scale
By accelerating inference without requiring massive computational resources, VITA-Audio makes high-quality voice AI more accessible and cost-effective to deploy.
4. Better User Experience
Let's be honest, nobody likes waiting for technology. Faster response times lead to higher user satisfaction and more engaging experiences.
The Bigger Picture
VITA-Audio represents an important step toward more seamless human-computer interaction. As voice becomes an increasingly important interface for AI systems, solving latency challenges is crucial.
The research demonstrates that with clever architectural innovations like MCTP and thoughtful training strategies, we can make significant performance improvements without sacrificing quality or requiring prohibitive computational resources.
What's Next?
While VITA-Audio shows promising results, there are always exciting directions for future work:
- How does it perform across different languages and accents?
- Can the approach scale to even longer audio sequences?
- What happens when you combine this with other acceleration techniques?
- How does it handle edge cases like background noise or speech disfluencies?
The field of speech AI is evolving rapidly, and innovations like VITA-Audio are pushing the boundaries of what's possible. As these systems become faster and more natural, the gap between talking to an AI and talking to a human continues to narrow.