VGBench: Evaluating Vision-Language Models in Real-Time Gaming Environments

Introduction
Vision-Language Models (VLMs) have achieved remarkable success in tasks such as coding and mathematical reasoning, often surpassing human performance. However, their ability to perform tasks that require human-like perception, spatial navigation, and memory management remains underexplored. To address this gap, the paper titled "VideoGameBench: Can Vision-Language Models complete popular video games?" introduces a novel benchmark aimed at evaluating the real-time interactive capabilities of VLMs in the context of video games.
Benchmark Creation
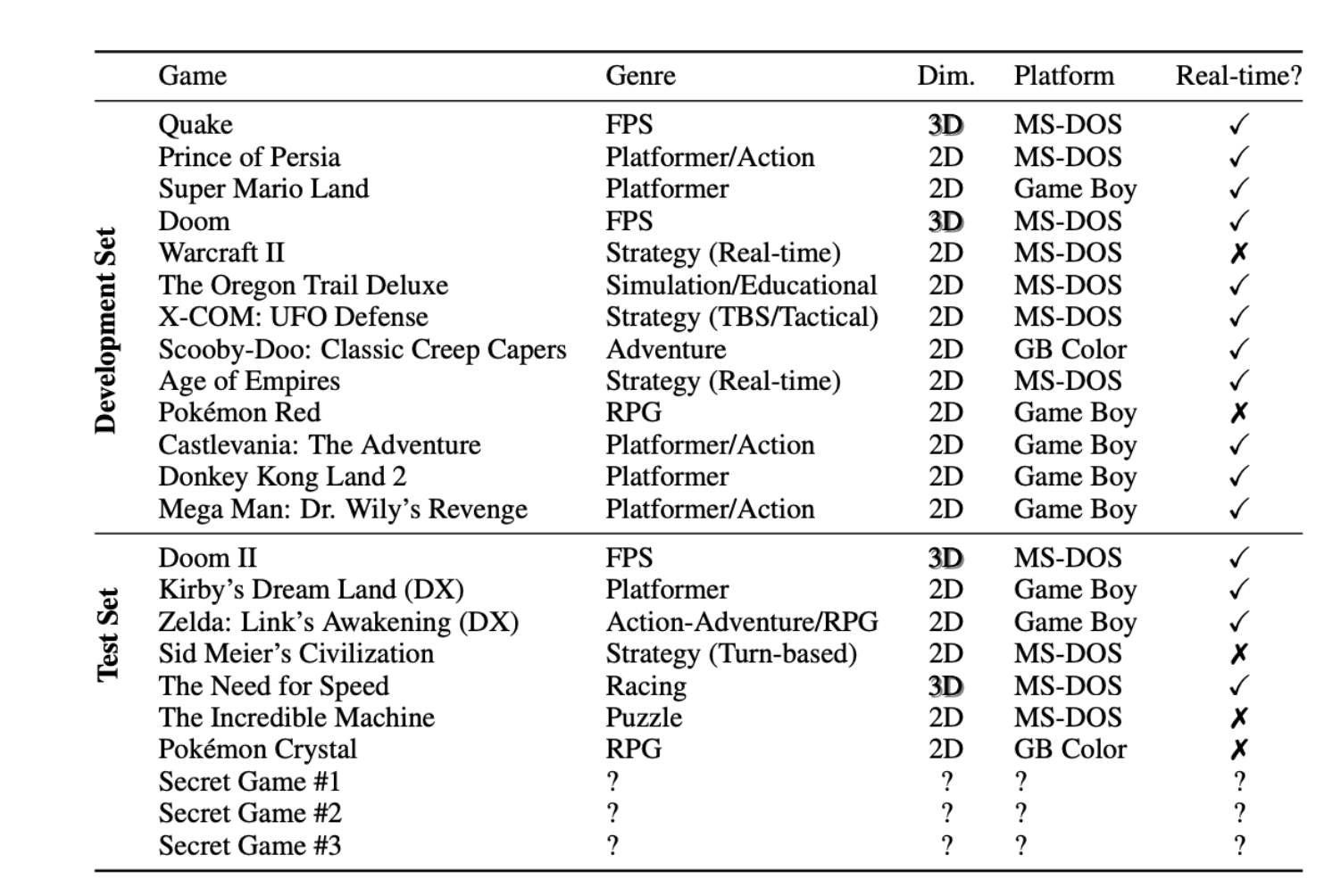
Selection of Games
The authors selected 10 popular video games from the 1990s that were chosen for their complexity and the rich environments they offer, which are designed to leverage human inductive biases. The selection includes both well-known games and three secret games to test the models' ability to generalize across unseen environments.
Evaluation Setup
The benchmark challenges VLMs to complete entire games using only raw visual inputs and high-level descriptions of objectives and controls. This setup ensures that the evaluation reflects the models' intrinsic abilities to interpret and interact with the game world, without any game-specific scaffolding or auxiliary information.
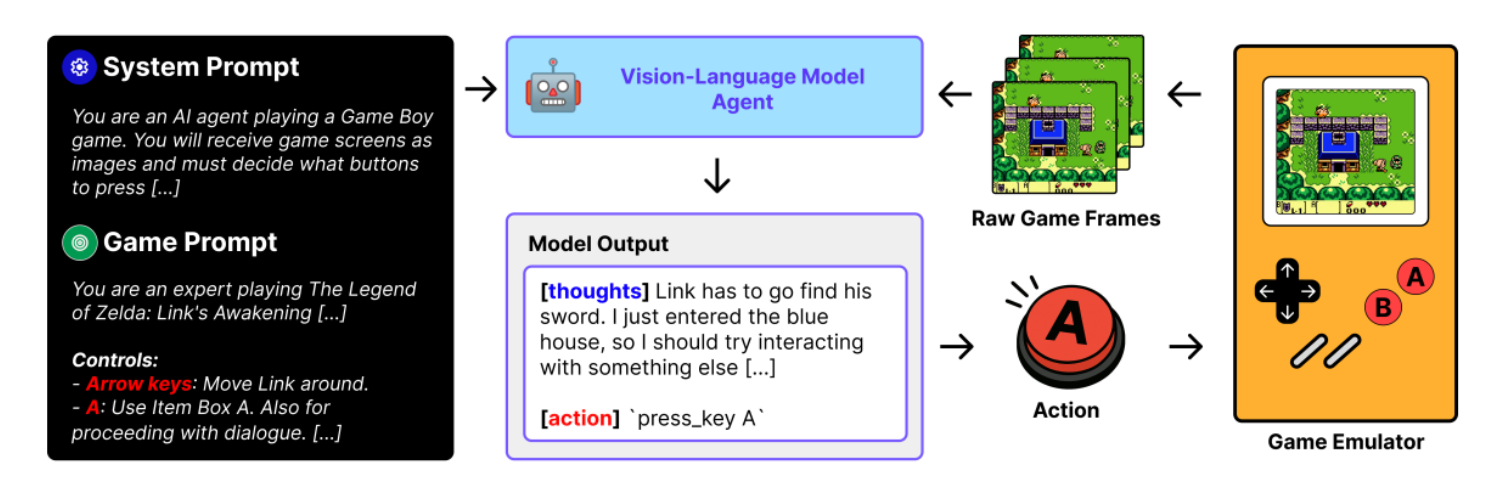
VG-Agent Scaffolding
To facilitate the interaction between models and game emulators, the authors developed the VG-Agent scaffolding. This framework allows for real-time decision-making and action execution, enabling the evaluation of models' performance in dynamic gaming environments.
Model Results
Performance Metrics
The evaluation metrics focus on the models' ability to complete game objectives, navigate complex environments, and manage in-game memory and resources. The results indicate that even state-of-the-art VLMs struggle to progress beyond the initial stages of the games. For instance, the best-performing model, Gemini 2.5 Pro, completes only 0.48% of VideoGameBench and 1.6% of VideoGameBench Lite, where the game pauses while waiting for the model's next action.
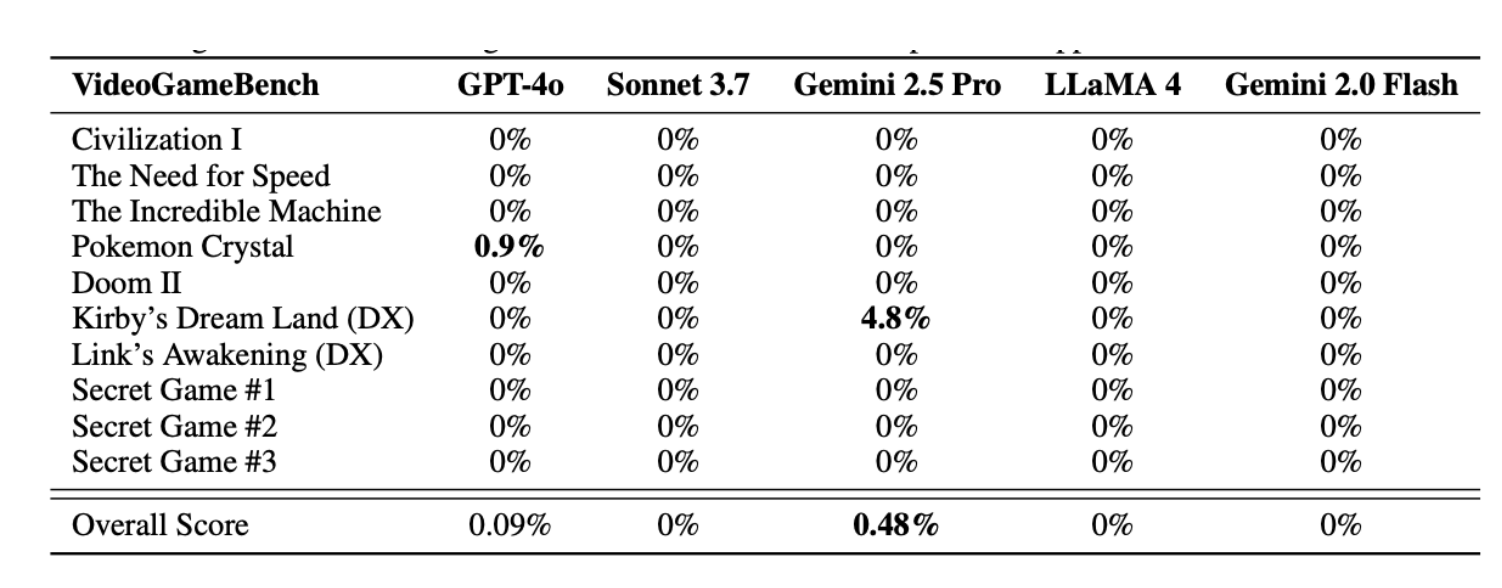
Figure 3: Performance on VGBench test split, a benchmark consisting of 7 games and 3 secret games. Each score is % of the game completed i.e. 0% means the agent did not reach the first checkpoint.
Inference Latency
A significant bottleneck identified is the inference latency of the models. In real-time settings, delays in decision-making can impede the models' ability to respond promptly to dynamic in-game events, affecting overall performance.
Performance in VideoGameBench Lite
In the VideoGameBench Lite setting, where the game pauses to accommodate the model's actions, there is a slight improvement in performance. However, the models still demonstrate limited success, underscoring the need for advancements in real-time processing capabilities.
Observations
Limitations of Current VLMs
The findings suggest that current VLMs require significant enhancements in areas such as real-time processing, memory management, and adaptive decision-making. The limited performance observed highlights the challenges VLMs face in real-time interactive tasks.
Implications for AI Research
The introduction of VideoGameBench serves as a critical step toward bridging the gap between AI models' performance in structured tasks and their ability to handle dynamic, real-world environments. The benchmark provides valuable insights into the capabilities and limitations of current VLMs, guiding future research directions.
Future Research Directions
Future research could focus on:
- Reducing Inference Latency: Optimizing model architectures and inference pipelines to minimize delays and enable real-time interactions.
- Enhancing Memory Management: Developing mechanisms for models to retain and utilize in-game information effectively over extended periods.
- Improving Generalization: Training models on diverse gaming environments to improve their adaptability to unseen scenarios.
Conclusion
VideoGameBench presents a novel and challenging benchmark that pushes the boundaries of current Vision-Language Models. By evaluating models in the context of real-time video game interactions, it provides valuable insights into their capabilities and limitations. The benchmark not only contributes to the advancement of AI research but also paves the way for developing more sophisticated models capable of handling complex, dynamic tasks in real-world settings.
For those interested in exploring the benchmark further, the code and data are available at vgbench.com


