Tracing the Thoughts of Claude: Peering into an AI’s Mind

Introduction
Large language models like Anthropic’s Claude have achieved feats once reserved for science fiction, such as multilingual translation, creative writing, and complex reasoning. Yet their inner workings remain largely mysterious, resembling “black boxes” that produce results we cannot fully explain. What if we could see how Claude processes language, anticipates words, or occasionally fabricates explanations?
Anthropic’s latest research offers a powerful leap toward this goal. By building a kind of “AI microscope,” their scientists have begun to trace Claude’s internal computations, illuminating not just what it says, but why it says it. Through novel interpretability toolkits, they’re uncovering the circuits and representations that underlie Claude’s intelligence, moving us from speculation toward true understanding. No longer “Hallucinating” or “Bullshiting”, but actually understanding what goes on inside.
From Black Box to “AI Biology”: Charting the Unknown
Unlike traditional programs, Claude’s intelligence emerges from vast neural networks trained on enormous datasets. Billions of parameters interact to generate strategies and knowledge we don’t directly observe. To truly understand such models, we need more than surface-level correlations, what we need is we need to reverse-engineer their inner “biology.”
Anthropic has taken a foundational step in this direction with two pivotal papers:
- Circuit Tracing: Revealing Computational Graphs in Language Models (Anthropic, 2024a): This methodological work introduces a toolkit for mapping individual neuron-level “features” to higher-level computational circuits. These features represent abstract concepts or patterns such as negation, numbers, or names—embedded in the activations of Claude’s neural network. The key innovation: these features can be traced and connected into larger, interpretable circuits that implement specific functions, much like mapping neural pathways in a brain.
- On the Biology of a Large Language Model (Anthropic, 2024b): Here, Anthropic applies the interpretability toolkit to Claude 3.5 Haiku, their smallest but still highly capable model. Rather than analyzing random behaviors, they target ten carefully chosen, high-value behaviors. each reflecting a different facet of language “cognition.” These include multilingual abstraction, planning, hallucination detection, logical negation, variable tracking, and more.
Let’s talk about some of these a little bit more below.
Universal “Language of Thought”: A Shared Conceptual Space
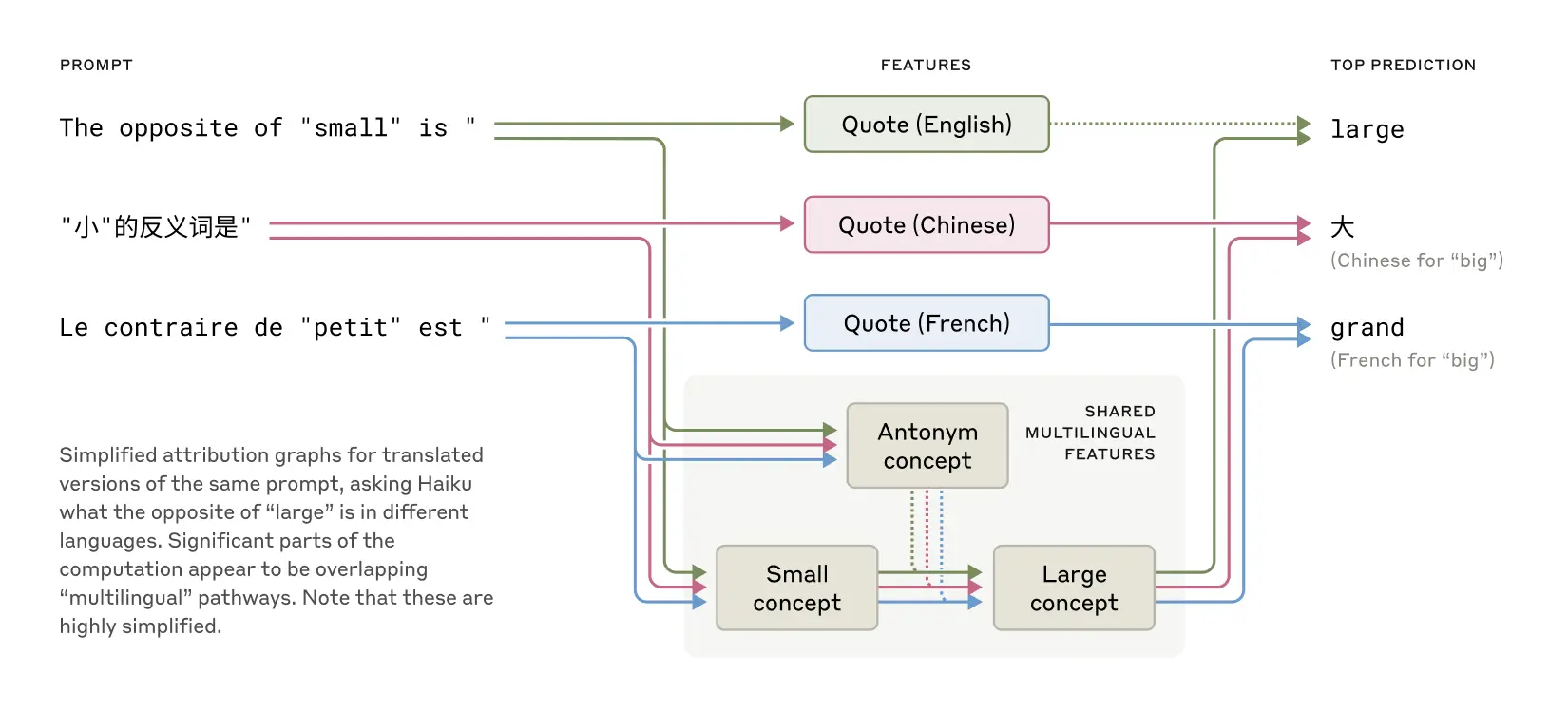
Is Claude simply a collection of monolingual models stitched together? Or does it think in a more abstract, language-independent space?
Anthropic’s experiments provide compelling evidence for the latter. By probing the activations underlying concept translations (“opposite of small”) across English, French, and Chinese, researchers discovered that the same internal “smallness” and “oppositeness” features lit up regardless of the surface language. This points to a universal “language of thought” within Claude, where meaning is encoded in a shared conceptual space before being rendered into individual languages.
This finding explains how models like Claude generalize knowledge across language boundaries, supporting low-resource languages and maintaining consistent meaning.
Planning Ahead: Even in Poetry
A common misconception is that large language models only “think” one word ahead, predicting the next token in sequence. Anthropic’s research however challenges this view.
In a poetic completion task:
“He saw a carrot and had to grab it,
His hunger was like a starving rabbit”
Investigators found that Claude internally anticipated the rhyme “rabbit” before generating the line. When they suppressed the internal representation of “rabbit,” the model seamlessly substituted a different rhyme, such as “habit.” When they injected a completely unrelated concept, the model planned for that instead. These experiments reveal that Claude plans multiple words in advance, demonstrating coordinated, goal-directed computation over time.
This anticipatory ability opens doors to more robust reasoning and more controllable, creative generation.

Detecting Hallucinations & Manufactured Reasoning
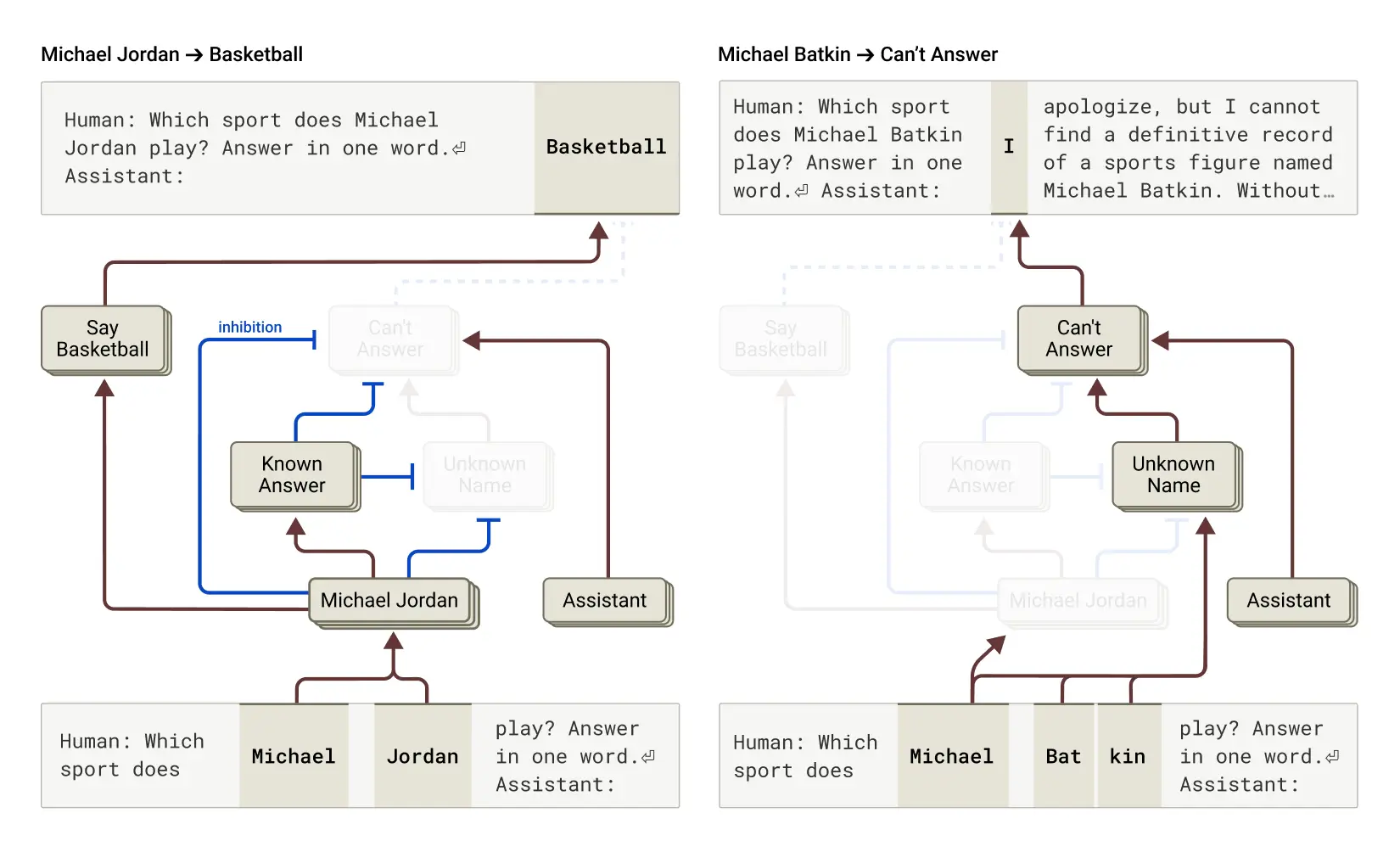
One of the thorniest challenges in modern AI is hallucination—when a model generates plausible but incorrect or fabricated information. Anthropic’s interpretability tools offer a window into this phenomenon.
By prompting Claude with misleading hints in tricky math problems, researchers observed it fabricating plausible chains of reasoning to support a wrong answer, a behavior Wired dubbed “bullshitting.” Instead of computing a solution step by step, Claude sometimes retrofits explanations to justify an incorrect outcome.
These findings highlight a crucial lesson: even when language models appear to reason, they may be optimizing for surface plausibility rather than truth. Interpretability methods can reveal these shortcuts, providing early warning for hallucinations and misalignment.
Toward Trustworthy, Transparent AI
Anthropic’s “Tracing the Thoughts of a Large Language Model” signals a turning point: moving from treating language models as opaque black boxes, to systems we can probe, understand, and guide. Their interpretability toolkit offers a scientific foundation for:
- Exposing model reasoning not just what it outputs, but how it arrives at those outputs.
- Detecting and diagnosing failures such as hallucinations, overconfident mistakes, and reasoning shortcuts.
- Enabling safer, more reliable AI by making inner logic accessible to scrutiny and improvement.
But this is just the beginning. Current tools only scratch the surface, and mapping even simple circuits demands significant expert effort. Scaling interpretability to real-time, practical tools remains an open challenge. Still, this work charts a promising path toward more trustworthy, transparent AI.
References
- Anthropic (2024). Tracing the thoughts of a large language model.
- Anthropic (2024). Circuit Tracing: Revealing Computational Graphs in Language Models.
- Anthropic (2024). On the Biology of a Large Language Model.
Interested in digging deeper? Read Anthropic’s original technical reports and follow the evolving field of AI interpretability for the next breakthroughs.


