The Attention Arms Race: How Modern Open-Source LLMs Are Reinventing the Transformer's Core

Introduction
If you follow the LLM space, you've probably heard a lot about parameter counts, context windows, and benchmark scores. What gets discussed far less often is the mechanism that makes all of it possible: attention. Every major language model (GPT, Llama, Gemini, Qwen, DeepSeek) is built on the Transformer architecture, and at the heart of that architecture is attention.
Since its inception, attention has come a log way. The way attention is implemented varies significantly between today's top open-source models. Meta's Llama 4, DeepSeek V3, MiniMax-M1, and OpenAI OSS all use meaningfully different attention designs. These designs reflect genuine engineering tradeoffs around memory, compute, quality, and context length.
This blog attempts to jot together all these differences in one place, offering you a comprehensive starting point for your attention deep dive. We'll start from first principles and build up to the variants being used in production today.
The Problem You Need to Understand First: The KV Cache
Before we get to attention itself, we need to talk about the KV cache, because it's the constraint that everything else is trying to work around.
Language models generate text one token at a time. When a model generates the next token, it needs to consider every token that came before it. It processes the entire history to decide what comes next.
The naive approach would be to recompute everything from scratch at every step. But that's extremely wasteful. The earlier tokens in the sequence don't change, so why recompute them? The solution is the KV cache: store the intermediate representations (specifically the "key" and "value" vectors, more on these shortly) for all previous tokens, and just compute them for the new token each step.
The problem: this cache grows with every token you generate. For a short conversation, no issue. But for a model supporting 128,000 or 1,000,000 token context windows, the KV cache can occupy more GPU memory than the model weights themselves. A 70 billion parameter model running at 128k context can require well over 100GB just for the cache. This makes long-context inference extremely memory-intensive and expensive.
Every attention variant we'll cover is, in some way, trying to solve this problem: either by shrinking the cache, compressing it, or eliminating it entirely.
Key insight: The KV cache is the main bottleneck in long-context inference. The design of the attention mechanism determines how large it is and how fast it can be accessed.
The Baseline: Multi-Head Attention (MHA)
Let's start with standard Multi-Head Attention. This is the original design from the 2017 "Attention Is All You Need" paper that launched the Transformer era.
Queries, Keys, and Values
Attention works by having each token ask a question about every other token in the sequence. The mechanism uses three vectors for each token:
- Query (Q): "What am I looking for?", the current token's search request.
- Key (K): "What do I offer?", what each token advertises about itself.
- Value (V): "What information do I actually contain?", the substance each token contributes if selected.
You can think of it like a search engine, but a soft one. Rather than returning a single result, attention computes a relevance score between the query and every key in the sequence, converts those scores into weights using softmax, and then produces a weighted blend of all the value vectors.
The result is a new representation of the current token that is now informed by all other tokens, weighted by how relevant each one was. A token processing the word "bank" in the sentence "I deposited money at the bank" will attend heavily to tokens like "money" and "deposited," pulling information from them to resolve the ambiguity.
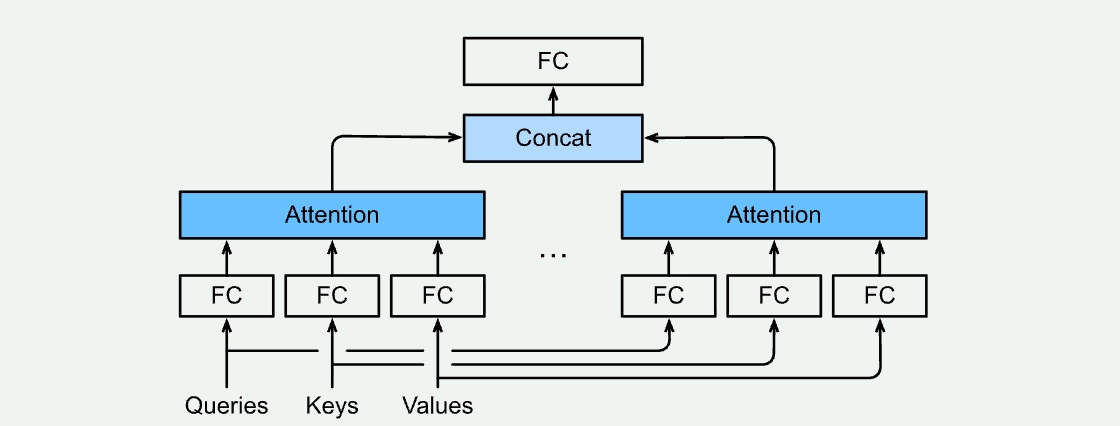
The "Multi-Head" Part
Doing this once is good. Doing it H times in parallel, each in a different representational subspace, is better. That's what "multi-head" means.
Each head learns different weight matrices, so it projects the same token into a different lower-dimensional space before computing attention. In practice, different heads specialize: some track syntactic relationships (which noun does this verb refer to?), some track semantic proximity, some track positional patterns. The outputs of all heads are concatenated and projected back into the original dimension.
The cost of this is that you now have H sets of K and V vectors to cache per token. A model with 64 attention heads has 64x the KV cache of a hypothetical single-head model. For large models with long contexts, this becomes the dominant memory burden.
The Quadratic Scaling Problem
There's a second issue, independent of memory. Because every token attends to every other token, the compute cost of attention scales with the square of the sequence length. Double the context, quadruple the attention computation. At short sequences this is fine; at 100,000+ tokens it becomes a serious bottleneck.
Softmax, the normalization step, requires seeing all scores before computing any of them, which prevents certain kinds of parallelism. This is the root of the O(n²) scaling, and it's what linear attention variants try to address.
Grouped Query Attention (GQA)
Grouped Query Attention is the most widely deployed attention variant in OSS models today. Llama 3, Llama 4, Qwen3, Mistral, and many others all use it as their baseline. It's the "boring but important" one.
The Idea
GQA reduces the KV cache by having multiple query heads share a single set of K and V projections. Instead of each of the H query heads having its own K/V head, you organize the query heads into G groups, and each group shares one K/V head pair.
The full spectrum looks like this:
- Multi-Head Attention (MHA): H query heads, H K/V heads. Full expressiveness, largest cache.
- Grouped Query Attention (GQA): H query heads, G K/V heads (where G < H). Middle ground.
- Multi-Query Attention (MQA): H query heads, 1 K/V head. Smallest cache, most quality degradation.
MQA was proposed first (by Noam Shazeer in 2019) as an aggressive way to shrink the KV cache. It works, but quality suffers noticeably on complex tasks. GQA was introduced as the sensible middle ground: keep enough K/V diversity to maintain quality, but compress enough to get meaningful memory savings.
Concrete Example
Llama 3 70B has 64 query heads and 8 K/V heads. That means 8 groups of 8 query heads each share one K/V pair. The KV cache is 8x smaller than it would be with full MHA, while quality is nearly indistinguishable from MHA on most benchmarks.
This makes GQA particularly valuable at inference time. During training, you're processing entire batches in parallel and the KV cache isn't really the bottleneck. During inference, you're generating token by token and the cache is live in GPU memory throughout, so every byte saved directly reduces memory pressure and improves throughput.
GQA is the industry default because it offers substantial memory savings with minimal quality cost. If a model doesn't specify otherwise, assume it uses GQA.
Multi-Head Latent Attention (MLA)
GQA reduces the KV cache by reducing the number of heads. Multi-Head Latent Attention, introduced by DeepSeek in 2024, takes a fundamentally different approach: instead of reducing the number of heads, it compresses the representations themselves.
MLA is now used in DeepSeek V2, V3, and R1, some of the highest-performing open-source models in the world, as well as Kimi K2 from Moonshot AI. Understanding it is central to understanding why those models have been so competitive.
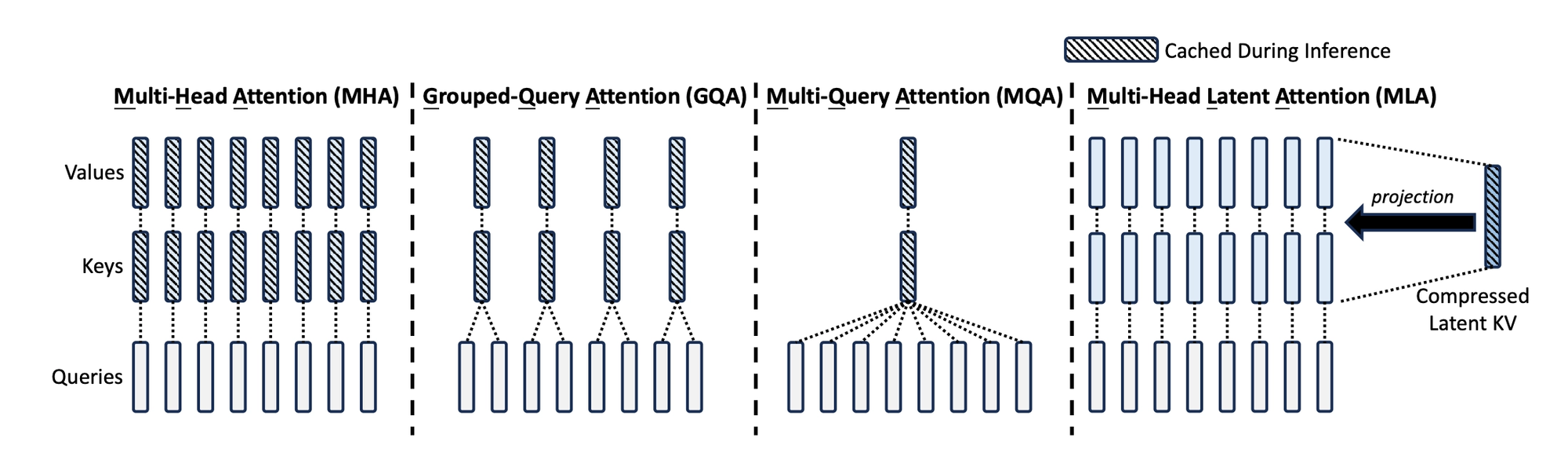
The Core Idea: Latent Compression
In standard attention (including GQA), each token's K and V vectors are computed and cached at their full dimensionality. If the model has a hidden dimension of 7168 (like DeepSeek V3), each K and V vector is a 7168-dimensional vector per head.
MLA instead compresses each token's representation down to a much smaller "latent vector" before generating K and V. You can think of it as finding a compact summary of the token's information. When K and V are actually needed, they're reconstructed from this latent vector.
The critical insight: you only need to cache the latent vector, not the full K and V matrices. Since the latent is much smaller, perhaps 10-15x smaller in dimension, the KV cache shrinks by a corresponding factor. DeepSeek reported roughly 5-13x reduction in KV cache size with MLA compared to standard MHA, depending on model configuration.
Why MLA Outperforms GQA
With GQA, compression comes at the cost of reducing K/V head diversity. You're forcing multiple query heads to use the same key-value pair, which limits how differently each head can attend. With MLA, each head still gets distinct K/V vectors (reconstructed from the shared latent), but the latent bottleneck acts as a regularizing constraint that also happens to be highly compressible for caching.
Empirically, models trained with MLA achieve better benchmark performance than GQA models at similar KV cache sizes. This is why DeepSeek V2's release was such a significant moment. It showed that you could have a smaller KV cache and better quality simultaneously, not as a tradeoff.
Brief Detour #1: Positional Encodings and RoPE
Attention computes relevance purely from content, which means "the cat chased the dog" and "the dog chased the cat" would produce identical attention scores. Position information has to be injected separately.
The original Transformer did this by adding a fixed positional vector to each token's embedding before attention runs, one vector per absolute position. It works, but doesn't generalise well beyond the sequence lengths seen during training.
The field moved toward encoding relative distances instead. Rather than telling a token "you are at position 47," you encode "these two tokens are 12 positions apart." This is more natural for language, where what matters is proximity between words, not where they happen to sit in a document.
RoPE (Rotary Position Embeddings) is the dominant implementation of this idea today. It used in Llama, Qwen, DeepSeek, Mistral, and most other major models. Instead of adding position information to embeddings upfront, RoPE encodes position by rotating the query and key vectors just before the attention dot product. The math works out such that the dot product between any Q and K depends only on their relative distance, not their absolute positions.
RoPE also generalises better to longer sequences than absolute embeddings, which is why models can be fine-tuned to 128k or 1M token contexts from a base trained at 4k. Extensions like YaRN allow the rotations to extrapolate smoothly.
One practical note: MLA has to do extra work to stay compatible with RoPE, since its K vectors are reconstructed from a compressed latent rather than computed directly. This is part of why MLA is more complex to implement than GQA.
The Long-Context Problem
GQA and MLA both help with the memory cost of the KV cache, but they don't address the quadratic compute scaling. Attending to 1 million tokens is still astronomically more expensive than attending to 1,000 tokens. For truly long contexts (think 256k, 512k, 1 million tokens) you need something fundamentally different.
Two main approaches are in production use today: sparse attention (keep softmax, but only attend to a subset of tokens) and linear attention (replace softmax entirely with something that scales linearly).
Sparse Attention: OpenAI's gpt-oss Approach
OpenAI's open-weight gpt-oss models (120B and 20B) use a pattern called alternating dense and sparse attention. Even-numbered layers do standard full attention, ie. every token attends to every other token. Odd-numbered layers do "locally banded" or sliding window attention, basically each token only attending to a fixed window of nearby tokens (128 tokens on either side).
The intuition is that different kinds of reasoning require different attention patterns. Local layers handle nearby context including grammar, short-range dependencies, phrase-level relationships. Global layers handle long-range dependencies such as coreference, document-level themes, distant references. By alternating, you get both capabilities at roughly half the average compute cost of pure full attention.
This design has a clean lineage. The Longformer (2020) introduced a similar pattern with local windowed attention plus a small set of global tokens (special tokens that attend to everything). OpenAI's version simplifies this by just alternating full layers instead of having a hybrid within a single layer. It maps cleanly onto standard hardware and is easy to implement with FlashAttention (more on that in a bit).
The tradeoff: long-range information can only propagate through the global layers. For very hard reasoning that requires tight integration of distant context, you're depending on those full-attention layers to do heavy lifting.
Linear Attention: The MiniMax Approach
MiniMax-M1 takes a more radical approach to long context. It uses a hybrid architecture mixing standard softmax attention in some layers with a mechanism called Lightning Attention in others. Lightning Attention is different from other variants in one big way, it is fundamentally linear instead of being quadratic.
To understand why this matters, consider what makes softmax attention quadratic. The softmax normalization step requires computing all relevance scores before normalizing any of them, you need the full row in memory before you can divide. This means you can't process tokens incrementally; you need the whole sequence present at once.
Linear attention replaces the softmax with an approximation that can be factored differently. Instead of computing the n×n attention matrix and then multiplying by V, you rearrange the computation to first multiply K and V (producing a small matrix), then multiply Q by that. This accumulated matrix can be updated incrementally as new tokens arrive, making the whole operation O(n) rather than O(n²).
The recurrent framing is intuitive: that accumulated matrix is essentially a hidden state, like in an RNN. Linear attention is mathematically equivalent to a recurrent neural network since it compresses the entire history into a fixed-size state, rather than keeping explicit per-token representations. This is both its power (fixed memory cost regardless of sequence length) and its weakness.
The Linear Attention Quality Gap
Softmax attention can produce very "sharp" distributions. A token can attend almost exclusively to one or two highly relevant tokens while ignoring everything else. This selective retrieval is crucial for tasks like "what was the person's name mentioned at the start of this document?". Think standard needle in the haystack problems.
Linear attention kernels produce much smoother, more diffuse attention distributions. The fixed hidden state averages information together in a way that makes exact retrieval hard. On straightforward text generation, the quality gap is manageable. On tasks requiring precise lookup of specific information from long contexts, standard softmax attention is noticeably better.
This is why MiniMax-M1 is a hybrid: linear attention layers handle the bulk of long-range context processing efficiently, while regular softmax attention layers handle the sharp retrieval that linear attention struggles with.
Gated DeltaNet: The Qwen3 Next Approach
Qwen3 Next (the 80B MOE model) uses a different hybrid: Gated DeltaNet layers mixed with standard Gated Attention layers in a 3:1 ratio.
DeltaNet improves on basic linear attention using the "delta rule", an idea borrowed from associative memory theory. When new information arrives that conflicts with what's already stored in the hidden state, the model first erases the conflicting old entry before writing the new one. This selective forgetting mechanism partially recovers the sharp retrieval ability that softmax attention has naturally, without requiring per-token storage.
The result is a model that supports a 262k token native context window without the KV cache growing unboundedly, because the DeltaNet layers have fixed-size state. The softmax layers provide the retrieval precision where it's needed most.
The long-context frontier is where architecture choices diverge most sharply. Sparse attention keeps softmax but skips most tokens. Linear attention hybrids replace softmax in most layers with recurrent-style mechanisms that have fixed memory cost.
Brief Detour #2 : FlashAttention
FlashAttention isn't an attention variant. It's an implementation technique that makes all of the above actually fast in practice. It's worth knowing about because you'll see it referenced everywhere.
The bottleneck in attention on a GPU isn't the number of floating-point operations but the memory bandwidth. The naive implementation computes the full n×n attention score matrix and writes it to the GPU's main memory (HBM), then reads it back to apply softmax, then writes it again, then reads it again to multiply by V. For long sequences, this back-and-forth is extremely slow even if the GPU is capable of the arithmetic.
FlashAttention eliminates most of these memory round-trips by computing attention in tiles that fit entirely in the GPU's fast on-chip SRAM. It uses a mathematical trick to compute the correct softmax-normalized output without ever needing the full n×n matrix in memory at once. The result is the same output as standard attention, but 2-4x faster and with much lower peak memory usage.
Almost every model you'll encounter today uses FlashAttention or a derivative. It's not a choice you make about your model's architecture, it's just a correct implementation of whatever attention mechanism you've chosen.
How to Think About the Tradeoffs
Now that we've covered the main mechanisms, let's build a mental framework for when each approach makes sense. There are three axes that matter:
- Quality: Does the attention mechanism preserve the model's ability to reason over context? Full softmax MHA sets the ceiling. Every variant involves some approximation.
- KV Cache Size: How much memory does inference require? This determines what batch sizes and context lengths you can serve on a given GPU.
- Compute Scaling: How does the cost grow with sequence length? Quadratic (standard softmax) vs. linear (recurrent/linear attention) vs. something in between (sparse).
No current mechanism dominates on all three simultaneously. That's why there are multiple designs in production.
GQA wins on simplicity and quality preservation. It does nothing about compute scaling (still quadratic) and achieves moderate KV cache reduction. The right choice when context lengths are moderate and you want predictable behaviour.
MLA wins on KV cache efficiency at high quality. Still quadratic compute. The right choice when you're willing to accept architectural complexity in exchange for better quality-per-memory-byte at inference.
Sparse/alternating attention wins on compute efficiency without quality degradation. Still requires the KV cache to grow. The right choice when context is long but you need reliable retrieval over the full window.
Linear attention hybrids win on memory scaling for extreme contexts. Fixed-size state means memory doesn't grow with sequence length. The cost is potential quality degradation on sharp retrieval tasks. The right choice when 512k+ context windows are the core use case.
| Mechanism | Key Models | KV Cache | Compute Scaling | Quality |
|---|---|---|---|---|
| GQA | Llama 3/4, Qwen3, Mistral | Medium | O(n²) | Near-MHA |
| MLA | DeepSeek V3/R1, Kimi K2 | Small | O(n²) | Better than GQA |
| Alternating Dense + Sparse | OpenAI gpt-oss | Medium | Sub-quadratic | Near-MHA |
| Lightning Attention (Hybrid) | MiniMax-M1 | Fixed | O(n) | Good, gaps on retrieval |
| Gated DeltaNet (Hybrid) | Qwen3 Next | Fixed | O(n) | Good, gaps on retrieval |
What's Next
The attention landscape is moving fast. A few open questions that will shape how this evolves:
Will MLA become the new GQA? GQA achieved omnipresence because it was simple, effective, and easy to implement. MLA is more complex as the RoPE decoupling and latent projection require careful engineering. But its quality-per-memory advantage is substantial, and Kimi K2's adoption suggests MLA is spreading beyond DeepSeek's own models.
Will linear attention close the quality gap? DeltaNet and similar innovations are genuinely narrowing the retrieval precision gap between linear and softmax attention. If future work closes it further, we could see linear attention replace softmax in most layers across the board instead of just in specialized long-context models.
How much does hardware shape architecture? Export controls mean many China-based labs are building for H20s and A800s rather than H100s. This has pushed research toward architectures that are more memory-bandwidth-efficient. As the hardware landscape diverges geographically, attention designs may diverge with it.
What does 10M token context look like? MiniMax's 1M context and Qwen3 Next's 262k are impressive, but the trajectory points toward even longer windows. At those scales, even linear attention has practical bottlenecks as the fixed hidden state has finite capacity. The next generation of long-context architectures may require rethinking the state design entirely.
Conclusion
The Transformer architecture, proposed in 2017, hasn't been replaced but the attention mechanism inside it looks very different depending on which lab built the model you're running.
GQA is the pragmatic default: simple, effective, and widely adopted. MLA is the current frontier for inference efficiency: more complex, but demonstrably better at the quality-per-memory tradeoff. Sparse and linear attention hybrids are the answer to truly long contexts, each accepting different quality tradeoffs in exchange for different efficiency gains.
Understanding these distinctions matters for more than intellectual curiosity. If you're evaluating which model to deploy, the attention design directly affects what hardware you need, what context lengths are feasible, and where the model might degrade on hard retrieval tasks. If you're building systems on top of these models, knowing why a model supports 1M tokens and what it gives up to do so helps you use it correctly.
The attention arms race isn't over. But if you've read this far, you now have the conceptual vocabulary to follow it as it develops!
References & Further Reading
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (2024)
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints — Ainslie et al. (2023)
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning — Dao (2023)
- Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention — Katharopoulos et al. (2020)
- MiniMax-M1 Technical Report (2025)
- Qwen3 Technical Report (2025)


