SuperBPE: Rethinking Tokenization for Language Models

In the domain of language models, tokenization i.e. the process of breaking down text into manageable units plays a pivotal role. Traditionally, models rely on subword tokenization, where words are split into smaller units. However, this approach often overlooks the semantic significance of multi-word expressions and varies across languages. A new method titled SuperBPE is a novel tokenization strategy introduced in the paper SuperBPE: Space Travel for Language Models, which aims to enhance encoding efficiency and model performance by reimagining how text is tokenized.
The Problem with Traditional Tokenization
Most language models utilize subword tokenization methods like Byte Pair Encoding (BPE), which segment text into subword units based on frequency. While effective, this method has limitations:
- Whitespace Dependency: BPE relies on whitespace to determine token boundaries, which isn't consistent across languages.
- Multi-Word Expressions: Phrases like "by the way" or "New York City" are semantically single units but are tokenized into separate parts, potentially diluting their meaning.
- Cross-Linguistic Variations: Languages like German or Chinese have different word boundary conventions, making whitespace-based tokenization less effective.

Introducing SuperBPE
SuperBPE addresses these challenges by extending the BPE algorithm to learn superword tokens that are multi-word units that often carry singular semantic meaning. The approach involves a two-phase pretokenization curriculum:
- Subword Learning: Initially, the model learns subword units as in traditional BPE.
- Superword Learning: Subsequently, the model identifies and learns frequent multi-word expressions, allowing tokens to span across whitespace boundaries as can be seen in Fig 1.
This strategy enables the tokenizer to capture more meaningful units of language, improving both efficiency and comprehension.
Performance Highlights
The authors conducted extensive experiments to evaluate the method’s effectiveness using the OLMo 2 7B training configuration:
- Encoding Efficiency: With a fixed vocabulary size of 200k, SuperBPE reduced the number of tokens needed to represent text by up to 33% compared to traditional BPE.
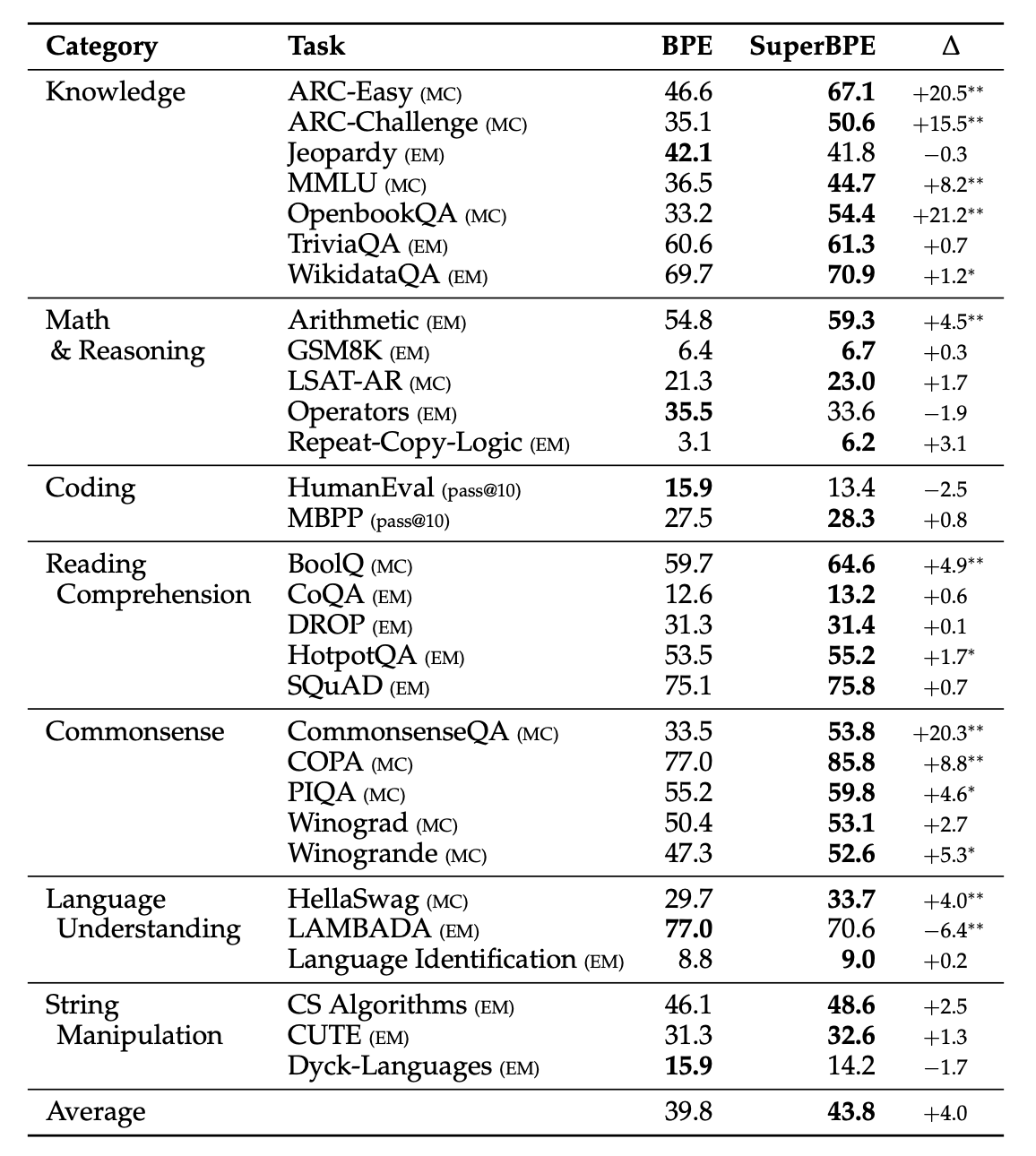
- Model Performance: An 8B-parameter transformer model trained with SuperBPE outperformed its BPE counterpart by an average of 4.0% across 30 downstream tasks, including an 8.2% improvement on the MMLU benchmark.
- Inference Efficiency: Models using this tokenization required 27% less compute during inference, highlighting its practical benefits.
Interestingly, SuperBPE tokenizers scaled better with vocabulary size as compared to BPE which hits a point of diminishing returns adding rare subwords to the vocabulary. SuperBPE on the other hand continues discovering common word sequences which can be a single token thus improving encoding efficiency.
Why SuperBPE Works
The success of the method relies on its ability to create tokens that align more closely with human language understanding:
- Semantic Coherence: By treating common phrases as single tokens, the model better captures their intended meaning.
- Uniform Token Difficulty: Analysis showed that SuperBPE produced tokens with more uniform per-token difficulty, aiding in model training and inference.
- Language Agnostic: The approach is beneficial across languages, especially those without clear word boundaries.
Implications and Future Directions
SuperBPE challenges the conventional wisdom of subword tokenization, demonstrating that extending the BPE algorithm to superword tokens can lead to significant improvements in model efficiency and performance. This approach opens avenues for more nuanced language understanding and could be particularly impactful in multilingual and low-resource settings.
As language models continue to evolve, ideas like SuperBPE highlight the importance of reevaluating foundational components to unlock new potentials.
For a deeper dive, refer to the full paper: SuperBPE: Space Travel for Language Models.


