Streaming Speech Synthesis Without the Trade-offs: Meet StreamFlow

The last few years of neural speech synthesis have been wild. Flow matching models, diffusion transformers, and insanely natural TTS systems keep raising the bar. The catch? Most of these models expect to see the whole audio sequence at once . While this is great for offline generation, but if you’re trying to build real-time speech? Not so much.
So if you want instant responses (like in assistants, voice agents, or anything streaming), the current state-of-the-art architectures start to fall apart. They’re accurate but slow, memory-hungry, and definitely not designed for low-latency streaming.
Streamflow is a new take on diffusion-based speech synthesis built specifically for real-time generation without sacrificing audio quality. And the magic ingredient is a clever attention masking strategy that lets the model generate speech one chunk at a time while keeping prosody smooth and natural.
Why Diffusion Speech Models Struggle With Streaming
Most high-quality speech generators today follow the same pattern: start with noise, refine it over multiple diffusion steps, and transform it into speech. It works great when the model has full-sequence visibility and unlimited compute.
But:
- Self-attention scales O(N²) with sequence length
- Global receptive fields require full input context
- Streaming demands low, predictable latency
People tried chunking or purely causal masking but chunking causes awkward discontinuities, and causal-only attention often makes speech sound robotic or flat. Streaming-friendly quality needs a middle ground.
The Key Insight: Block-Wise Guided Attention
StreamFlow solves the streaming problem by breaking the sequence into blocks and controlling how much past and future context each block can see.
Each block gets:
- A backward window to maintain historical consistency
- A small forward window to anticipate upcoming prosody
A bounded receptive field to keep compute predictable
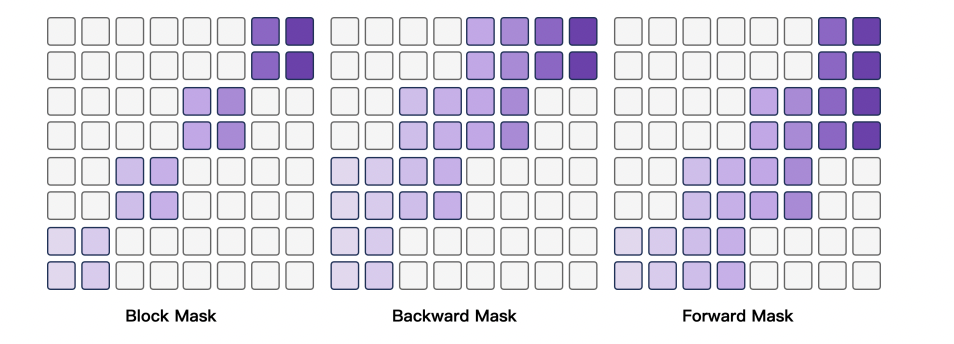
Three parameters define the attention shape:
| Parameter | Meaning |
|---|---|
| B | Block size |
| W_b | Historical context blocks |
| W_f | Future context blocks |
This creates a sliding window attention pattern. Instead of full self-attention complexity O(N²), we get something closer to O(B x W x N)
Much more manageable, and crucially, latency stays constant even for long-form speech.
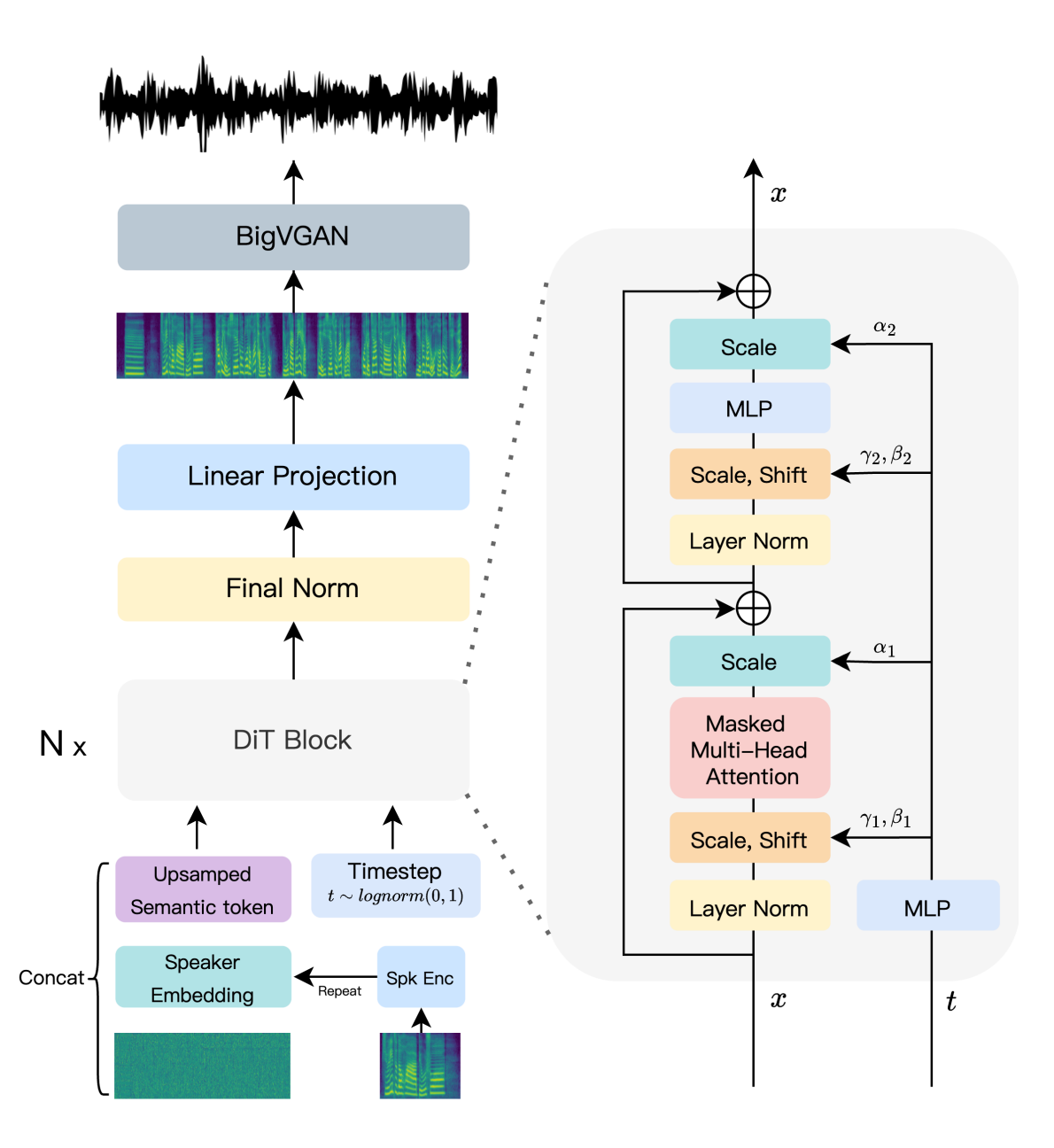
Architecture Overview
StreamFlow is still based on a Diffusion Transformer (DiT), but with modifications for streaming:
- Speech tokens and speaker embeddings feed into a learned continuous latent space
- Positional encodings preserve order within blocks
- Diffusion timesteps are injected with AdaLN conditioning
- The final network predicts mel-spectrograms
Training happens in two phases:
- Full-attention training : the model learns quality, prosody, and global structure
- Block-wise fine-tuning : the model adapts to streaming constraints without forgetting quality
Does It Actually Work in Real-Time?
Pretty well, and better than expected!
First-packet latency clocks in at ~180ms, made of:
- ~80ms model inference
- ~60ms vocoder (BigVGAN)
- ~40ms runtime overhead
After that, latency per block stays constant. There is no growth with sequence length.
Quality metrics also barely budge compared to full-attention diffusion:
- Speaker similarity: within ~2%
- F0 / prosody continuity: preserved
- Block boundaries: imperceptible with small overlap + cross-fade
Human listeners in MOS tests couldn’t reliably distinguish StreamFlow output from non-streaming models (as long as window sizes were tuned reasonably).
What Matters Most: Windows and Block Size
Some practical takeaways from ablations:
- Past context helps a lot until around W_b ≈ 3; after that, gains taper.
- A little future look-ahead goes a long way. Even
W_f = 1dramatically improves naturalness. - Block size matters: ~0.4–0.6s per block hits the sweet spot between responsiveness and stability.
Implementation Notes
A few small engineering choices make a big difference:
- Overlapping blocks with 10–20% cross-fade prevent audible seams
- Hann-style blending smooths transitions
- Speaker embeddings are computed once and reused for the whole stream
- BigVGAN running in parallel finishes waveform synthesis on time
How It Stacks Up Against Other Approaches
| Method | Streaming-Ready? | Audio Quality |
|---|---|---|
| Autoregressive TTS | Yes | Medium |
| GAN-based | Yes-ish | Inconsistent |
| Causal diffusion | Yes | Noticeable degradation |
| StreamFlow | Yes | Near-SOTA |
StreamFlow ends up in a very attractive middle ground: the responsiveness of streaming systems with the polish of diffusion-based speech generators.
What’s Next?
Future work could make streaming speech synthesis even better:
- Prosody-aware adaptive block sizing
- Sparse hierarchical attention for long-range global cues
- Fully end-to-end joint training with the vocoder
- Dynamic window adjustment based on compute or network latency
Final Thoughts
StreamFlow shows that we don’t need to throw away powerful diffusion-based TTS models to achieve real-time speech. Instead, we just need to shape their attention patterns to match streaming constraints.
The broader takeaway:
If a sequence model only needs local structure, the attention should be local — but not blindly causal.
This kind of architecture could easily extend beyond speech: music generation, live translation, interactive video synthesis: any place where quality matters, but waiting for the full input isn’t an option.
Paper: StreamFlow: Streaming Flow Matching with Block-wise Guided Attention Mask for Speech Token Decoding