Semantic Highlighting: Making RAG Cheaper Without Compromises

Recent research from the Zilliz team tackles a problem that shows up constantly in production RAG systems: how do you actually show users why a document is relevant to their query?
Consider a typical scenario. A user asks: "How can I speed up my Python code?" The vector database retrieves a relevant document about performance optimization. Traditional highlighting marks the words "Python" and "code" in yellow. Meanwhile, the actual answer, "replace your for-loops with NumPy vectorized operations", remains unhighlighted because it contains none of the query terms.
This is the fundamental limitation of keyword-based highlighting, and it's more consequential than it might seem.
The Hidden Cost of Traditional Highlighting
This isn't just a UX issue. In most production RAG systems, chunking is semantically naive. Thus, systems retrieving 10+ documents per query, each potentially thousands of tokens long, means processing tens of thousands of tokens. Only a handful of sentences in that text typically contain useful information.
The rest creates several problems:
- Token costs that add up quickly
- Model confusion (more context doesn't mean better answers)
- Debugging difficulties when trying to figure out which chunks were actually relevant
What's needed is a way to surgically extract just the sentences that semantically answer the query, even when they use completely different words.
Enter Semantic Highlighting
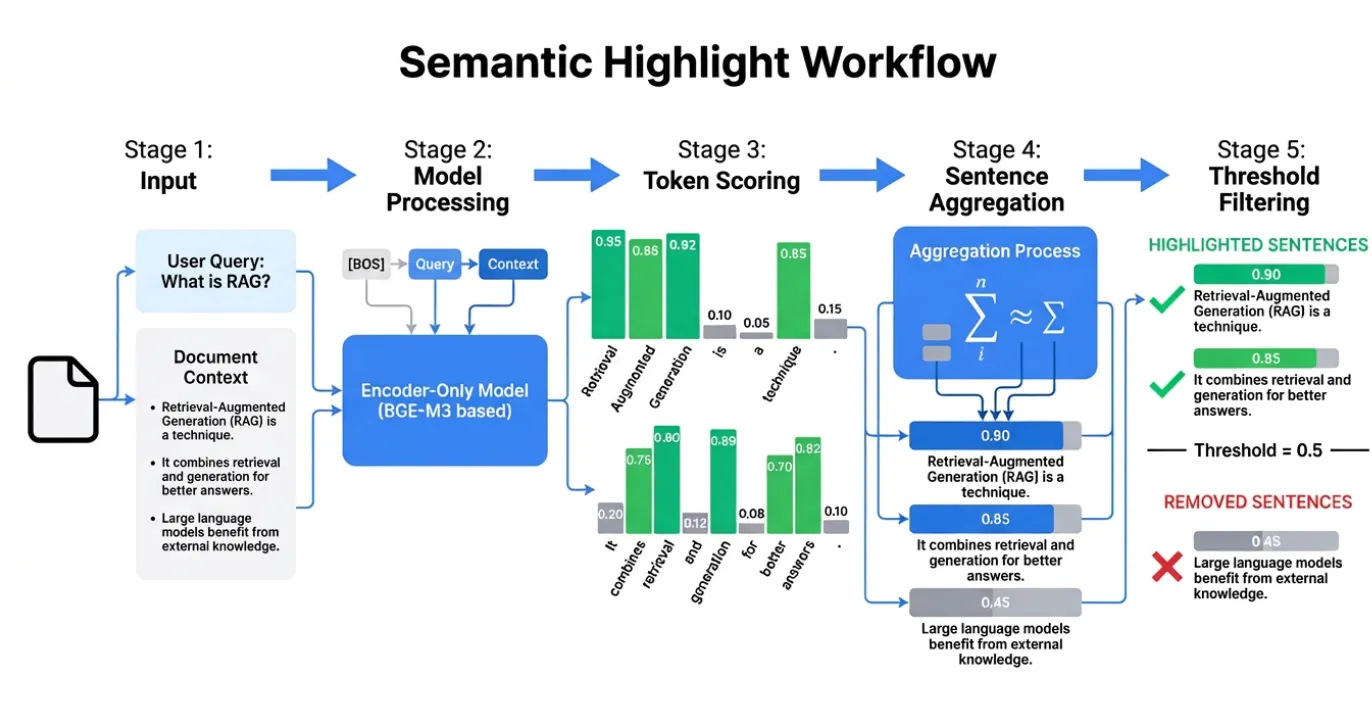
The Zilliz team trained a specialized model that does exactly this. Instead of matching keywords, it understands meaning. When a user asks about "iPhone performance," it correctly highlights passages about "A15 Bionic benchmarks" and "smooth, lag-free experience", even though these phrases share zero words with the query.
The approach is elegant:
- Use a lightweight encoder model (0.6B parameters)
- Train it to score each sentence based on semantic relevance
- Highlight high-scoring sentences, discard the rest
What's particularly interesting about their training methodology is that they had an LLM (Qwen3 8B) output its complete reasoning process during annotation. This "explain before labeling" approach significantly improved annotation quality: essentially building in a self-verification step where the model explains its logic before committing to labels.
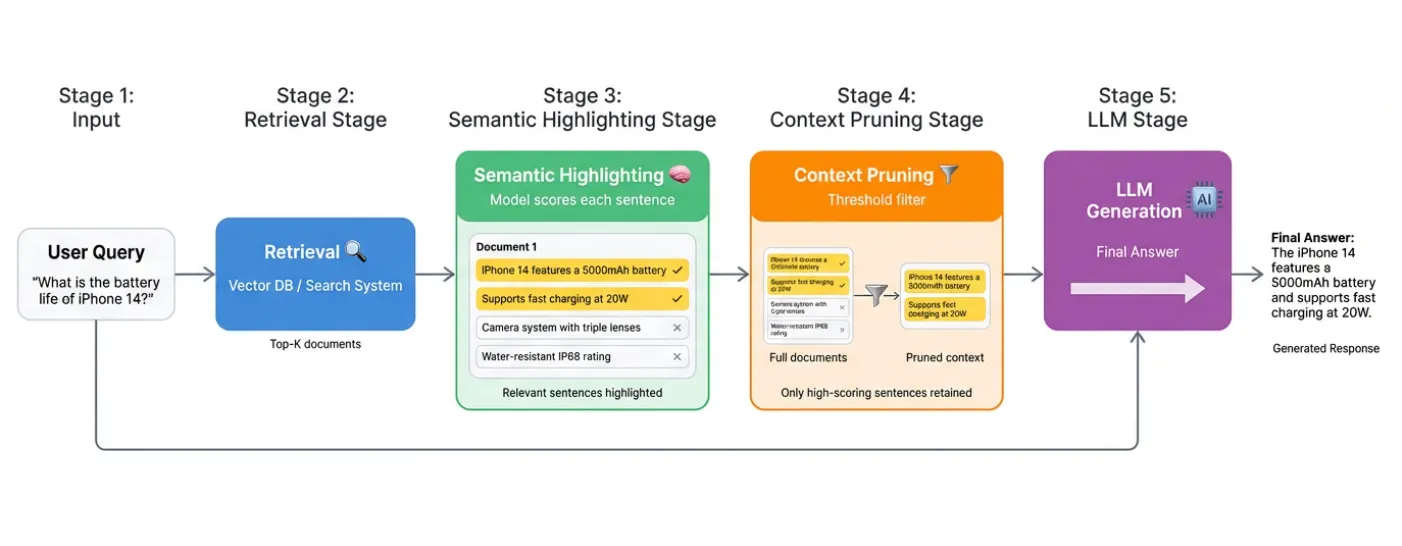
Why This Matters in Production
The practical implications are substantial:
Token Cost Reduction: They're reporting 70-80% reduction in tokens sent to the LLM. That's not just cost savings, it's faster responses and the ability to handle more queries with existing infrastructure.
Answer Quality: When the LLM processes only relevant sentences instead of full documents with lots of noise, answer quality improves. The signal-to-noise ratio increases significantly.
Debuggability: Semantic highlighting provides actual visibility into retrieval decisions. Instead of vague "high cosine similarity" explanations, you can see exactly which sentences matched the query and why.
Agent Workflows: This becomes particularly valuable in AI agent systems. When agents decompose complex tasks into multiple search queries, those derived queries often look nothing like the source documents. Semantic highlighting can bridge this semantic gap.
Key Implementation Details
Several technical decisions make this work in production:
Base Model Selection: Starting with BGE-M3 Reranker v2 was a smart choice. It already provides strong multilingual understanding and an 8K token context window. Why reinvent the wheel when you can fine-tune something that's already good at relevance scoring?
Bilingual Performance: Most existing solutions either support only English or show degraded performance in multilingual settings. This model achieves state-of-the-art scores on both English and Chinese benchmarks through balanced bilingual training data (nearly 5 million samples split evenly between languages).
Inference Speed: The encoder-only architecture (think BERT-style) enables parallel scoring of all sentences, maintaining latency in the millisecond range: fast enough for production search systems.
Open Source: Released under MIT license with the full training dataset, so you can actually use this in production without license headaches.
A Case Study in Semantic Understanding
The research includes an example that nicely demonstrates the difference between keyword matching and semantic comprehension:
Query: "Who wrote the film The Killing of a Sacred Deer?"
The retrieved text mentions two potential "authors":
- Sentence 1: The screenplay writers (Lanthimos and Filippou)
- Sentence 3: Euripides (who wrote the ancient Greek play the film is based on)
Keyword-based systems get confused by "wrote" appearing near "Euripides" and incorrectly highlight the wrong answer. Semantic highlighting correctly identifies that the question asks about the film's writers, not the source material from thousands of years ago.
The scoring tells the story:
- Semantic highlighting model: 0.915 for the correct sentence, 0.719 for the distractor
- XProvence baseline: 0.947 for the distractor, 0.133 for the correct answer
That's the difference between understanding context and just matching words.
Potential Applications
Semantic highlighting addresses several real-world use cases:
- Product search: Surface the exact part of product descriptions that matches user needs
- Document QA: Direct users to the relevant paragraph, not just "page 47"
- Research tools: Help users quickly scan papers by highlighting only pertinent findings
- Compliance/legal: Pinpoint exact clauses in contracts or regulations
The Zilliz team is working on integrating this directly into Milvus as a native API, which makes sense since semantic highlighting shouldn't be something you bolt on afterward.
The Broader Context
This work addresses a production problem that's been largely overlooked. We've gotten pretty good at semantic search. But the next step of showing users where in those documents the answer exists has received less attention.
The combination of semantic search and semantic highlighting creates a more complete pipeline:
- Search: "Which documents contain the answer?"
- Highlight: "Where exactly in those documents?"
- LLM: "Here's the synthesized answer" (using only highlighted sections)
This approach provides better observability at each stage of the retrieval process.
Getting Started
For teams working on RAG systems facing similar challenges, the model is available on HuggingFace: zilliz/semantic-highlight-bilingual-v1
The training data is also open-sourced, which is helpful for understanding their approach or training specialized versions for specific domains.
The model's size allows deployment alongside existing search infrastructure without significant overhead, and early testing suggests notably improved highlighting quality compared to keyword matching or simple reranking approaches.
Conclusion
Not every ML research project translates cleanly to production systems. This one does. The problem is well-defined, the solution is deployable, and the licensing enables commercial use.
For teams building RAG systems, semantic highlighting offers measurable benefits in token efficiency and UX. If you haven't thought about semantic highlighting yet, it's worth exploring: the token savings alone might justify the effort.
Model and technical details: HuggingFace Model Card | Technical Blog


