PersonaPlex: Full-Duplex Voice Without the Fixed Persona

Introduction
Voice AI hit a genuine inflection point when full-duplex models arrived. Systems like Moshi finally cracked the core problem with conversational speech: the awkward cascade of listen, then transcribe, then think, then speak. Full-duplex models [models that listen and speak simultaneously over a continuous audio stream, the same way humans do in real conversation, rather than taking strict turns] collapse all of that into a single continuous process, handling interruptions and backchannels naturally. The result is conversations that actually feel like conversations. But there's a catch. These models shipped with exactly one personality and exactly one voice, which makes them impressive demos and very limited products. You can't run a customer service platform on a model that sounds the same and acts the same regardless of context.
NVIDIA's PersonaPlex, from the team led by Rajarshi Roy, takes direct aim at this constraint. It builds on the Moshi architecture but adds something Moshi never had: a hybrid conditioning system where you supply both a voice sample and a text-based role prompt before the conversation starts. The model locks onto that persona and holds it across the entire exchange, including through interruptions, backchannels, and mid-sentence barge-ins. That combination, natural duplex dynamics with actual persona control, is what separates PersonaPlex from everything that came before it. And the numbers make the gap hard to argue with.
The Problem with Fixed-Persona Duplex Models
It's worth being precise about what the limitation actually was, because it matters for understanding what PersonaPlex changes.
Earlier pipeline-based voice systems (ASR to LLM to TTS) were flexible. You could swap system prompts, change voices, instruct the model to play a medical intake agent or a bank customer service rep. The problem was latency and naturalness. Each stage added delay, and the whole thing collapsed under overlapping speech. Cascaded systems can't handle interruptions without awkward dead air because they're fundamentally turn-based.
Moshi solved the turn-taking problem with a unified architecture: it encodes incoming audio into discrete tokens via a neural codec (Mimi), runs those tokens through stacked Temporal and Depth Transformers alongside the model's own output tokens, and decodes back to speech, all in one continuous forward pass. There's no transcript, no separate language model call, no TTS stage. Everything happens in a single stream, which is why it can respond in real time and react to what you're saying mid-sentence. But that architectural tightness is also exactly why it couldn't support flexible personas. Conditioning on arbitrary voice and role prompts in a continuous streaming setup is genuinely hard. The model has to integrate both acoustic and linguistic signals frame by frame, with no batch processing and no re-reading. Most teams solved this by training a single persona deeply and shipping that.
The practical consequence is that full-duplex models were fine for generic assistant use cases and essentially unusable for anything else. A medical intake agent that sounds exactly like a tech support bot is not a deployable product.
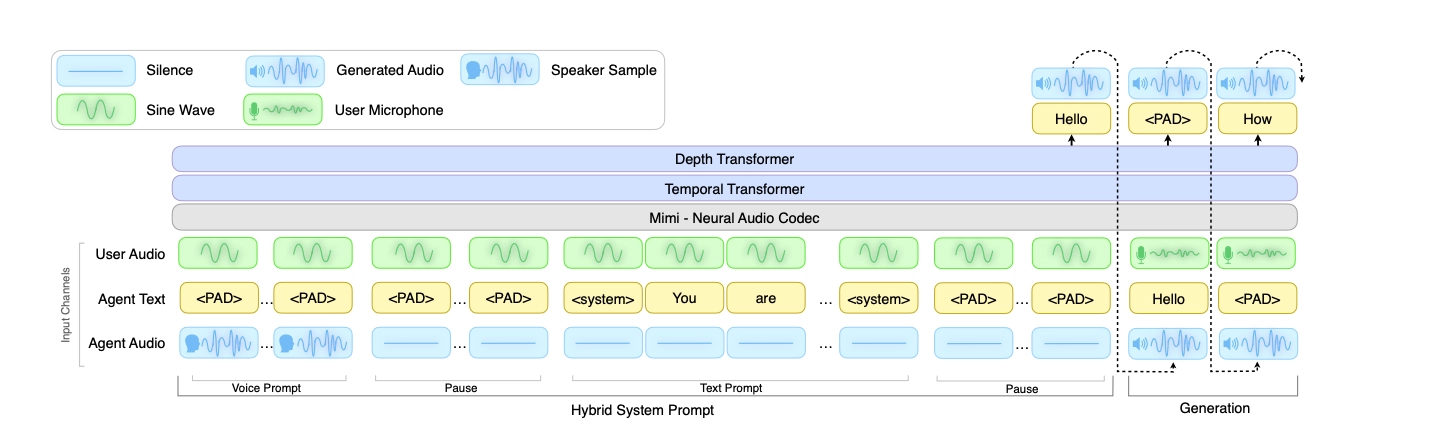
How PersonaPlex Conditions on Both Role and Voice
PersonaPlex's main move is the hybrid system prompt. Before a conversation begins, the model receives two inputs: a text prompt describing the role, and a short audio sample establishing the voice.
The text prompt handles who the model is and how it should behave. This can be as terse as "You enjoy having a good conversation" for a casual assistant, or as specific as "You work for CitySan Services, a waste management company. Your name is Ayelen Lucero." The model reads these instructions and carries them through the conversation, including through interruptions. The way I read this architecture is that the text prompt is essentially the system prompt you'd give an LLM, just routed through a model that speaks instead of typing.
The voice prompt is an audio token sequence that captures vocal characteristics, speaking style, and prosody. You supply a short clip, the model encodes it, and then conditions its speech generation on those embeddings throughout the conversation. This is zero-shot voice cloning, meaning no fine-tuning required, just the audio at inference time. In practice it means you can define a persona once, attach a voice sample, and deploy it across thousands of conversations.
What makes this hard, and what the paper doesn't undersell, is that you need to do all of this with low latency under continuous streaming conditions. The model can't pause to re-read its role prompt. It has to maintain persona coherence while processing incoming user audio frame by frame and generating output tokens at the same time. That's not a trivial engineering problem, and it's why previous full-duplex systems didn't ship this capability.
Training: Synthetic Data as the Bridge
PersonaPlex couldn't be trained on existing conversational datasets because those datasets don't contain the kind of annotated, role-conditioned, multi-speaker dialogues the model needs. So NVIDIA built their own. The synthetic training corpus includes 39,322 assistant dialogs and 105,410 customer service conversations. Transcripts were generated using Qwen3-32B and GPT-OSS-120B, then synthesized into audio using Chatterbox TTS from Resemble AI. The result is paired conversations where the role prompt, the agent's behavior, and the audio are all aligned from the start. The problem with synthetic data alone is that it can teach the model what to say without teaching it how real conversations flow. Synthetic speech tends to lack the micro-variations in pace, the half-completed sentences, the genuine backchannels. To address this, the team layered in 7,303 real conversations (1,217 hours) from the Fisher English Corpus, annotating each with LLM-generated role prompts retrospectively.
This is the design choice I find most interesting. Instead of choosing between naturalness (real data) and task adherence (synthetic data), the team used the hybrid prompt architecture as a bridge between both sources. The Fisher conversations teach speech behavior. The synthetic conversations teach role conditioning. The shared conditioning format means both types of training reinforce the same prompting interface.
What the Benchmark Numbers Actually Show
The results are strong, and in some places striking. On the Full-Duplex-Bench benchmark, PersonaPlex achieves a Dialog Naturalness Mean Opinion Score of 3.90. Gemini Live scores 3.72, Qwen 2.5 Omni scores 3.70, and Moshi scores 3.11. That's a meaningful gap, especially versus Moshi, which is the closest architectural comparison. The latency numbers are even more pronounced. PersonaPlex switches speakers in 0.07 seconds. Gemini Live takes 1.3 seconds for the same transition. That's roughly 18x faster at the moment of handoff, which is the moment where conversations feel most robotic if things go wrong. On turn-taking, PersonaPlex hits a Takeover Rate of 0.908 with 0.170s latency, and handles user interruptions with a TOR of 0.950 at 0.240s.
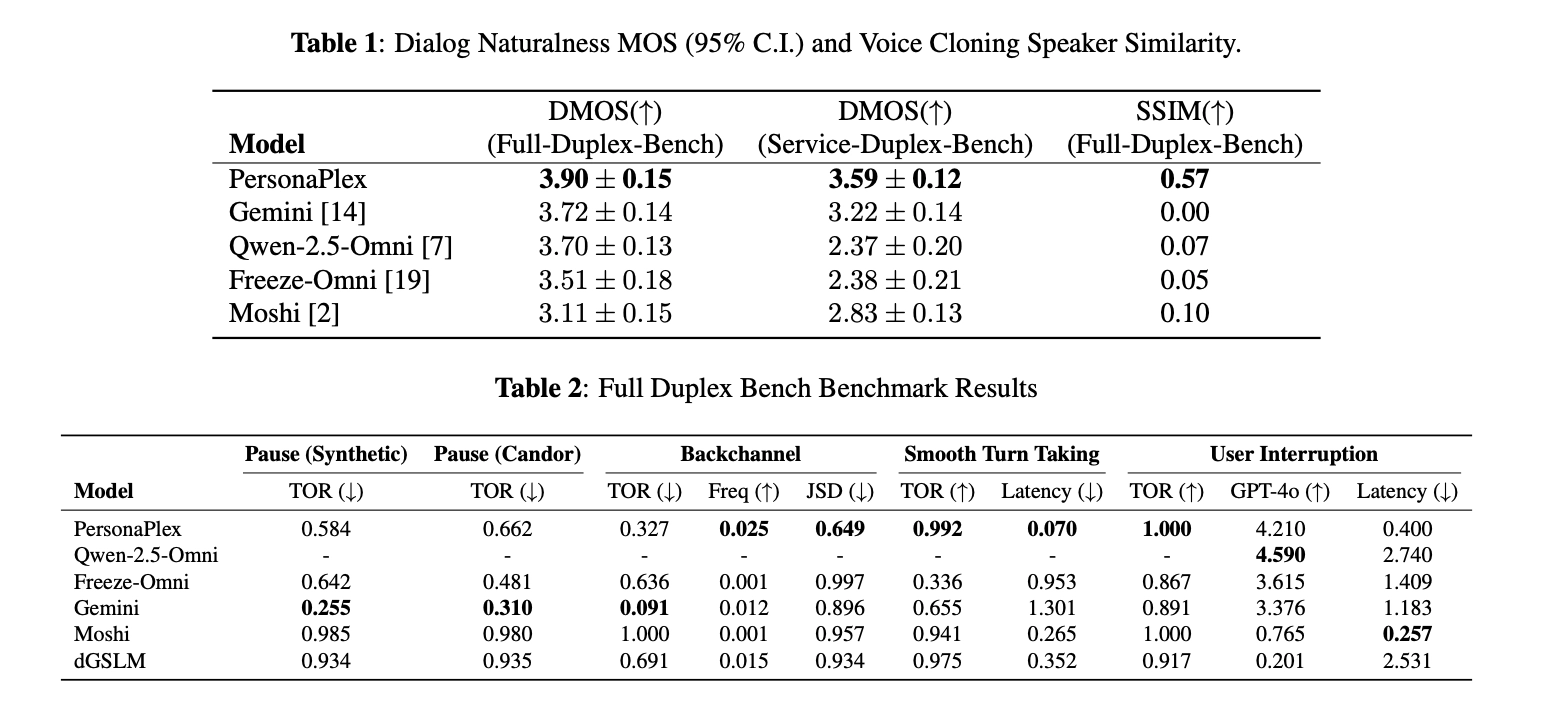
For role adherence, the team built a new benchmark called Service-Duplex-Bench, extending Full-Duplex-Bench with 350 customer service questions across 50 role scenarios. This matters because existing benchmarks tested a single generic assistant role, which tells you nothing about whether a model can actually hold a specific persona under conversational pressure.
PersonaPlex achieves strong performance here too, though I'll note the paper is appropriately careful about how much can be generalized from a benchmark you designed yourself. Speaker similarity, measured using WavLM-TDNN cosine similarity between voice prompts and model outputs, comes in at 0.650. This is decent for zero-shot voice cloning but not exceptional. The voice cloning is good enough that the persona feels coherent, but don't expect it to perfectly reproduce a target speaker's voice from a short clip.
When This Gets Complicated in Practice
Here's where implementation gets interesting.
One use case that pushes PersonaPlex hardest is voice simulation, where instead of playing the agent, you ask the model to play the user. Think of it like synthetic user testing: you want the model to behave like a specific customer type, with a particular communication style, emotional state, and domain knowledge, so you can stress-test your actual agent on the other end. This is legitimately useful for QA pipelines and agent evaluation. But it's a meaningfully harder ask than role-conditioned agent behavior. The model was trained to follow agent-side personas in structured service scenarios. Flipping it to play a realistic, unpredictable human caller, who might hedge, go off-topic, or express frustration mid-sentence, is a real distribution shift. The persona conditioning works, but the behavioral authenticity of a simulated user is much harder to verify than whether an agent stayed on-script. I haven't seen robust evaluations of this pattern yet, and it's one of the more interesting open problems if you're trying to build automated voice testing infrastructure.
The model has a 200-token budget for system prompts. That's not a lot when you're trying to specify a detailed role with background context, business rules, and behavioral constraints. Enterprise customer service scenarios routinely need more context than that. The paper doesn't fully address how degradation scales as prompts approach or exceed this limit.
The training coverage also matters. PersonaPlex was trained on assistant and customer service scenarios. The astronaut emergency example in the project page is a good demonstration that the model generalizes somewhat beyond training domains, but the further you get from the training distribution, the less confident you should be about role adherence. A model trained on customer service bots handling a medical triage workflow is a meaningful extrapolation.
Voice cloning from a short clip is also noisier in real deployments than benchmarks suggest. The quality of the voice prompt clip, background noise, codec artifacts all affect how well the model latches onto the target voice. This isn't a PersonaPlex-specific problem, it affects every zero-shot voice cloning system, but it's worth accounting for if you're designing a production deployment around specific voice identities.
None of this is a reason not to build with PersonaPlex. It's the most capable open full-duplex system available. But the gap between the demo and the production deployment is real, as it always is with these systems.
Conclusion
Full-duplex speech models solved naturalness but left persona control on the table. PersonaPlex closes that gap, combining real-time duplex dynamics with hybrid conditioning that lets you define both who the model is and what it sounds like before a single word is spoken. The results across naturalness, latency, and role adherence are the best in the open-source category, and the decision to release weights and code makes this immediately deployable.
The deeper shift here is architectural. PersonaPlex demonstrates that persona conditioning doesn't require sacrificing duplex dynamics, and that synthetic and real data can be blended effectively when the training interface is designed to bridge them. That principle is going to matter well beyond this specific model. The question for the field is no longer whether you can build a natural voice agent. It's whether you can build one that stays in character under pressure.
For the full architecture details, the paper : PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models


