Meta-Harness: What if we let an agent optimize the code around an LLM?

There's a pattern that anyone who's shipped an LLM-powered product has run into: you pick a model, you wire it up, and then you spend the next three months discovering that the thing around the model matters as much as the model itself. What you retrieve, how you format it, when you summarize, which state you throw away: all of that scaffolding (call it the "harness") can swing performance on the same benchmark by as much as 6×. Same weights. Same prompts, roughly. Different outcomes.
So here's a reasonable question: if that harness is the thing actually moving the needle, why are we still writing it by hand?
A new paper out of Stanford, MIT, and KRAFTON: *Meta-Harness: End-to-End Optimization of Model Harnesses,* takes a swing at automating it. And the results are genuinely interesting, especially if you care about where agent systems are headed.
The setup: why existing "text optimizers" fall short
Before we get to the method, it's worth understanding why this isn't a solved problem. There's already a family of techniques for iteratively improving text artifacts, things like OPRO, TextGrad, GEPA, AlphaEvolve, OpenEvolve, and Feedback Descent. They all follow a rough template: try a thing, get some feedback, use that feedback to propose the next thing.
The catch is how they compress feedback. OPRO hands the optimizer pairs of (solution, score). TextGrad passes textual feedback on the current artifact. GEPA uses reflective summaries of rollout traces. AlphaEvolve feeds back a window of the program database plus eval scores. These are all reasonable pragmatic choices: you can't just shove everything into a context window.
But the authors make a sharp point: harnesses are long-horizon programs. A decision about what to store in memory at step 3 might only matter at step 47. When you compress feedback into a scalar score or a tidy summary, you're throwing away the exact signal you'd need to trace "this harness got confused here" back to "because of that design choice earlier." They back this up with a table showing existing optimizers work with roughly 100 to 30,000 tokens of context per step. Meta-Harness works with around 10 million. That's three orders of magnitude more diagnostic information per iteration.
The idea: give an agent the full filesystem
The architecture is almost suspiciously simple. You have an outer loop that:
- Keeps a filesystem where every past candidate harness lives: its source code, its scores, and its full execution traces (prompts, tool calls, model outputs, state updates, everything).
- Hands this filesystem to a coding agent (they use Claude Code with Opus-4.6) and says "propose a new harness."
- Evaluates the proposal, dumps all its logs into a new directory, and loops.
That's it. No fancy parent-selection heuristic. No hand-designed mutation operators. No fixed scaffold the agent has to fill in. The agent just... pokes around with grep and cat, reads what it wants, and writes new code.
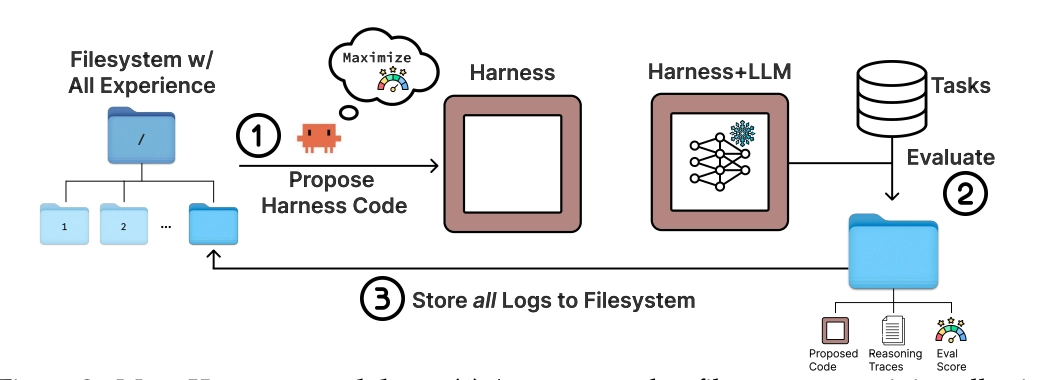
This is where it gets conceptually clean. Instead of the outer loop deciding what feedback to hand the proposer, the proposer decides what feedback to look at. In the TerminalBench-2 run, the agent reads a median of 82 files per iteration, referencing over 20 prior candidates per step. It's genuinely navigating the history instead of just looking at the most recent parent/
The authors note, with a footnote that's maybe a little too casual given how much rests on it, that "this workflow only became practical recently, following major improvements in coding-agent capabilities around early 2026." In other words: this wouldn't have worked a year ago. The method rides on the fact that coding agents are now good enough to do this kind of selective diagnosis on their own.
Does it actually work?
Three very different testbeds. All three show meaningful gains.
Online text classification
The task: an LLM gets labeled examples one at a time, updates some memory, and has to classify held-out items. This is the turf of systems like ACE (Agentic Context Engineering) and MCE (Meta Context Engineering): hand-designed harnesses that are current state-of-the-art.
Meta-Harness beats ACE by 7.7 points on average accuracy. And it does it while using 4× fewer context tokens. That's the kind of result that makes you squint a little, because usually you pay for accuracy with context.
More damning for existing text optimizers: Meta-Harness matches the final accuracy of OpenEvolve and TTT-Discover after just 4 evaluations. They're still chugging at 40. That's a 10× efficiency gain.
The authors also run a nice ablation. What if you give the proposer scores only? What if you give it scores plus LLM-generated summaries of what happened? Both conditions reach around 34–35% median accuracy. The full Meta-Harness interface (with raw execution traces available) hits 50%. Summaries don't recover the signal; in fact they seem to hurt by compressing away the bits you actually needed.
Retrieval-augmented math reasoning
Here's a setup where retrieval has historically been underwhelming: IMO-level olympiad problems. You'd think adding a corpus of 500K+ solved problems would help, but naive retrieval usually doesn't surface the right traces.
They let Meta-Harness search over retrieval harnesses for 40 iterations on a search set, then evaluate the single best harness on 200 held-out IMO-level problems across five different models (GPT-5.4-nano, GPT-5.4-mini, Gemini-3.1-Flash-Lite, Gemini-3-Flash, GPT-OSS-20B).
The discovered harness improves accuracy by 4.7 points on average over no retrieval, and does it across all five held-out models. One search, five models, all better. That generalization across models is the part I find most interesting as it suggests the harness is encoding something genuinely useful about the task structure rather than overfitting to quirks of the search model.
The discovered program, when you read it, is a four-route BM25 system that routes problems into combinatorics, geometry, number theory, or default, with different retrieval and reranking policies per route. Nobody told it to do that. It just emerged.
Agentic coding (TerminalBench-2)
This is the result the authors lead with, and it's the most directly competitive. TerminalBench-2 is a hard agent benchmark with an active leaderboard and multiple teams are directly optimizing for it. Meta-Harness initializes from Terminus-KIRA (a strong hand-engineered baseline) and iterates.
On Claude Haiku 4.5, the discovered harness hits 37.6%, making it #1 on the leaderboard and beating Goose (35.5%) and Terminus-KIRA (33.7%). On Opus 4.6, it hits 76.4%, #2 overall.
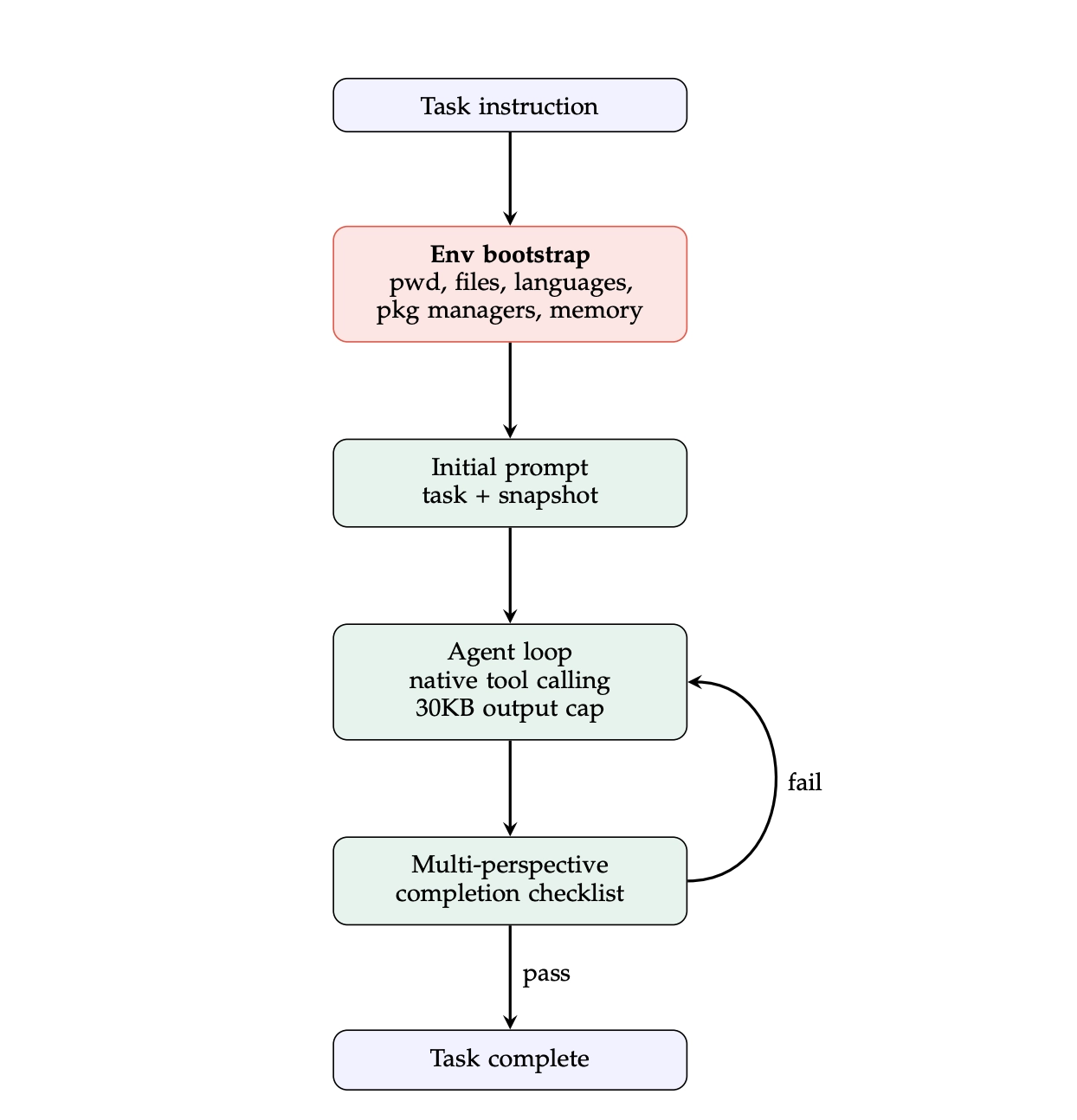
The most interesting bit is what the agent discovered. After a bunch of failed iterations trying to fix the completion-flow logic and prompt templates (all of which regressed from the baseline), the proposer shifted strategies entirely and added an "environment bootstrap": a small shell command that runs before the agent loop starts, gathering a snapshot of the sandbox (installed languages, package managers, /app contents, available memory) and injecting it into the initial prompt. That's it. ~80 lines of code on top of Terminus-KIRA.
The hypothesis, quoted from the agent's own reasoning: injecting this snapshot eliminates the 3–5 wasted exploration turns where the agent is just probing to figure out what's installed.
Causal reasoning
The appendices have full traces of the proposer's reasoning across iterations, and this is where it starts to feel like something more than search. In the TerminalBench-2 run, the first two iterations both regressed sharply. Both bundled structural fixes with prompt-template rewrites.
By iteration 3, the agent had explicitly diagnosed the confound. Its own words (quoted verbatim from the log):
Prior attempts: evo_marker_fix (58.9%, -5.6pp), evo_single_confirm (57.8%, -6.7pp) — both regressed. Root cause of regressions: Prompt template changes (cleanup directives) caused the agent to delete necessary state before task completion. The structural bugfixes were confounded with harmful prompt changes. evo_strip_only isolates the two proven structural fixes.
It's identifying a confound. It's isolating variables. After six consecutive regressions, it explicitly pivots: "All 6 prior iterations regressed from the 64.4% baseline because they modified the completion flow, prompt template, or observation processing. evo_env_bootstrap takes a different approach — purely additive."
Whether you call this "real" causal reasoning or sophisticated pattern-matching on long traces is kind of a philosophical question. What's empirically clear is that an optimizer with only scalar scores or summaries literally cannot do this, because the information needed to form the hypothesis has already been compressed away.
What this actually tells us
A few things worth sitting with:
The bitter lesson angle. The authors invoke Sutton's bitter lesson toward the end, and it fits. Hand-engineered harnesses with clever heuristics are being matched or beaten by a general-purpose agent doing unrestricted search. As coding agents get better, this gap should widen, not close. You can see why: Meta-Harness has no fixed scaffold to outgrow.
"Search with diagnostic access" as a primitive. The interesting abstraction here isn't really "use an agent to write harnesses." It's "structure your optimization so the optimizer can retrieve whatever diagnostic information it needs." That's more general. You could imagine the same pattern applied to hyperparameter search, or RLHF reward model design, or any setting where you're currently feeding a meta-optimizer a lossy summary.
The inspection angle. One advantage that doesn't get enough airtime in the paper: overfitting in code space is legible. If your evolved harness has a brittle if-chain or a hard-coded class mapping for your benchmark, you can see it. Compare that to weight-space overfitting in RLHF, which you basically can't inspect. Discovered harnesses are human-auditable artifacts.
The cost question. The paper doesn't dwell on this, but Meta-Harness is not cheap. A typical run evaluates ~60 harnesses over 20 iterations, with evaluations producing up to 10M tokens of diagnostic information each. Whether this is economical depends a lot on how much you'd otherwise pay a human engineer to iterate on your harness, and how much the resulting harness is worth. For a contested benchmark or a production system where harness quality compounds, probably worth it. For a weekend project, probably not.
A few honest caveats
The authors are pretty upfront about the limits. They tested with one proposer (Claude Code with Opus-4.6), we don't yet know how much of this depends on the specific agent being genuinely strong. On TerminalBench-2 they did search and final evaluation on the same 89-task benchmark, which they justify (it's expensive, it's a "discovery problem") but it does mean we can't cleanly separate generalization from benchmark-specific optimization there. The math retrieval results, by contrast, have clean held-out evaluation across five unseen models, and that's probably the most convincing generalization evidence in the paper.
Also: the method is agentic all the way down. The outer loop is an agent proposing harnesses. The harnesses themselves are programs. The base model inside the harness is running as an agent on some tasks. If you're already nervous about attribution and reproducibility in agent systems, Meta-Harness stacks three layers of it.
Where this points
The thing that's stuck with me since reading this paper is less about the specific numbers and more about the methodology. For a while now, the dominant flavor of "text optimization" has assumed you need clever compression of feedback, be it summaries, gradients-through-text, or reflective critiques, because you couldn't possibly give the optimizer everything.
Meta-Harness is basically saying: okay, but what if you could? What if the coding agent is smart enough to do its own triage? The bet the paper makes is that selective access beats lossy summarization, and the results suggest they're right, at least when the proposer is strong enough to navigate the information.
If that's the correct framing, a lot of existing optimization pipelines start looking like they were over-engineered around a limitation that might not exist anymore. Which is exciting, or unsettling, depending on how much of your infrastructure was built around that limitation.
Either way, worth a read. The appendices, especially the search trajectory logs, are where the method really comes alive.
Paper: arxiv.org/abs/2603.28052 · Project page with interactive demo: yoonholee.com/meta-harness


