MCPToolBench++: Raising the Bar for Realistic AI Agent Tool-Use Benchmarks

Introduction
At the heart of reliable AI agents lies one critical skill: effective tool calling. We can see this in action with systems like the new Kimi K2, which connects seamlessly to dozens of tools, including web search, map navigation, financial analysis, and automated workflows. This results in impressive versatility and great tool call accuracy. In today’s era of the MCP, the ability for models to select and operate the right tool at the right time is essential for effective AI automation and workflows. However, rigorously evaluating and benchmarking these tool-using models presents a major challenge: there is a lack of comprehensive, realistic datasets and benchmarks that reflect the true diversity, scale, and complexity of real-world tool ecosystems. Addressing this gap, this paper introduces MCPToolBench++ - a large-scale, multi-domain benchmark specifically designed to enable robust, meaningful evaluation of tool call accuracy and agentic intelligence for the next wave of AI systems.
The MCP Landscape: Real-World Tool Use and Evaluation Needs
Many of today’s state-of-the-art language models come equipped with powerful function-calling skills (as they are trained on them) enabling them to search, plan, browse, and fetch real-time information from diverse APIs. These capabilities let agents tackle everything from quick web queries to in-depth research, managing schedules and processing documents, travel booking, and multi-step planning, all through seamless interaction with tools.
As real-world applications grow more intricate, agents are now expected to interface with a vast ecosystem of MCP servers - each with its own schemas, parameters, and quirks. Successfully handling single-step tasks or coordinating multi-stage toolchains requires models to be highly adaptable. Yet, as we’ve seen firsthand at Maxim, building high-quality datasets for robust evaluation of tool calling is tedious, time-consuming. MCPToolBench++ directly addresses this bottleneck, automatically curating a large and diverse benchmark by sourcing single and multi-step tool calls from over 4,000 MCP servers across 40+ categories - setting the foundation for the next era of agent evaluation.
Data Preparation and Benchmark Construction
The authors developed an automated data preparation pipeline that consists of four major steps:
- Tool Schema Collection: They first aggregated thousands of MCP server schemas and configurations from public MCP marketplaces and open-source communities across 40+ application categories. eg: Paypal, playwright mcp marketplace etc
- Task Sampling: Systematically sampling tools to generate both single-step and multi-step (compositional) workflows, ensuring broad and realistic domain coverage using a tool sampler.
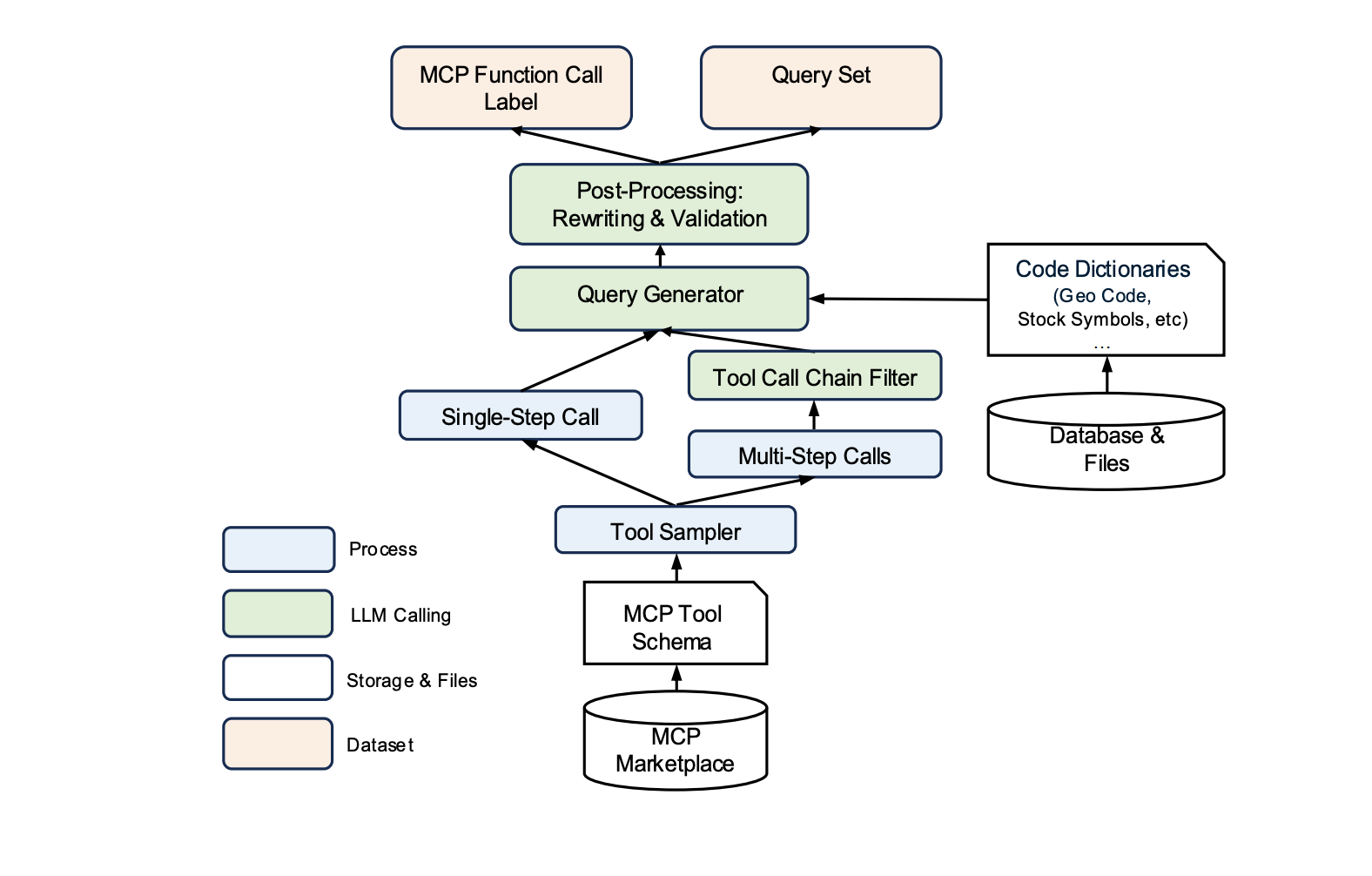
- Query Generation and Parameter Filling: Using LLMs to craft natural, diverse user queries and intelligently populate task parameters, including challenging fields like geo-codes or financial symbols.
- Validation and Filtering: Reviewing and refining each generated example for clarity, logical consistency, realism, and diversity - removing duplications and non-plausible samples.
logical consistency checks remove physically or semantically impossible queries (e.g., “travel from New York to Tokyo by train,” which is not physically possible)
Together, these steps produce a benchmark that not only reflects the scale and diversity of real-world agent tasks, but also enables precise measurement of how well models can interpret, compose, and execute tool calls.
Evaluation Methodology, Metrics, and Results
The core evaluation is performed in environments where models are run via MCP-compatible clients, with tool quotas and real-world execution constraints in place to guarantee fair and reproducible results. The metrics used are :
- Abstract Syntax Tree (AST) Accuracy: Measures whether the agent chooses the correct tool and fills in parameters accurately, by comparing the model’s tool call structure against ground truth - using the abstract syntax tree concept
- AST DAG Accuracy: For multi-step tasks, this metric evaluates the entire execution plan as a Directed Acyclic Graph, ensuring the correct chaining and dependencies between tool calls. This handles Parallelism/Convergence of multi step tool calls well.
- Pass@K (Execution Success Rate): Evaluates whether the model’s tool call actually runs successfully, returns the right result, and matches the expected output.
- Tool Call Success Rate: The strict ratio of tool calls that succeed (status code, no errors) to all attempts, highlighting challenges like parameter errors, unreliable APIs, or real-world failures.
Baseline Results:
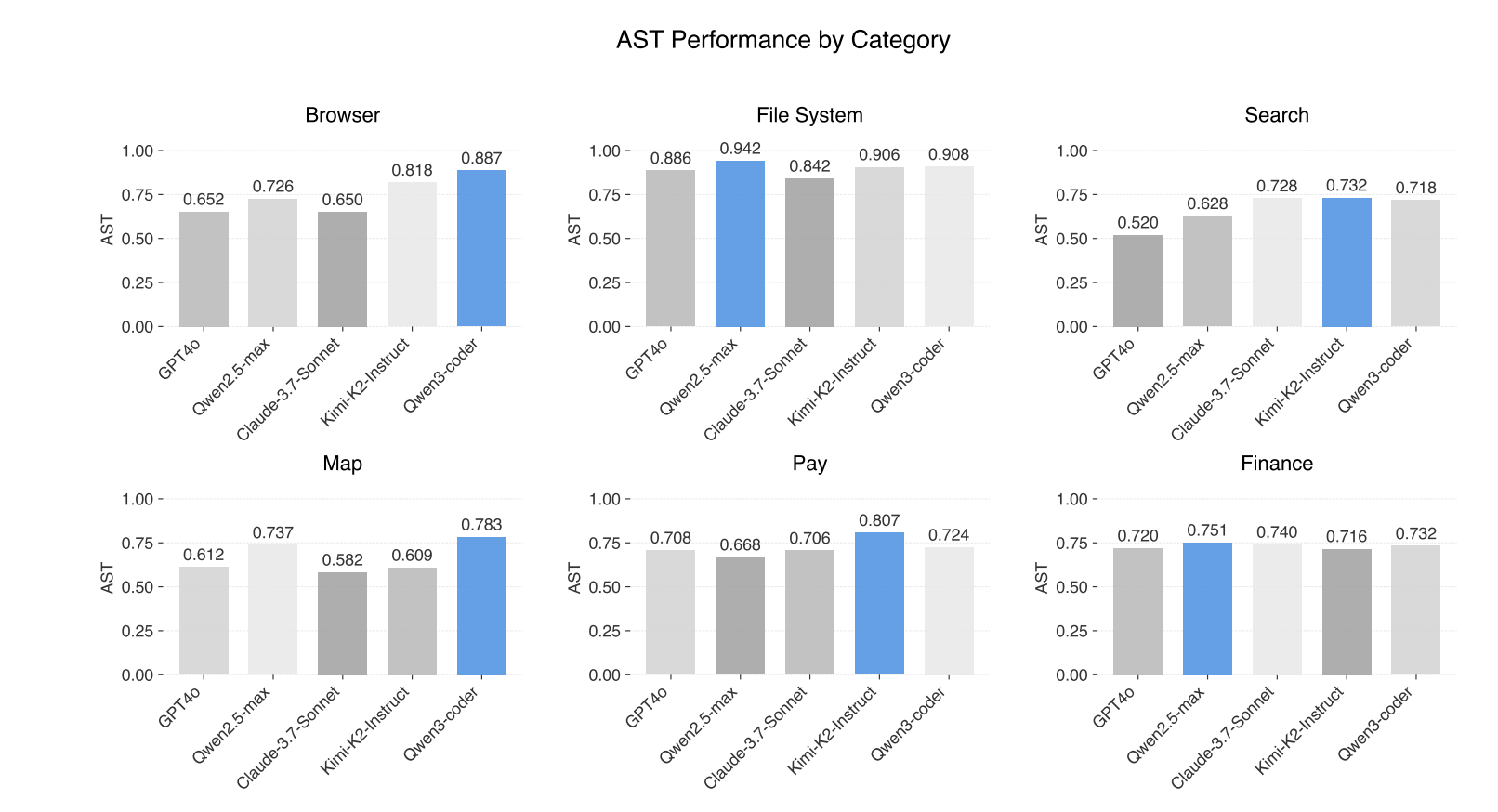
The paper benchmarks a range of state-of-the-art models, including GPT-4o, Qwen2.5-max, Claude-3.7-Sonnet, Kimi-K2-Instruct, and Qwen3-coder.
- Performance varies by task type and category: for example, Qwen3-coder excels in browser and map tasks (highest AST and Pass@1), while Qwen2.5-max leads in file system and finance, and Kimi-K2-Instruct shows particular strength in search and payments.
- Notably, AST structure accuracy does not always correlate with execution success - models can appear correct in planning but fail in real-world execution due to tool/APIs quirks or parameterization issues.
Key Insights:
- The benchmark reveals clear gaps: even top models struggle with complex chains, parameter reasoning (e.g., stock tickers, geo-codes), and handling error-prone APIs.
- Root cause analysis highlights that parameter errors, empty results, API issues, and runtime failures remain persistent barriers in practical tool use - informing where future agent improvements are needed.
Conclusion
MCPToolBench++ sets a new standard for evaluating AI agents’ real-world tool use, tackling a crucial gap in the field: the scarcity of comprehensive datasets and benchmarks for assessing tool calling. By spanning thousands of live MCP servers, covering multi-step and cross-domain scenarios, and supporting multilingual tasks, this benchmark exposes critical gaps in even the strongest models - especially when it comes to complex workflows and precise parameterization, where execution often falls short of planning. More than just another leaderboard, MCPToolBench++ acts as a practical stress test, revealing where agents still struggle amid real-world API unpredictability. As one of the few resources that systematically measure model performance on true tool use, it paves the way for future benchmarks - and for accelerating genuine progress toward robust, deployable agentic systems.
For a deeper dive -
MCPToolBench++ - A Large Scale AI Agent Model Context Protocol MCP Tool Use Benchmark


