Making Voice Assistants Faster Without Losing Accuracy

Have you ever noticed how some voice assistants seem to understand you instantly, while others leave you waiting? That delay isn't random. It's the result of a fundamental trade-off that has plagued speech recognition for years. Systems could either be fast or accurate, but rarely both.
New NVIDIA research in streaming speech recognition is changing this equation. The breakthrough? Teaching the system to remember what it has already heard, instead of constantly re-processing the same audio over and over. The results are striking: the new approach achieves 6.3% error rate with 1.36 seconds of latency, compared to 11.3% error rate for traditional buffered systems with even longer delays.
Why Voice Recognition Has Been So Inefficient
Think about how most streaming speech systems work today. They process your voice in small chunks, like reading a book one paragraph at a time. But here's the catch: to understand each new paragraph, they also re-read several previous paragraphs for context. Every. Single. Time.
This is called buffered streaming, and while it works, it's incredibly wasteful. The researchers tested this on LibriSpeech, a standard benchmark dataset, and found that buffered approaches required 2-4 second buffers just to maintain reasonable accuracy. All that redundant processing adds up.
The problem gets worse when many people use the system at once. All that redundant processing multiplies, causing delays that make conversations feel unnatural. The assistant might consistently respond multiple seconds after you finish speaking: breaking the natural flow of conversation.
A Smarter Approach: Memory Instead of Repetition
The solution is surprisingly intuitive: give the system a memory. Instead of re-processing audio it has already heard, the system simply remembers the important parts and builds on them as new audio arrives.
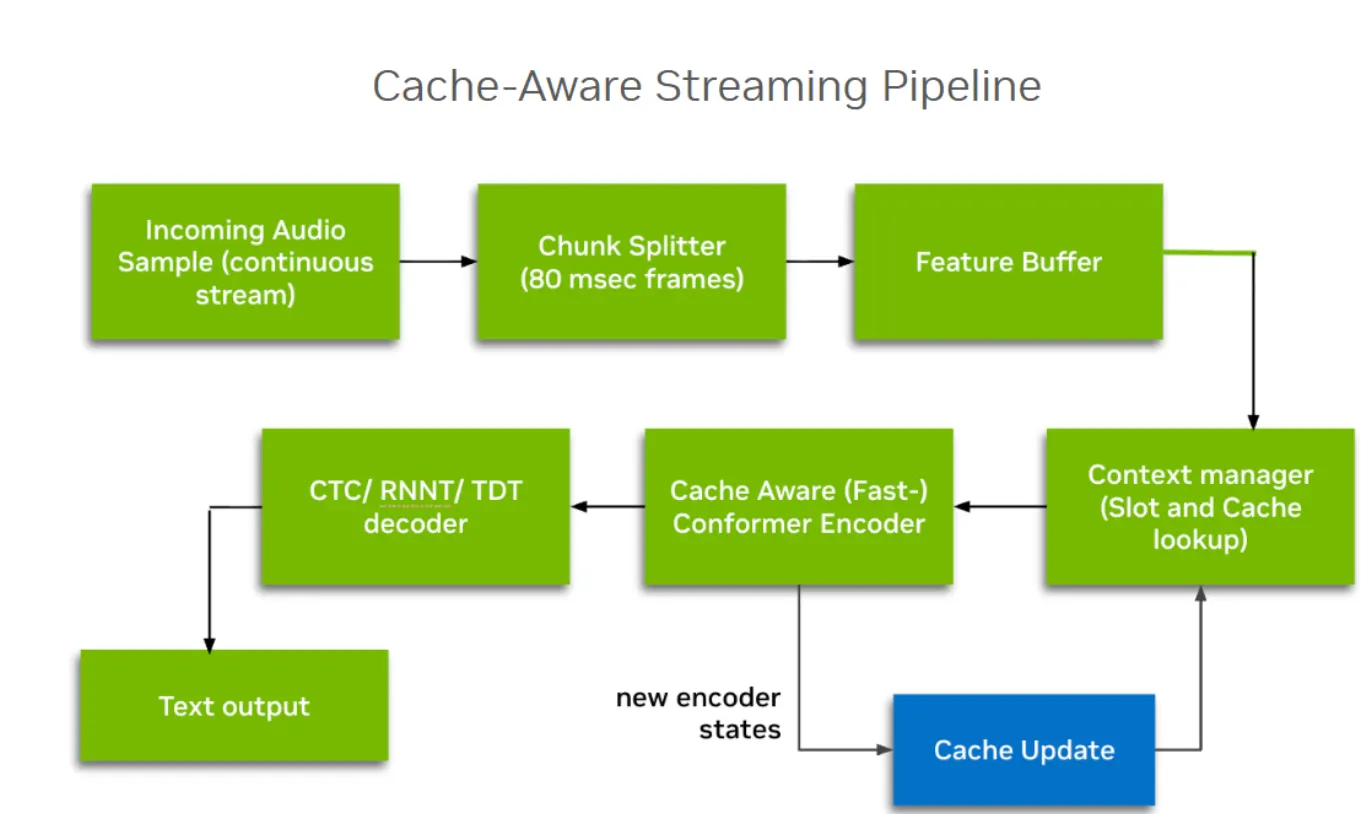
The approach is built on the FastConformer architecture, which is more than 2x faster than standard Conformer models. The key innovation is what researchers call "cache-aware streaming": during training, the system still learns efficiently by processing full audio clips all at once. But during actual use, when you're speaking to it in real-time, it switches to a mode where it remembers previous calculations and only processes the new audio.
Think of it like this: the old way was like solving the same math problem from scratch every time you added one more number. The new way is like keeping your running total and just adding the new number to it.
The system maintains two types of memory:
- Memory for context: When understanding speech, context matters. The word "read" sounds different in "I read books" versus "the book is red." The system keeps track of what it heard recently (the researchers limited this to a configurable past context), so it can make better decisions about what you're saying now.
- Memory for patterns: The FastConformer uses self-attention and convolution layers to find sound patterns. Instead of recalculating these patterns from scratch each time, it caches the intermediate activations and updates them with new information. For convolution layers with kernel size K, the cache stores K-1 previous steps. For self-attention layers, the cache grows to match the past context limit.
Balancing Speed and Understanding
One important decision is whether the system should react right away to what you’re saying, or pause for a split second to hear what comes next before deciding.
The researchers tested three approaches:
- No peeking (zero look-ahead): The system only knows what you've said up to this instant. This achieved 10.6% word error rate (WER) for the CTC decoder and 9.5% for the RNN-Transducer: impressively accurate considering zero delay.
- A little peeking (regular look-ahead): Each layer waits just a moment to hear what's next. The problem is these tiny waits add up across layers. In a model with 17 layers and 2 steps of look-ahead per layer, you end up with 1,360ms of effective latency (because 10ms frame rate × 4x subsampling × 17 layers × 2 steps = 1,360ms). This achieved 7.9% WER for CTC and 7.1% for RNN-T.
- Smart peeking (chunk-aware look-ahead): The system processes your speech in chunks. Within each chunk, it can see the full context, but it doesn't need to wait for multiple layers to peek ahead separately. With the same 1,360ms latency budget, this achieved 7.1% WER for CTC and 6.3% for RNN-T. This is better accuracy than regular look-ahead with the same delay.
The smart peeking approach also eliminates waste. With regular peeking, the system generates partial results that it immediately throws away. With chunk-based processing, everything it calculates is kept and used.
Getting the Best of Both Worlds
Speech recognition systems typically use one of two approaches to convert sounds into text. The CTC (Connectionist Temporal Classification) decoder is faster but generally less accurate. The RNN-Transducer decoder achieves higher accuracy but requires maintaining hidden states and more processing.
Instead of choosing one or the other, this research uses a hybrid architecture with both decoders sharing a single encoder. During training, the losses from both decoders are combined with a weighted sum (the researchers used α = 0.3 for the CTC weight).
The practical benefits are significant:
- No need for separate models: Train once, use either decoder based on your needs
- Faster convergence: The CTC decoder converges significantly faster when co-trained with RNN-T
- Better accuracy: Both decoders perform better than when trained separately. On the LibriSpeech test-other set with 1,360ms latency, the hybrid CTC achieved 7.1% WER versus 7.3% for non-hybrid, while hybrid RNN-T achieved 6.3% versus 6.4% for non-hybrid
- Computational savings: One shared encoder (~114M parameters) serves both decoders
Real Results: Faster and More Accurate
The researchers tested their approach on two major datasets: LibriSpeech (a standard benchmark) and NeMo ASRSET 3.0 (a large 26,000-hour multi-domain dataset). The results demonstrate clear advantages over traditional buffered streaming:
LibriSpeech Results (test-other set):
Comparing cache-aware streaming to buffered baselines:
- CTC with buffering (1,500ms latency): 8.0% WER
- CTC cache-aware chunk-aware (1,360ms latency): 7.1% WER
- RNN-T with buffering (2,000ms latency): 11.3% WER
- RNN-T cache-aware chunk-aware (1,360ms latency): 6.3% WER
The cache-aware approach achieves better accuracy with lower latency and significantly faster inference.
The Latency-Accuracy Trade-off:
Testing different latency settings shows a smooth, predictable relationship between delay and accuracy:
| Latency | CTC WER | RNN-T WER |
|---|---|---|
| 0ms (zero look-ahead) | 10.6% | 9.5% |
| 40ms | 10.1% | 9.0% |
| 240ms | 8.8% | 7.8% |
| 520ms | 8.4% | 7.5% |
| 680ms | 8.0% | 7.3% |
| 1360ms | 7.1% | 6.3% |
Importantly, chunk-aware look-ahead consistently outperforms regular look-ahead at the same latency. At 1,360ms, regular look-ahead achieved 7.9% WER for CTC and 7.1% for RNN-T, both worse than chunk-aware's 7.1% and 6.3% respectively.
Multi-Domain Performance:
On the large-scale NeMo ASRSET dataset, the cache-aware models were evaluated across nine different benchmarks including earnings calls, TED talks, and multilingual content. At 520ms latency, the RNN-T model averaged just 10.6% WER across all domains, compared to 15.0% for buffered streaming at 2,000ms latency.
One Model, Many Speeds
Here's another innovation: traditionally, if you wanted to support different speed settings (say, one for customer service, another for medical transcription), you'd need to train completely separate models. Each one optimized for its specific delay tolerance.
The research shows you can train a single model that works well at multiple speeds. During training, the system practices with randomly varying chunk sizes, making it more adaptable.
Surprisingly, this "jack of all trades" approach doesn't lead to compromises. The multi-speed model actually performs better at each individual speed than models trained specifically for that one setting:
Multi-Latency vs Single-Latency Models (NeMo ASRSET):
| Latency | Single-Latency CTC | Multi-Latency CTC | Single-Latency RNN-T | Multi-Latency RNN-T |
|---|---|---|---|---|
| 40ms | 7.9% | 7.6% | 6.4% | 6.2% |
| 240ms | 7.3% | 6.5% | 5.9% | 5.5% |
| 520ms | 6.2% | 6.0% | 5.4% | 5.2% |
The multi-latency model outperforms single-latency models at every operating point. Learning to handle variety makes it stronger overall. The diversity in training appears to act as a regularizer, improving generalization.
Why This Matters for Real Applications
The efficiency gains are dramatic when you scale up. Imagine a voice assistant service handling thousands of users simultaneously. With the old buffered method, all that redundant processing would quickly overwhelm the servers, causing delays or requiring massive infrastructure investments.
With this memory-based approach, the computational cost matches the actual audio length—process each moment once, and you're done. For a large-scale deployment, this can mean the difference between affordable service and unsustainable costs.
Best of all, this approach works with different types of speech recognition systems. Whether you need simple fast transcription (CTC) or high-accuracy applications (RNN-T), the same cached encoder serves both.
What This Means for the Future
This research represents a shift in how we think about real-time speech recognition. Instead of adapting systems designed for offline transcription to work in real-time (with all the compromises that entails), this approach designs for real-time from the ground up.
Key Technical Innovations:
The researchers made several design choices to ensure streaming consistency:
- Avoided normalization in mel-spectrogram extraction (which would require full-audio statistics)
- Made all convolutions fully causal with left-padding only
- Replaced batch normalization with layer normalization throughout
- Used FastEmit regularization (λ = 0.005) to prevent prediction delays
The consistency between how the system trains and how it actually operates eliminates a major source of accuracy loss. The cache mechanism eliminates wasted computation without losing the benefits of context. And the ability to train for multiple speeds means you don't need separate models for different use cases.
The Bottom Line:
Compared to traditional buffered streaming, cache-aware streaming achieves:
- Up to 44% reduction in word error rate (from 11.3% to 6.3% for RNN-T)
- Lower latency (1,360ms vs 2,000ms)
- Zero redundant computation
- Predictable memory usage
- Support for multiple latency settings from a single model
The techniques are available in open-source tools through the NeMo toolkit, making them accessible to developers building voice applications. The models work on standard datasets like LibriSpeech and scale to large multi-domain datasets with tens of thousands of hours of speech.
As voice interfaces become more common in our daily lives, technology that can scale efficiently while staying responsive will become essential. This work shows that the right architectural choices can deliver both speed and accuracy without compromise.
The key insight is simple but powerful: instead of doing the same work over and over, remember what you've already done. It's efficient, it scales, and it makes voice assistants work the way we expect them to: instantly understanding us without missing a word.
NVIDIA blog: https://huggingface.co/blog/nvidia/nemotron-speech-asr-scaling-voice-agents


