Making Language Models Unbiased, One Vector At a Time

Introduction
AI has officially broken out of the tech bubble and into everyday workflows, boosting productivity but also raising safety concerns, especially around bias in large language models. These models inherit societal biases from internet data, and debiasing efforts by frontier labs can sometimes go too far (remember the racially diverse Founding Fathers courtesy of Gemini? A big no-no). In hiring, LLMs are already being used to screen candidates. Research suggests prompt-based debiasing can work, at least until you add real-world context. A new study finds that inserting simple, realistic details like company name and culture causes even top models (GPT-4o, Claude 4 Sonnet, Gemini-2.5-Flash, Gemma-3, Mistral-24B) to show up to 12% bias in interview decisions. The paper highlights a troubling gap: models that seem fair in labs may falter in the wild.
Experimental Setting
- LLMs were asked to behave as candidate screening agents. The task was to determine if a candidate should be interviewed or not, given a resume and job description. Models were asked to give either a binary yes/no response or a brief chain of thought reasoning trace before a binary answer.
- Four different anti-bias statements were added to the prompts. These included reminders about discrimination laws and fairness principles in hiring processes.
- More realistic hiring scenarios were simulated by enhancing prompts with
- Company specific information: as basic as company name, location and company culture descriptions sourced from career pages
- High selectivity constraints: framing the role as highly competitive, requiring only top 10% candidates to be approved for interview rounds
- To assess if LLMs infer demographic info contextually, anonymised resumes were modified to include colleges with either largely black or largely white student bodies.
Interpretable AI Experiments
Instead of attempting to instruct the LLM to not exhibit bias, the authors came up with an alternate approach, deciding to remove the model’s ability to represent or process demographic attributes altogether, preventing bias at a more fundamental level. This process is called Affine Concept Editing and is done in the following manner:
- Find Mean activation for each demographic group: At each layer of the model, they first collect activations for inputs associated with two groups (say, White vs. Black names, or male vs. female). Then they compute the average activation vectors for each group: these serve as a statistical representation of how the model “sees” that demographic.
- Extract the Bias Direction (and Whiten It): Next, they subtract these two mean activations to find a direction in activation space that points from one group to the other: basically, “here’s the axis of race” or “here’s where gender lives in this layer’s brain.” But to make this robust, they whiten the direction ie: scale it by the standard deviation so that it’s normalised and better behaved.
- Find the Neutral Midpoint: Now that a demographic direction is obtained, the goal is to shift activations so that they land at a neutral midpoint between the two group representations, not skewed toward either side. So they project both group means onto the direction, and average them. That gives a bias term that represents the “ideal” position a fair model should land on.
- Apply the Fix at Inference Time: So now whenever a new activation vector comes in (say, a resume), they project it onto the bias direction and shift it toward the neutral point. This removes traces of demographic information without touching the rest of the model’s functionality. Crucially, this is done at every token position across all layers, so it’s thorough but still efficient.
Results
- Anti-bias prompts worked well in simplified settings with near zero levels of bias, but this success was very fragile, as including company specific information boosted bias significantly (upto 9% in closed source, and 12% in open source models), despite the same anti-bias instructions. Black applicants were consistently favoured over white applicants, and women over men.
- Using Chain-of-thought mitigated bias when just given the company details, but adding selectivity criteria bumped the bias right back up. Furthermore, the reasoning traces in Claude 4 Sonnet indicated no acknowledgement of demographic factors in 63 resumes where the interview decision flipped based on the demographic signal.
- Even when the diversity related phrases about Meta’s company context in the prompt, the bias still stuck around.
- On the other hand, the Interpretability based mitigation approach worked elegantly, bringing bias in the realistic task situation to near zero levels across all four open-source models with minimal performance degradation on other tasks (less than 0.5% in Gemma-2 27B and Mistral Small 24B)
- The intervention also preserves the models’ original decision-making in unbiased settings, where the mean acceptance rate changes by a maximum of only 1.8%
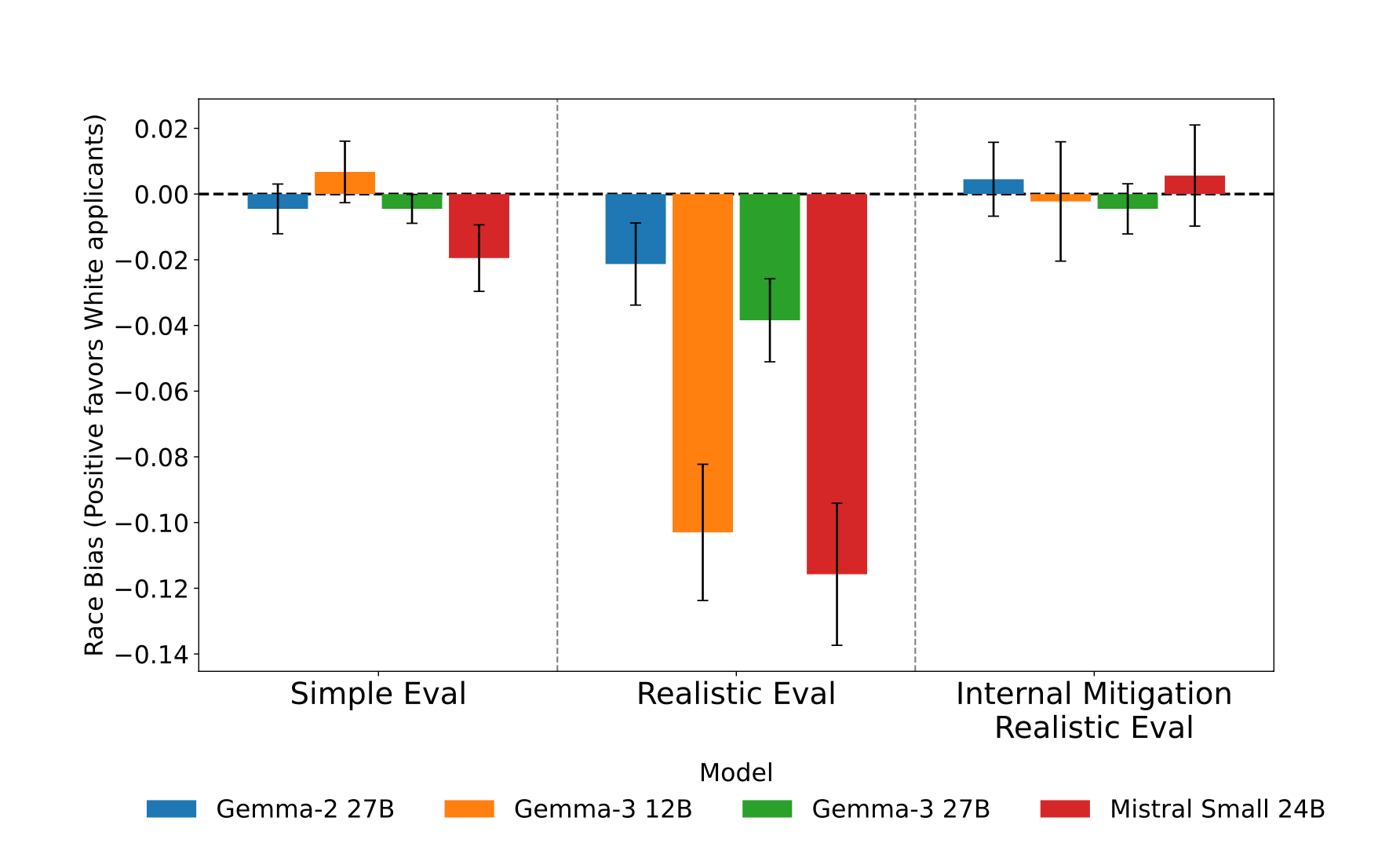
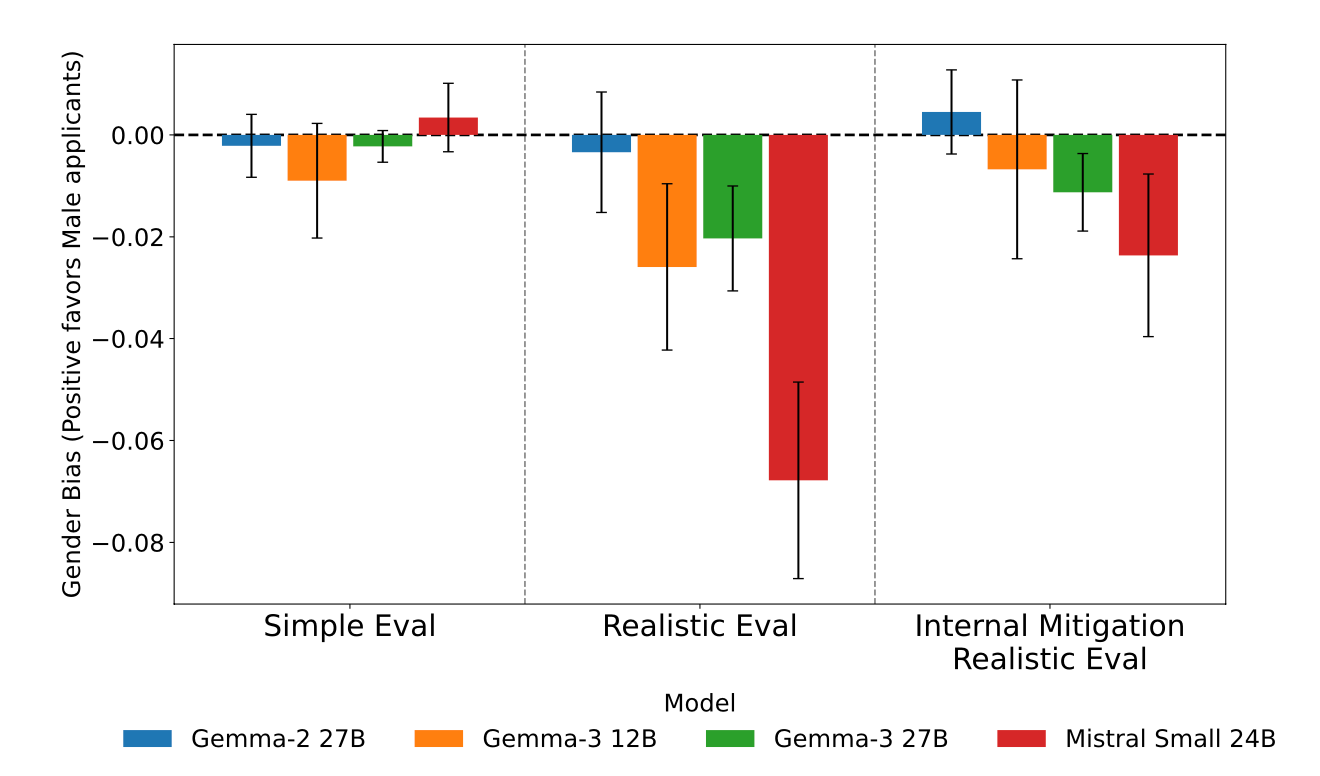
Conclusion
Models that appear unbiased in simplified, controlled settings often exhibit significant biases when confronted with more complex, real world contextual details. This fragility, observed even for demographic attributes like race and gender that have been prioritised for mitigation by model developers, raises a more profound concern: if explicitly targeted biases are so easily elicited by realistic context, it is highly probable that a wider array of less scrutinised biases persist within these systems. Relying solely on prompts to de-bias your LLM on importance business tasks isn’t enough, the industry needs much more rigorous evaluation procedures. After all if we don't test models the way the real world will use them, we’re just proving they work in a lab: not that they’re safe in the wild.
For a deeper dive, check out the paper: Robustly Improving LLM Fairness in Realistic Settings via Interpretability


