Kimi K2 Thinking: Engineering Deep Reasoning at Scale

Introduction
Moonshot AI recently open-sourced Kimi K2 and its reasoning-optimized variant, K2 Thinking. As someone who works with large language models, I wanted to break down what makes this release interesting and where it pushes forward the state of open-source AI.
K2 Thinking is a 1-trillion parameter model that can maintain coherent reasoning across hundreds of sequential steps (executing code, searching the web, calling APIs etc) without losing track of what it's trying to accomplish. That's harder than it sounds, and the engineering behind it spans everything from training stability innovations to novel approaches for teaching models to use tools.
This post walks through the key technical innovations: how they trained such a large model without crashes, how they generated training data for complex agentic behavior, and what makes the reasoning mode special.
The Foundation: Training a Trillion-Parameter Model
Solving Training Instability with MuonClip
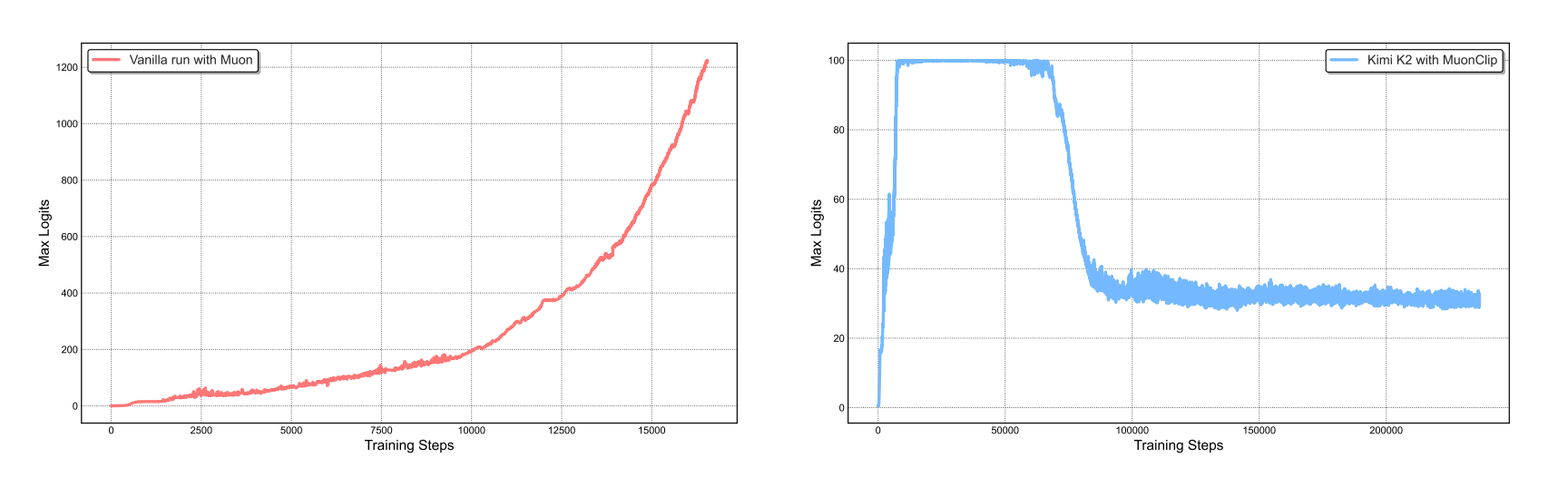
Training massive models is notoriously unstable. The typical failure mode: attention mechanisms blow up, numerical values explode, and your multi-million-dollar training run crashes.
Moonshot's solution was MuonClip, an optimizer that builds on the token-efficient Muon algorithm but adds a stability mechanism. The core idea: monitor attention values during training, and if they start growing too large, automatically rescale the model weights to bring them back under control.
Think of it like a thermostat for your model's internal calculations, it keeps things in a safe operating range without manual intervention.
The result: They trained K2 on 15.5 trillion tokens with zero training crashes. That's not just impressive: it's essential when you're spending months and millions of dollars on a single training run.
Architecture Choices: Extreme Sparsity
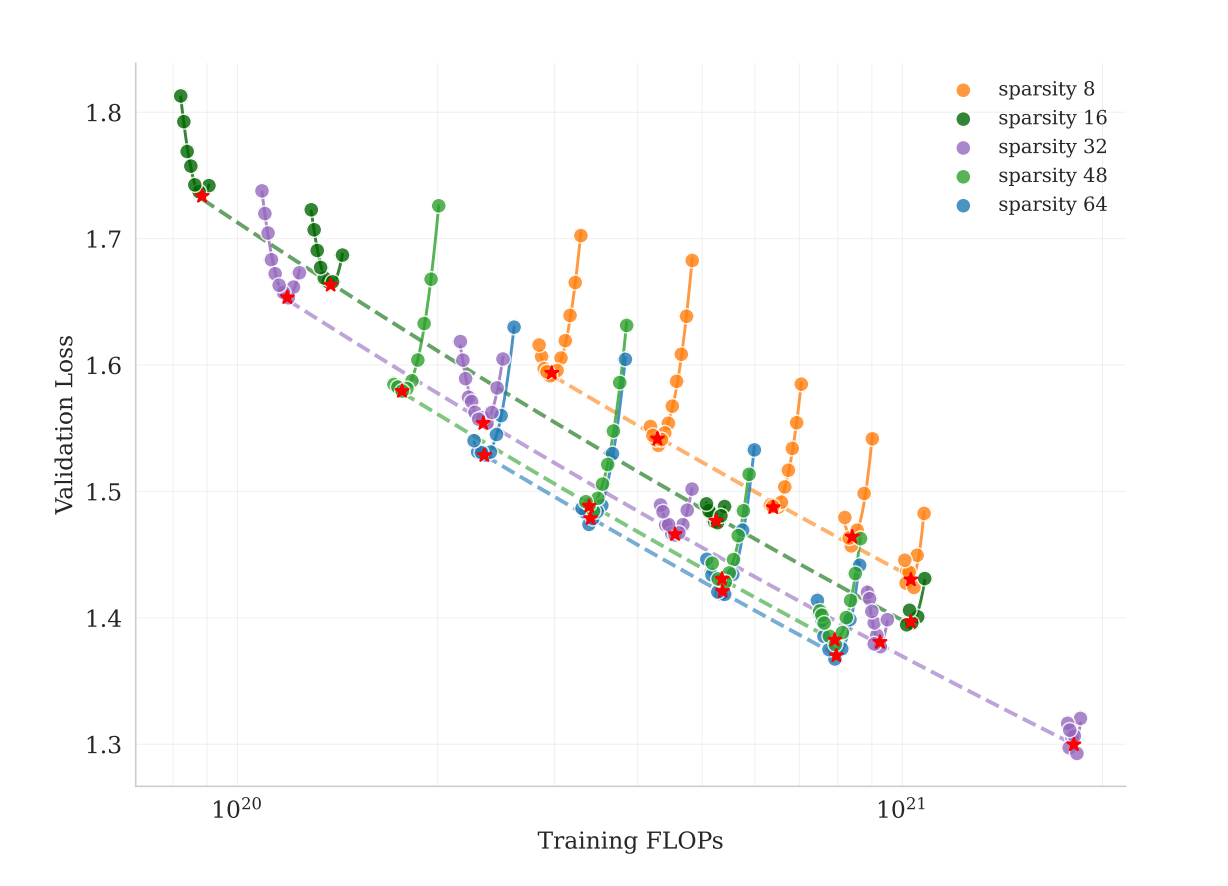
K2 uses a Mixture-of-Experts (MoE) architecture with some interesting design choices:
- 384 expert networks (neural network sub-modules specialized for different types of inputs)
- Only 8 experts activate for any given input (48:1 sparsity ratio)
- 32 billion parameters active per forward pass (out of 1 trillion total)
Why such extreme sparsity? Their experiments showed that increasing the total number of experts while keeping activated parameters constant consistently improved performance. More experts means more specialization, even if most sit idle for any single input.
They also reduced attention heads from 128 (in DeepSeek-V3) to 64. Doubling attention heads only improved performance by ~1%, but increased computation by 83% at long context lengths. For agentic tasks that process huge amounts of context, that tradeoff doesn't make sense.
Making Every Token Count: Data Efficiency
With high-quality training data becoming scarce, Moonshot focused on extracting more learning signal from each token through synthetic rephrasing:
For knowledge-heavy content, they used LLMs to rewrite texts from different perspectives and styles while maintaining factual accuracy. For long documents, they process chunks individually then stitch them back together to preserve coherence.
On factuality benchmarks, models trained on rephrased data (10 versions, 1 epoch each) outperformed models trained on raw data repeated 10 times. The key is adding diversity without introducing noise.
Teaching Agency: The Agentic Data Pipeline
This is where K2 really differentiates itself. Most models learn tool use through API examples. K2 was trained on tens of thousands of complete task trajectories showing multi-step tool use from start to finish.
Building a Synthetic Tool Ecosystem
The team created a three-stage pipeline:
1. Tool Creation
- Collected 3,000+ real tools from GitHub (MCP protocol)
- Generated 20,000+ synthetic tools across 17 domains (finance, healthcare, robotics, smart home, etc.)
- Each tool has clear interfaces, descriptions, and realistic behavior
2. Agent & Task Generation
- Created thousands of distinct agents by combining different tools and system prompts
- Generated tasks ranging from simple ("check the weather") to complex ("analyze quarterly reports and create visualizations")
- Each task includes explicit success criteria for evaluation
3. Trajectory Simulation
- Built a tool simulator that executes tool calls and provides realistic feedback
- LLM-generated users interact with agents naturally across multiple turns
- An LLM judge evaluates each trajectory—only successful attempts are kept for training
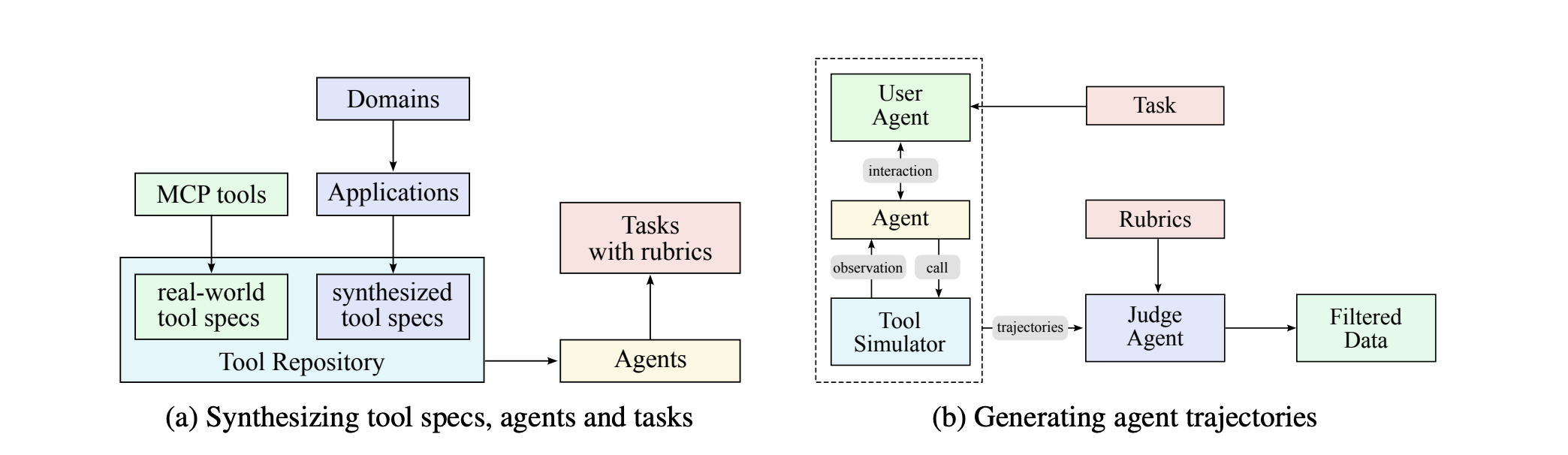
For coding tasks, they swap simulation for real execution: actual sandboxes running real code with real test suites. This grounds the model in genuine success signals rather than simulated ones.
Scale: 10,000+ concurrent execution environments generating diverse, high-quality training data.
Reinforcement Learning: Two Types of Rewards
K2's post-training uses RL with two complementary approaches:
Verifiable Rewards: For tasks with objective success criteria (math problems, code with unit tests, instruction-following constraints), the reward is clear: did you get it right?
Self-Critique Rewards: For subjective tasks (creative writing, open-ended questions), the model generates multiple responses and ranks them through pairwise comparison. The critic is continuously updated using signals from verifiable tasks, keeping its judgments grounded.
Key training optimizations:
- Token budgets: Different task types get different max lengths (prevents reasoning tasks from making all responses verbose)
- Temperature decay: Start with high randomness for exploration, gradually decrease for consistency
- Anti-forgetting: Mix in high-quality supervised data to prevent degradation on tasks not in the RL loop
The Reasoning Mode: K2 Thinking
K2 Thinking extends the base model with specialized training for long-horizon reasoning tasks. The key insight: reasoning isn't just generating a long chain of thought: it's interleaving thinking with action.
How It Works
[Think] → Analyze the problem, form hypothesis
[Act] → Execute tool call (search, code, API)
[Think] → Evaluate results, update hypothesis
[Act] → Refine based on findings
[Think] → Synthesize and verify
[Output] → Final answer
Each thinking block serves as a checkpoint:
- What's my current hypothesis?
- Which tool should I use next?
- Did the tool result satisfy my subgoal?
- Do I need to backtrack and try a different approach?
This creates a natural feedback loop that prevents the cascading errors common in reactive agents. The model isn't just executing a pre-planned sequence—it's actively evaluating and adjusting its approach.
Technical Optimizations
INT4 Quantization: Running 200+ reasoning steps is computationally expensive. K2 Thinking uses Quantization-Aware Training (QAT) to achieve INT4 precision with zero accuracy loss. This delivers:
- 2× faster inference
- 50% less GPU memory
- Same quality as full precision
Smart Context Management: With a 256K context window, long reasoning chains generate massive token counts. When approaching the limit, the model:
- Keeps the full reasoning chain (compressed insights)
- Hides raw tool outputs (already synthesized into reasoning)
- Retains key conclusions and hypotheses
This works because thinking steps already contain validated insights from tool executions.
Performance Highlights
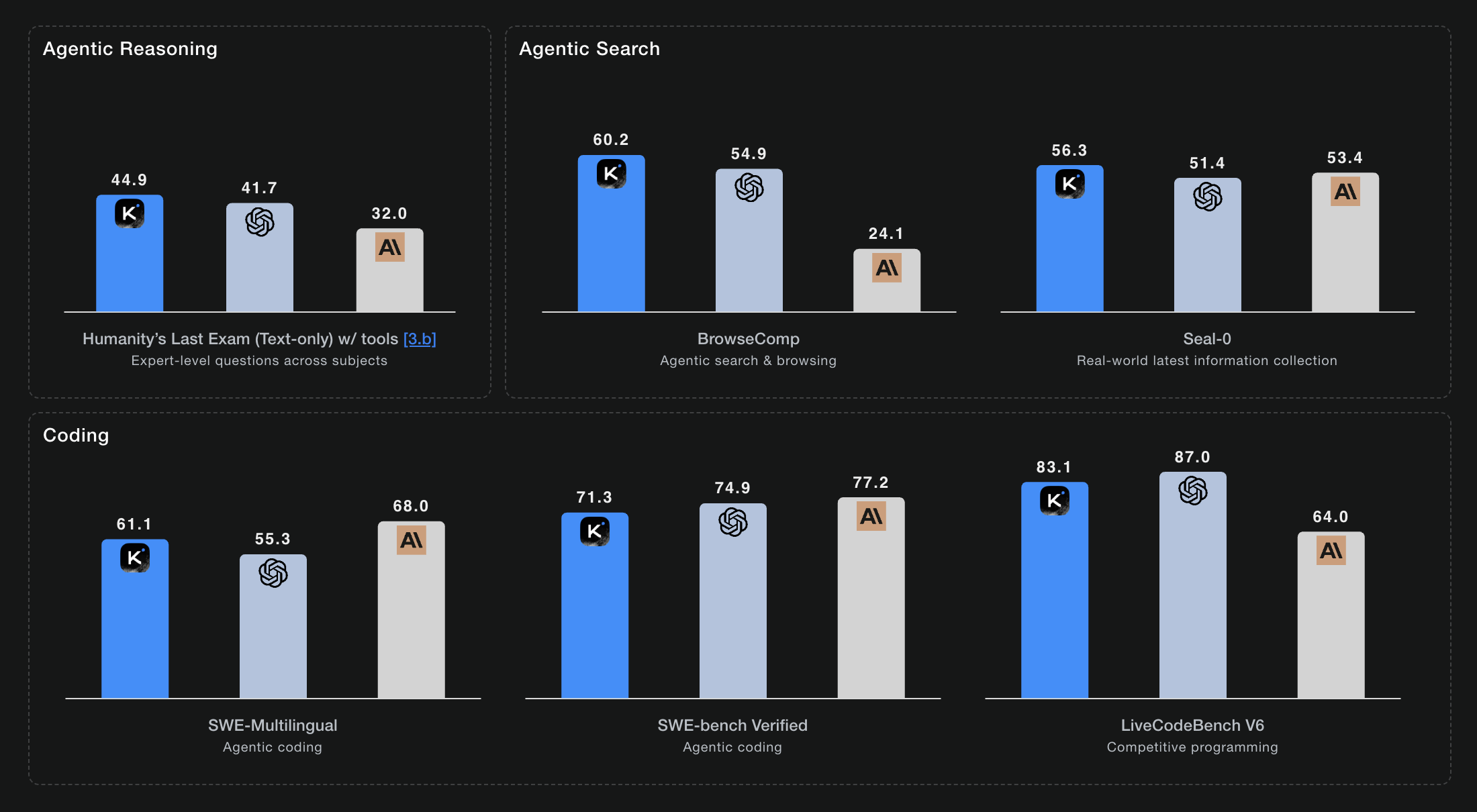
K2 Thinking achieves state-of-the-art results among open-source models:
Software Engineering:
- SWE-bench Verified: 65.8% → 71.6% (with multiple attempts)
- SWE-bench Multilingual: 47.3%
- LiveCodeBench: 53.7%
Agentic Tool Use:
- Tau2-Bench: 66.1% (multi-turn conversations with tool constraints)
- ACEBench: 76.5% (comprehensive tool learning)
Mathematics & Reasoning:
- AIME 2024 (competition math): 69.6%
- AIME 2025: 49.5%
- GPQA-Diamond (graduate-level science): 75.1%
- ZebraLogic (logic puzzles): 89.0%
General Capabilities:
- MMLU (knowledge): 89.5%
- IFEval (instruction following): 89.8%
- LMSYS Arena: #1 open-source, #5 overall
These results close the gap significantly with proprietary models like Claude 4 and GPT-4.1, especially on agentic and coding tasks.
What This Means for Open-Source AI
Kimi K2 represents a meaningful step forward in several areas:
Training at Scale: MuonClip proves you can train trillion-parameter models stably while being more token-efficient than traditional optimizers.
Synthetic Data Works: The agentic data synthesis pipeline demonstrates that large-scale simulation combined with real execution can produce training data that rivals human demonstrations.
Reasoning + Action: K2 Thinking shows that interleaving explicit reasoning with tool execution creates more robust agents than either approach alone.
Production-Ready: INT4 quantization with zero degradation makes trillion-parameter reasoning models deployable on reasonable infrastructure.
Known Limitations
The team was refreshingly honest about current weaknesses:
- Can generate excessive tokens on very hard problems (leading to truncation)
- Tool use may hurt performance on simple tasks that don't need it
- Better in agentic frameworks than single-shot prompting for complex projects
These are honest engineering tradeoffs. The model is optimized for complex, multi-step tasks, not quick lookups.
Use Cases
K2 Thinking is particularly well-suited for:
- Software development: Multi-file codebases, debugging, testing
- Research assistance: Literature review, data analysis, hypothesis formation
- Complex planning: Tasks requiring 50+ steps with error recovery
- Multi-tool workflows: Combining search, code execution, API calls, data processing
Conclusion
Open-sourcing both the base and reasoning-optimized models means researchers and practitioners can:
- Study the complete training pipeline from pre-training through reasoning
- Fine-tune for domain-specific applications
- Build on proven architectural decisions
- Validate or improve upon their methodologies
From a practical perspective, K2 Thinking is the most capable open-source model for agentic workloads. If you're building AI systems that need to autonomously navigate complex, multi-step problems, this should be on your evaluation list.
The quantization work alone makes it deployable where other trillion-parameter models wouldn't fit, and the attention to training stability means researchers can actually iterate without constantly restarting training runs.
What's exciting isn't just that it achieves strong benchmarks: it's that the entire approach is documented, reproducible, and open for the community to build upon.
Resources:
- Technical Report: arXiv:2507.20534
- Model Weights: HuggingFace - Kimi-K2-Instruct
- Thinking Mode: moonshotai.github.io/Kimi-K2/thinking.html


