From Turn 1 to Turn 10: How LLMs Get Lost In Multi-Turn Conversations

Real-world interactions between humans and LLMs are rarely single‑shot. Rather, users start with vague requests, iterate, clarify, and refine over multiple turns. Yet, most LLM benchmarks assume a fully‑specified, single‑turn setting which is different from how people actually chat. Prior analyses of conversation logs confirm that underspecification (i.e. missing details) in user instructions is to blame.
The authors in a recent paper argue that this mismatch between evaluation and practice hides a critical weakness: LLMs often lose track of evolving requirements across turns. In short, if a model takes a wrong turn, it seldom recovers, leading to cascading errors.
Sharded Simulation: A Controlled Experiment on Multi‑Turn Degradation
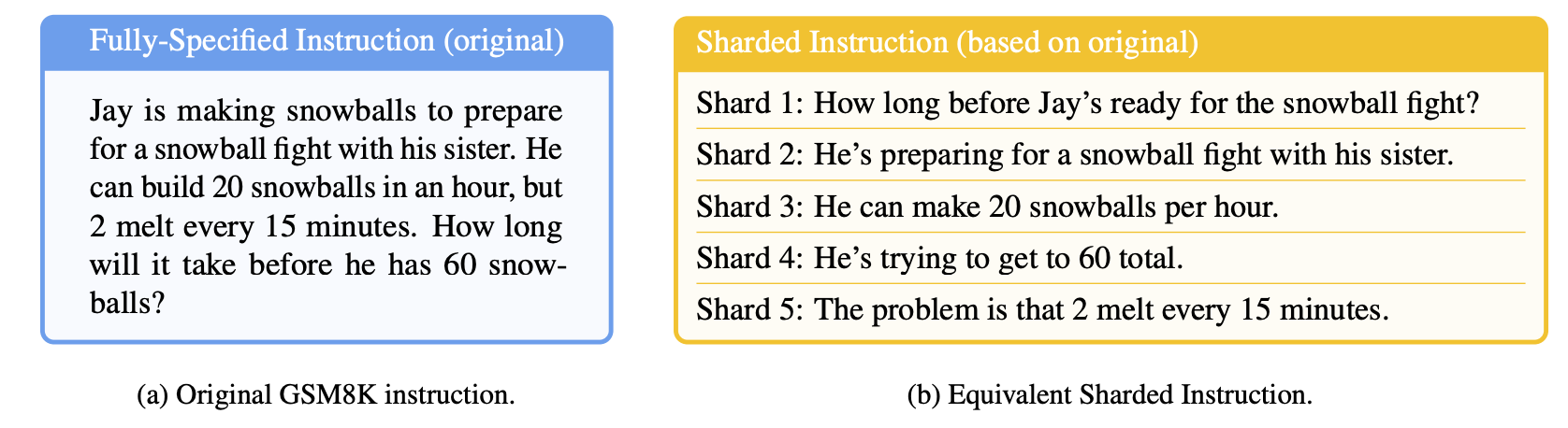
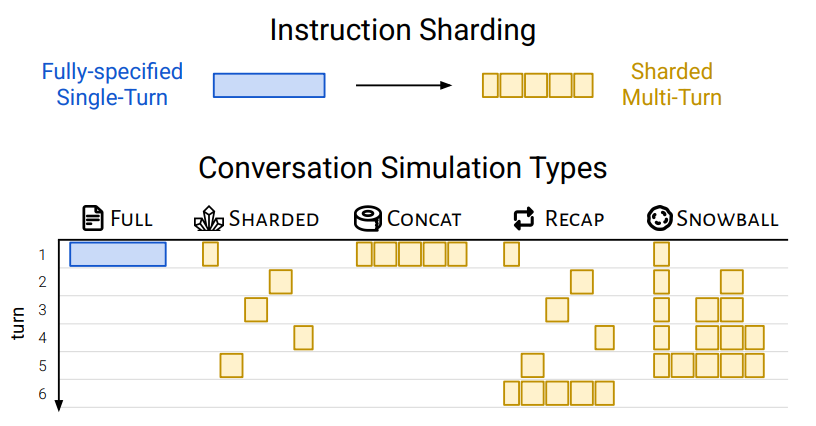
To quantify this effect at scale, the paper introduces Sharded Simulation, which transforms any single‑turn benchmark instruction into a sequence of smaller shards (which delays the instruction giving preserving semantic meaning). Let’s dive deeper into the method:
- Sharding splits a fully‑specified prompt into a set of atomic pieces (shards).
- A user‑simulator then reveals one shard per turn, mimicking a user who gradually discloses requirements.
- The LLM under test responds each turn and whenever it emits a final answer attempt, an extractor pulls out the candidate solution and scores it.
This setup helps compare three regimes on the same tasks:
- FULL: original instruction in one turn
- CONCAT: all shards concatenated into bullets in one shot
- SHARDED: true multi‑turn, one‑shard‑per‑turn reveal
By holding content constant, any performance drop in sharded versus concat isolates the cost of underspecification + multi‑turn context.
Tasks, Metrics, and Scale
Six Diverse Generation Tasks
The authors cover programming and NL domains:
| Task | Source Benchmarks | Output Type |
|---|---|---|
| Code | HumanEval, LiveCodeBench | Correct Python function |
| SQL (DB) | Spider | Correct SQL query |
| API Calls | BFCL | Semantically correct |
| Math | GSM8K | Numeric answer |
| Data-to-Text | ToTTo | BLEU-scored caption |
| Summary | Haystack | LLM-judged summary |
Performance and Reliability Metrics
Each (model, instruction, regime like sharded/full/concat) is simulated 10 times ****(with temperature=1.0) to capture variability. From the 10 scores they derive:
- P (Average): Mean score over 10 trials.
- A (Aptitude): 90th‑percentile score.
- U (Unreliability): 90th – 10th percentile gap.
Key Findings
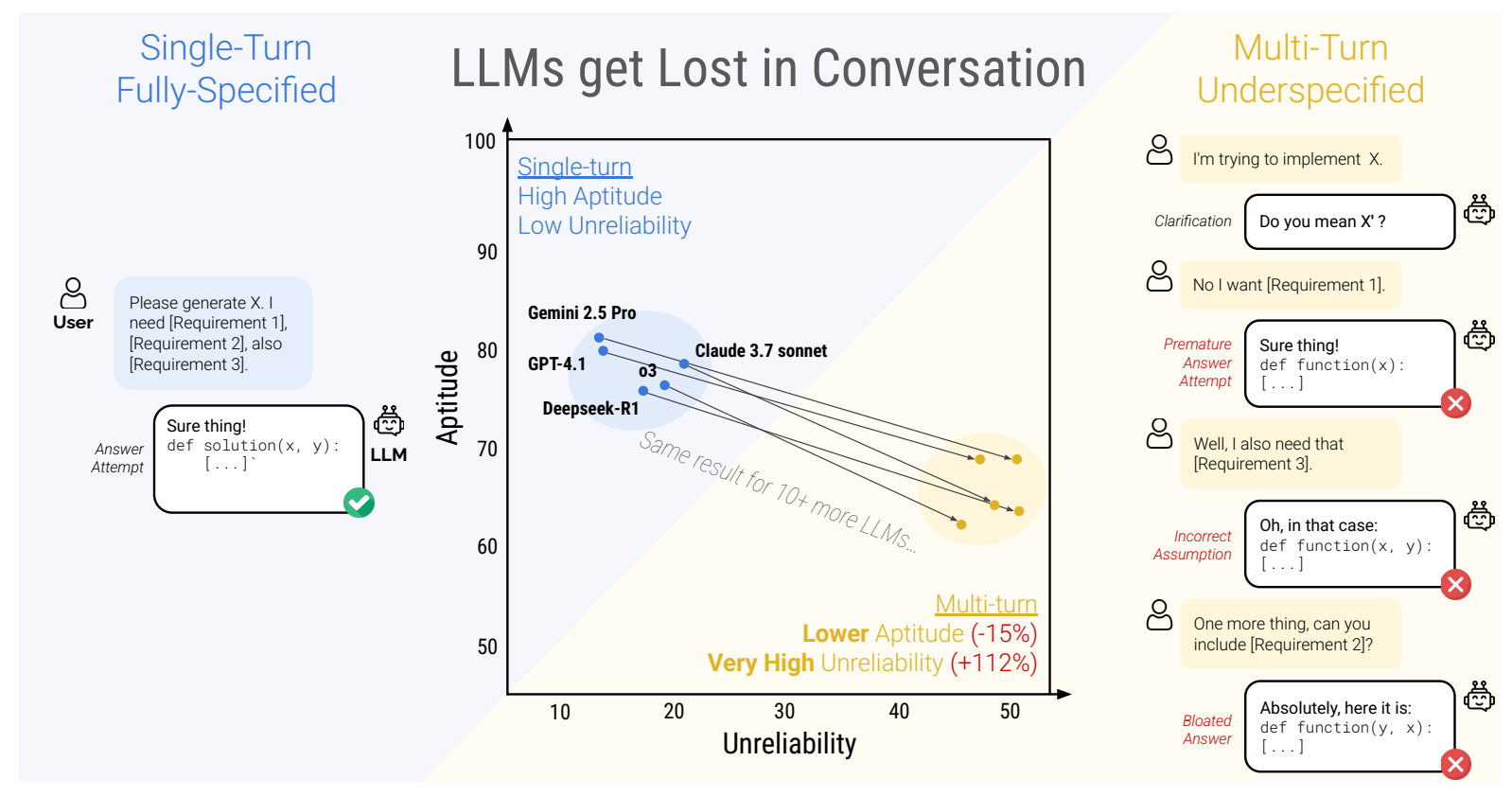
A ~39 % Drop in Average Performance
Across 15 top LLMs (GPT series, Gemini, Claude, Llama, OLMo, Phi, Deepseek), sharded performance plummets on average from ~90 % (FULL) to ~55 % which is a 39 % decline.
Unreliability Skyrockets
While aptitude (A) drops modestly (~15 %), unreliability (U) more than doubles (+112 %) in the responses. In multi‑turn, the gap between a model’s best and worst runs can exceed 50 points, meaning a single user session might swing from success to failure purely by chance.
Even Top Models Get Lost
Models like GPT‑4.1, Claude 3.7 Sonnet, and Gemini 2.5 Pro see just as severe multi‑turn drops as smaller or open‑weight models. In practice, no model yet handles underspecified, multi‑turn reliably.
Unpacking the Failure Modes
Qualitative analysis of >200,000 simulations surfaced four root behaviors:
- Premature Answer AttemptsModels often latch onto early shards and propose full solutions far too soon.
- Over‑Reliance on Their Own MistakesOnce an incorrect answer appears, the model repeatedly builds on it (“bloated” answers) instead of backtracking.
- Forgetting Middle TurnsThey heavily weigh the first and last shard, neglecting intermediate clarifications (a “loss‑of‑middle‑turns” effect).
- Verbosity Breeds AssumptionsLong, unfocused responses introduce spurious assumptions, further derailing context tracking.
Mitigations Explored
Agent‑Style Recap & Snowball
- RECAP: after the last shard, restate all prior user turns in one bullet list.
- SNOWBALL: at each turn, repeat all previous shards before adding the new one.
Both help somewhat (~15–20 % gain over plain sharded), but still fall short of full/concat.
Lowering Temperature
Dropping generation temperature to 0.0 barely reduces multi‑turn unreliability (remains ~30 points).
Tiny token‑level nondeterminism compounds drastically over turns.
Practical Takeaways
- For LLM Builders:
- Optimize multi‑turn reliability, not just single‑turn aptitude.
- Aim for U₉₀₋₁₀ < 15 points at T=1.0 across multi‑turn scenarios.
- For App Developers/Agents:
- Don’t assume LLMs will remember across many turns i.e. consider pre‑ or post‑processing (e.g., dynamic recaps), but know these are only partial fixes.
- For End Users:
- Start a fresh chat when things derail.
- Consolidate all dispersed requirements into one clear prompt (e.g., via “Please summarize what I’ve told you so far”) and re‑issue it to remind and help the LLM.
Conclusion
The Lost in Conversation phenomenon uncovers a fundamental gap between how LLMs are evaluated and how they’re used. As LLMs become woven into real‑world tools, native multi‑turn robustness must become a first‑class design objective. Otherwise, even the smartest models will repeatedly lose their way whenever instructions are underspecified.
Read the full preprint for all experimental details, appendices, and code release: https://arxiv.org/abs/2505.06120v1


