DiTTo-TTS: The TTS System That Doesn't Need Your Phonemes (And Why That's a Big Deal)

Text-to-speech has always been that one AI domain where you couldn't just throw data at the problem and call it a day. “Data is the moat” is straight up not a thing here. Want to build a TTS system? Better get comfortable with phonemizers, forced aligners, duration predictors, and a preprocessing pipeline that may give more plumbing than machine learning. TLDR: not a straightforward job. But sometimes, progress doesn’t come from adding complexity, but from stripping it away. DiTTo-TTS is Occam’s razor in action.
Researchers from KRAFTON and NVIDIA just published DiTTo-TTS at ICLR 2025 (Spotlight paper, by the way!), and it's basically the TTS equivalent of someone walking into a Michelin-star kitchen and making a better dish with half the ingredients.
The headline: They achieved state-of-the-art zero-shot TTS performance without using phonemes or phoneme-level durations. At all. And they trained it on 82K hours of speech across 9 languages with a model that scales up to 790M parameters.
Let me explain why this matters more than it might initially seem.
The Phoneme Problem (Or: Why TTS Has Been Weirdly Complicated)
Here's the traditional TTS pipeline that everyone's been using:
- Convert text to phonemes (because "tough" and "though" need different sounds)
- Predict how long each phoneme should last
- Align everything so speech and text sync up properly
- Generate the actual audio
- Hope nothing breaks along the way
This works, but it's a nightmare for scaling. Every new language needs a new phonemizer. Every dataset needs careful alignment. Your data preparation becomes more complex than your actual model training. It's the machine learning equivalent of needing a PhD to assemble IKEA furniture.
The researchers asked a simple question: Can we just... not do all that?
After all, image generation models don't need "image phonemes." Video models don't predict "frame durations." They just learn from raw data. Why should TTS be different?
The Core Insight: Let Diffusion Handle the Details
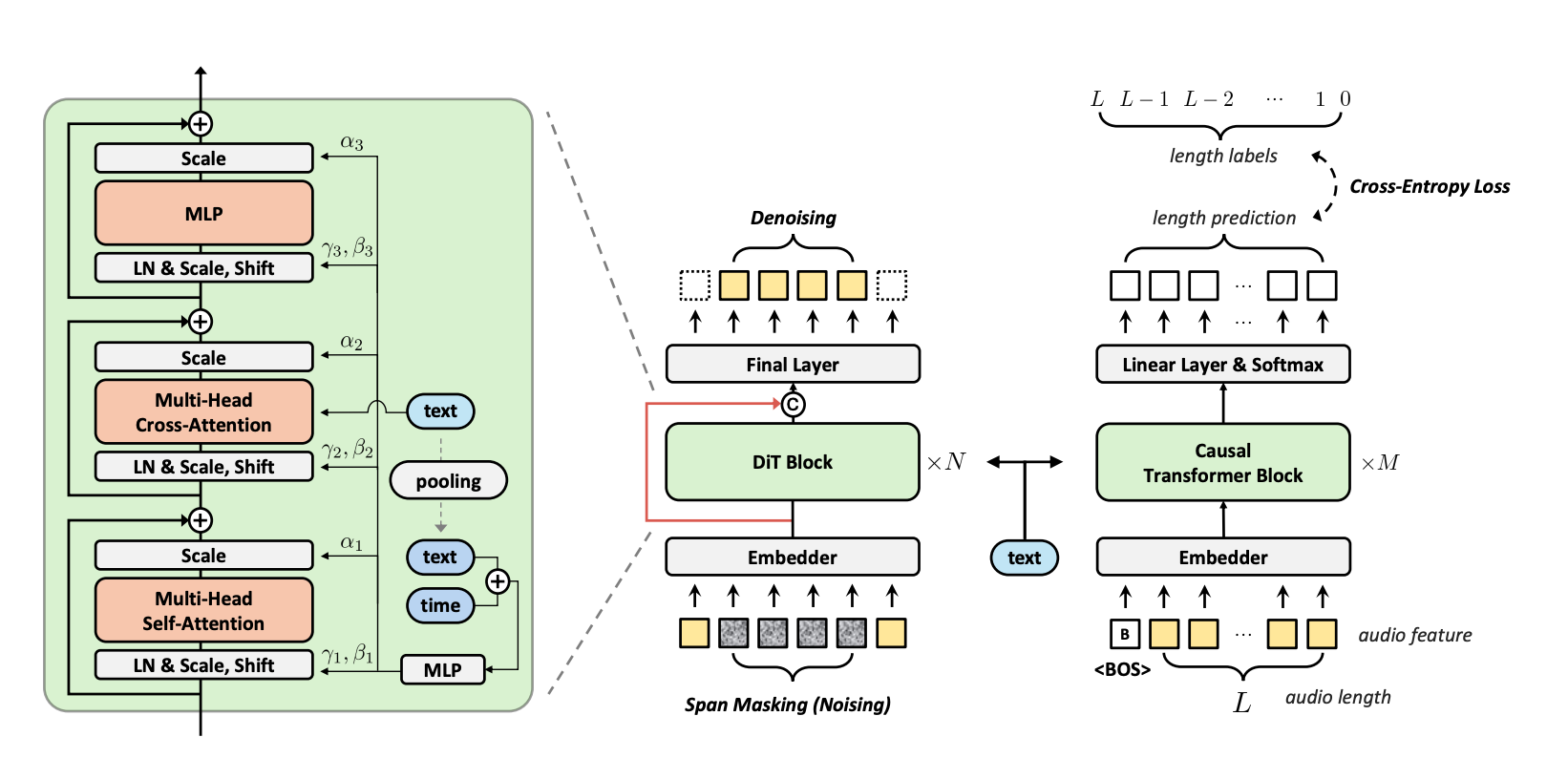
DiTTo-TTS is built on a deceptively simple architecture that does three things really well:
1. Diffusion Transformers Over U-Nets
Most diffusion-based TTS systems use U-Net architectures because, well, that's what worked for images. DiTTo shows that Diffusion Transformers (DiT) are actually better for speech.
The key difference? U-Nets do downsampling and upsampling, which loses information in the highly compressed latent space that speech requires. DiT's flat architecture (no down/upsampling) preserves that information better.
They also add minimal but crucial modifications: long skip connections (borrowed from U-Net's playbook) and global adaptive layer normalization. The result: DiTTo-Base (152M parameters) outperforms CLaM-TTS (584M parameters) while being 4.6× faster at inference.
2. Variable-Length Modeling (Because Not Everything Should Be Fixed)
Previous "simple" diffusion TTS models used fixed-length generation with padding. Generate 20 seconds of audio, pad the rest, hope for the best. It's like buying a one-size-fits-all shirt and wondering why it never quite fits.
DiTTo introduces a Speech Length Predictor: a separate encoder-decoder transformer that predicts the total speech length based on the input text and speech prompt. No individual phoneme durations. Just: "This sentence will take about 5 seconds to say."
The improvement is substantial. Fixed-length models get WER scores around 6.81-8.89%. Variable-length modeling? 5.58%. And as a bonus, you get speech rate control for free: just adjust the predicted length and the model naturally speeds up or slows down, it’s an (almost) free lunch situation.
3. Semantic Alignment (The Secret Sauce)
Here's where it gets interesting. DiTTo uses cross-attention to condition on text embeddings. But cross-attention only works well if your text and speech representations are in similar semantic spaces.
The researchers discovered two approaches that work:
- Option A: Use a text encoder that was jointly trained with speech data (like SpeechT5)
- Option B: Fine-tune your audio codec with an auxiliary language modelling objective
They went with Option B, creating Mel-VAE++: a neural audio codec that's fine-tuned to align its speech latent representations with a pre-trained language model. The codec learns to create speech representations that "speak the same language" as text embeddings.
The results validate the approach dramatically. Models using aligned representations achieve WER of 2.93% vs 6.22% for unaligned versions. That's not an incremental improvement, that’s a qualitative difference.
Why Mel-VAE? (A Brief Detour Into Codec Wars)
DiTTo uses Mel-VAE as its audio codec instead of popular alternatives like EnCodec or DAC. Why?
Compression ratio matters. Mel-VAE compresses audio about 7-8× more than EnCodec, resulting in ~10.76 Hz latent codes. This means:
- Shorter sequences to process (faster training and inference)
- More efficient use of transformer context windows
- Better performance despite slightly lower codec quality metrics
When they tested DiTTo with EnCodec, WER jumped to 4.19%. With DAC at 44kHz? A disastrous 14.58%. Mel-VAE's aggressive compression is actually a feature, not a bug.
The principle: for generative modeling, a shorter, semantically meaningful latent is worth more than a longer, acoustically perfect one.
The Results: Actually State-of-the-Art
Let's talk numbers, because they're impressive:
English Continuation Task (LibriSpeech test-clean):
- DiTTo-en-XL: 1.78% WER, 0.6075 speaker similarity
- CLaM-TTS: 2.36% WER, 0.5128 speaker similarity
- Voicebox: 2.0% WER, 0.616 speaker similarity
- Ground Truth: 2.15% WER (yes, DiTTo beats ground truth on WER)
Cross-Sentence Task:
- DiTTo-en-XL: 2.56% WER, 0.6554 speaker similarity
- Simple-TTS: 4.09% WER, 0.5305 speaker similarity
- Voicebox: 1.9% WER, 0.681 speaker similarity
Human Evaluation (SMOS for speaker similarity):
- DiTTo-en-XL: 3.91/5.0
- Ground Truth: 4.08/5.0
- CLaM-en: 3.42/5.0
The model is basically indistinguishable from ground truth in blind listening tests. And remember: it's doing this without phonemes, without duration predictors, without forced alignment.
The Scaling Story
One of the paper's most compelling contributions is showing that this approach actually scales:
Model Size Scaling: Performance improves consistently from Small (42M) → Base (152M) → Large (508M) → XLarge (740M). This isn't just "bigger is better": it's evidence that the architecture has room to grow.
Data Scaling: They train on subsets ranging from 0.5K to 50.5K hours. Performance improves steadily with more data, suggesting they haven't hit a ceiling yet.
Multilingual Scaling: DiTTo-multi (790M parameters) handles 9 languages effectively, showing the approach generalizes across linguistic boundaries.
This is important because it means the architecture is future-proof. As compute and data increase, DiTTo-style models should continue improving.
What They Actually Figured Out (The Takeaways)
The paper sought to answers two research questions definitively:
RQ1: Can LDMs achieve SOTA TTS without domain-specific factors?
Yes. Emphatically yes.
RQ2: What makes it work?
Three things:
- Architecture matters: DiT > U-Net for speech, but you need long skip connections and global AdaLN
- Length modelling matters: Variable-length generation with total length prediction crushes fixed-length approaches
- Alignment matters most: Text and speech representations need to be in similar semantic spaces, achievable through either joint training or semantic injection
The Broader Implications
DiTTo-TTS isn't just "another TTS system." It represents a paradigm shift:
For Researchers: You can now treat TTS like image generation. Use the same diffusion techniques, the same scaling laws, the same architectural innovations. The field-specific complexity is gone.
For Practitioners: Data preparation just got 10× simpler. No more phonemizers breaking on edge cases. No more language-specific alignment models. Just text and audio.
For the Field: TTS can now benefit from advances in other generative modeling domains. New diffusion techniques from computer vision? They'll probably work here too. Architectural innovations from video generation? Worth trying.
The "Yeah, But..." Section
Of course, no paper is perfect:
Inference Speed: While faster than autoregressive models, 25-step diffusion isn't exactly real-time. The authors suggest DDIM sampling and model optimization as paths forward.
Codec Dependency: The whole approach hinges on having a good neural audio codec. If Mel-VAE quality degrades, so does DiTTo.
Voice Cloning Ethics: Zero-shot voice cloning is powerful but dangerous. The paper acknowledges this, but detection and regulation remain open problems.
The Technical Deep Dive (For the ML Nerds)
A few implementation details worth noting:
Training Setup: They use v-prediction (instead of noise or x0 prediction) with span masking borrowed from Voicebox. Random segments of 70-100% are masked, allowing the model to learn infilling naturally.
Classifier-Free Guidance: CFG scale of 5.0 with noise schedule shift-scale of 0.3. These hyperparameters matter. Wrong settings tank performance.
Global AdaLN: Sharing AdaLN parameters across all layers (instead of per-layer) reduces parameters by 30.5% while improving performance. Sometimes less is more.
RoPE + Gating: They use rotary position embeddings (RoPE) in self-attention and gating mechanisms in MLP blocks (borrowed from Gemma). Modern architecture tweaks matter.
Why This Matters Now
We're at an inflection point in TTS research. For years, the field has been constrained by the belief that domain-specific factors are necessary. DiTTo proves they're not.
This opens the floodgates. Expect to see:
- TTS models trained on even larger, noisier datasets (because preprocessing is simpler)
- Architectural innovations from other modalities applied directly to speech
- Multilingual models that don't need per-language phonemizers
- Faster iteration cycles for researchers
The barrier to entry for TTS research just dropped significantly.
The Bottom Line
DiTTo-TTS achieves state-of-the-art zero-shot text-to-speech without phonemes, without duration predictors, and without the complex preprocessing that has defined TTS for decades. It does this by:
- Using Diffusion Transformers with smart architectural choices
- Predicting total speech length instead of per-phoneme durations
- Aligning text and speech representations in semantic space
The result: a system that's simpler, faster, more scalable, and actually better than previous approaches. Occam’s razor for the win, indeed.
Check out the paper here: https://openreview.net/pdf?id=hQvX9MBowC


