Chain-Talker: Teaching AI to Speak with Empathy

When AI systems engage in conversation, getting the words right is only half the battle. The real challenge is emotional appropriateness: responding to "I just lost my job" with genuine sympathy rather than robotic cheerfulness, or matching enthusiasm when someone shares good news. Current conversational speech synthesis (CSS) models can generate natural-sounding speech, but they struggle with a fundamental problem: insufficient emotional perception and interpretability. When these systems choose an emotional tone, it's difficult to understand why they made that choice or how they're reasoning about conversational context.
That's the problem researchers from multiple institutions tackled with Chain-Talker, a new framework for empathetic conversational speech synthesis. Their key idea: what if we explicitly modelled emotional reasoning as separate stages, creating a system where every emotional decision is traceable and interpretable?
Empathy as a Chain of Thought
Chain-Talker's breakthrough is architectural and cognitive. Instead of one massive model doing everything at once, the system breaks empathetic speech generation into three sequential stages (Figure 1) that mirror how humans actually process conversations:
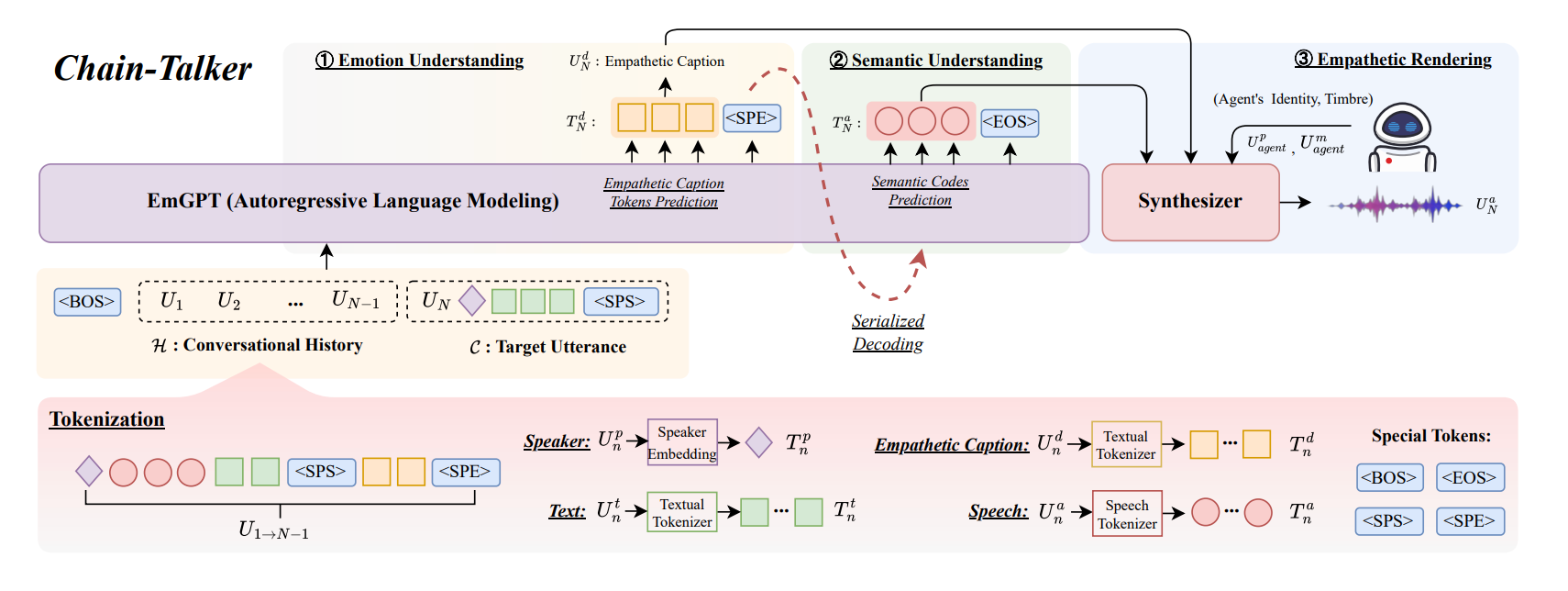
- Stage 1 - Emotion Understanding: Before saying anything, understand what emotional response is appropriate given the dialogue history. This stage uses a GPT-style language model (EmGPT) to derive context-aware emotion descriptors by analyzing the conversational context. Did the user just share good news? Are they frustrated? Confused? Excited? The model generates empathetic captions, ie: tokens that articulate the emotional style to adopt, like "gently sympathetic," "some sadness but hopeful," or "light reassurance." These captions are trained via a cross-entropy loss on approximately 384 hours of annotated conversational data.
- Stage 2 - Semantic Understanding: Once you know how to respond emotionally, figure out what to say. This stage generates compact semantic codes through serialized prediction: token-by-token generation conditioned on the dialogue history, current utterance, and the emotion descriptor from Stage 1. These codes represent the linguistic content efficiently without redundancy, unlike traditional discrete coding approaches. By keeping semantic and acoustic information disentangled, the system avoids encoding every acoustic detail at this stage. A cross-entropy loss trains correct semantic code prediction.
- Stage 3 - Empathetic Rendering: Finally, synthesize the actual speech by combining the emotion descriptors and semantic codes. This stage uses an Optimal-Transport Conditional Flow Matching (OT-CFM) model as its backbone, which treats synthesis as a continuous flow from noisy to clean Mel spectrogram. The flow model is conditioned on emotion descriptors, semantic codes, and speaker embeddings, and trained via a flow-matching loss . The final waveform is generated using a standard neural vocoder like HiFi-GAN. This is where voice timbre, prosody, pitch, and all the acoustic details come together to produce speech that is both accurate and emotionally appropriate.
The elegance here is in the separation of concerns. By explicitly modelling emotion understanding before semantic encoding, and both before acoustic rendering, Chain-Talker achieves something most CSS systems don't: interpretability.
Why Sequential Processing Matters
The decision to use three stages instead of end-to-end generation is crucial and mirrors a broader trend in AI: sometimes explicit reasoning beats black-box optimization.
Consider what happens in a monolithic, non-reasoning system when processing this exchange:
User: "My presentation went terribly today."
Agent: "That's interesting! Tell me more!"
The model generates technically correct speech with completely inappropriate enthusiasm. Why? Because in traditional CSS systems, given dialogue context and prompt, they directly predict acoustic tokens or spectrograms. Emotional reasoning is implicitly entangled in massive neural weights, making it opaque and hard to debug. The model never explicitly reasoned about the emotional context before jumping to synthesis.
Chain-Talker's Sequential Solution:
- Emotion Understanding Module: Ingests the dialogue history (previous turns, both text and speech features) plus the current user utterance. EmGPT analyzes this context, recognizes distress/disappointment, and generates descriptors like [sympathetic, supportive, gentle].
- Semantic Encoding Module: Given those emotional cues, produces semantic codes that represent an appropriate response like "I'm sorry to hear that. What happened?" These codes capture what should be said without mixing in acoustic detail.
- Empathetic Rendering Module: Takes the emotion descriptors and semantic codes to synthesize speech with appropriate sympathetic tone, slower pace, and softer cadence. Because acoustic rendering is decoupled from semantic reasoning, the system has a clean interface: you supply desired emotional style plus content, and the renderer focuses purely on execution.
This chain-of-thought approach makes the system's decisions transparent. You can inspect the emotion descriptors at each stage and understand why the system chose a particular speaking style. That structure gives two big advantages: interpretability (you can inspect the emotion descriptors to see why the system chose sympathetic versus upbeat) and modularity (you could, in principle, intervene or adjust one stage without retraining the whole pipeline).
The Compact Coding Advantage
One of Chain-Talker's technical innovations is moving away from redundant discrete speech coding. Traditional CSS models often use large codebooks with massive vocabulary sizes, creating sequences that are computationally expensive and informationally redundant.
Chain-Talker's semantic understanding stage uses serialized prediction to generate compact semantic codes. This means that you don't need to encode every acoustic detail at every stage. Separate what needs to be said (semantic content) from how it needs to sound (acoustic rendering).
This is similar to how humans process speech. We don't think about every phoneme and pitch contour when planning what to say. We first figure out the message, then the delivery. Chain-Talker's architecture reflects that cognitive separation, keeping semantic and acoustic information disentangled throughout the pipeline.
The Data Challenge and CSS-EmCap
One major hurdle for emotion-aware CSS is getting good data with emotion labels. Chain-Talker addresses this through the CSS-EmCap pipeline: an automatic annotation system that takes several existing CSS datasets (like NCSSD, MultiDialog, and DailyTalk) and automatically generates emotional captions using a prompt-driven large language model.
These labels are used for training the Emotion Understanding stage, with the total annotated data comprising approximately 384 hours of conversational speech. The training itself is multi-stage: first pretraining EmGPT on large single-sentence speech corpora, then fine-tuning on annotated conversational dialogue to learn caption prediction and semantic codes, and finally training the OT-CFM rendering model with the semantic and emotion inputs.
Results
The paper includes both objective metrics and subjective human evaluations, and Chain-Talker consistently outperforms baseline CSS models across the board.
Objective improvements:
- Dynamically-aligned pitch distance (DDTW): Chain-Talker achieves significantly lower DDTW scores, indicating better prosodic alignment.
- SSIM on spectrograms: Higher scores show that generated speech is closer to ground truth in structure.
- ACCm (emotion content alignment): Higher scores demonstrate that the emotional style is better matched to context.
- Better alignment between synthesized emotional tone and conversational context, more appropriate prosodic variation, and improved naturalness scores overall.
Subjective evaluation:
Human listeners rate Chain-Talker significantly higher in naturalness and expressiveness/empathy, with gains of approximately 0.1–0.2 MOS (Mean Opinion Score) over strong baselines. When people hear the synthesized responses, they actually feel like the AI "gets it."
Interpretability wins:
Because the emotion understanding stage is explicit, researchers can analyze which contextual cues drive different emotional responses. The system also demonstrates better emotion controllability: when you vary the emotion descriptor, the rendered speech changes more responsively. This makes the system debuggable and improvable in ways black-box models aren't.
Why Empathy Matters in Speech Synthesis
This isn't just an academic exercise. Empathetic conversational speech has real-world implications:
Mental health applications: Therapeutic chatbots and support systems need to respond with appropriate emotional sensitivity. Getting the tone wrong can actively harm vulnerable users.
Customer service: Automated support systems that sound genuinely helpful rather than robotically indifferent dramatically improve user experience and resolution rates.
Accessibility tools: For users who rely on text-to-speech systems for communication, having synthesized speech that conveys appropriate emotion is crucial for social interaction.
Education: Virtual tutors and learning assistants are more effective when they can respond with encouragement, patience, or gentle correction as the situation demands.
The broader point: as AI systems become more conversational, emotional intelligence becomes a P0 feature, not a nice-to-have.
The Broader Context: Cognitive Architecture in AI
Chain-Talker sits within a growing movement toward more structured, interpretable AI systems. We've seen similar patterns emerge across domains:
- Chain-of-thought prompting in large language models
- Hierarchical planning in robotics
- Multi-stage reasoning in visual question answering
The common thread: explicit reasoning steps often outperform end-to-end learned mappings, especially when interpretability and controllability matter. Chain-Talker applies this principle to speech synthesis. Rather than hoping a massive neural network will implicitly learn to model emotional context, they build it into the architecture explicitly. The result is a system that's both more effective and more transparent.
Limitations
Like most research advances, Chain-Talker isn't perfect. The main limitations are practical:
Inference complexity: Three sequential stages means three forward passes through different models. This adds latency compared to single-stage systems. The authors report an average response time of approximately 2.5 seconds on a powerful GPU setup, which is acceptable for many applications but still lags behind real-time agents. Real-time or low-latency versions would require optimizing or merging stages, or adopting streaming architectures.
Emotion modelling depth: While the emotion understanding stage is a significant improvement, emotion is complex and multidimensional. Current descriptors are discrete captions that might not capture subtle emotional nuances, mixed emotions, cultural variations in emotional expression, or complex states like sarcasm and irony. The system assumes the emotion prediction is correct, so mispredictions may propagate downstream.
Training data requirements: Building effective emotion understanding requires well-annotated conversational data with emotional labels. The conversational fine-tuning data (approximately 384 hours) is relatively limited and potentially skewed, eg. it has mostly young speakers. This means it may not generalize well to voices of children, elderly speakers, or across diverse domains. This annotation is expensive and potentially subjective.
Architecture rigidity: While the chain structure boosts interpretability, it also fixes a rigid pipeline. Errors or biases in early stages cannot be easily overridden unless you redesign interfaces between modules. Flexible end-to-end systems might adapt in unstructured ways the chain model cannot.
Safety concerns: Because Chain-Talker supports zero-shot speech synthesis, it can generate personalized voices for unseen speakers. This opens risks for voice spoofing or misuse. The authors propose license-level restrictions to mitigate this threat.
But these are engineering challenges, not fundamental limitations. The architectural insight (that empathetic speech synthesis benefits from explicit cognitive stages) remains sound.
The Takeaway
Chain-Talker demonstrates three key principles for building more human-like conversational AI:
- Explicit emotional reasoning beats implicit learning: Don't hope your model will figure out empathy on its own. Build emotion understanding into the architecture. The EmGPT module proves that making emotion prediction a first-class concern improves both performance and interpretability.
- Sequential processing enables interpretability: Breaking complex tasks into stages makes systems debuggable and improvable. You can analyze and improve each component independently. The three-stage architecture allows researchers to inspect emotion descriptors, semantic codes, and acoustic rendering separately.
- Efficient representations matter: Compact semantic codes reduce computational burden while maintaining expressiveness. Not everything needs to be encoded at every stage. Disentangling semantic content from acoustic detail mirrors human cognitive processing and improves system efficiency.
For researchers working on conversational AI, dialogue systems, or multimodal generation, Chain-Talker offers a compelling proof of concept. The empathy that comes naturally to humans might require explicit architectural choices in AI systems.
And perhaps that's the deeper lesson: as we build AI systems that interact with humans in increasingly natural ways, we need to think carefully about cognitive architecture, not just model capacity. Chain-Talker echoes a broader AI design philosophy: don't hide reasoning in a monolith, but build structured, inspectable modules.
For real-world deployment, Chain-Talker won't be the final answer. We'll need more data, smarter emotion models, efficiency improvements, and robust safety guardrails to productionize this. But as a proof of concept, it shows that empathy in conversational speech is not just about scale or data: it's about the right structure.
Maxim’s Voice simulation allows you to test how your AI agent handles voice interactions, ensuring natural conversations and appropriate responses to different speech patterns, accents and scenarios. Get started with Voice Simulation on Maxim AI.
Check out the paper here: https://arxiv.org/pdf/2505.12597


