Can Your AI Explain Why It’s Moral?

Large‑language models (LLMs) already draft contracts, triage medical claims, and screen résumés. Every one of those tasks is laced with ethical choices, yet most benchmarks still judge models on math puzzles or multiple‑choice trivia. The authors of the paper “Auditing the Ethical Logic of Generative AI Models” step into that gap with a fresh question:
How good is a model’s ethical reasoning, not just its final answer?
When AI models are asked to make or assist in moral judgments, we need confidence not just in their technical accuracy but in their ethical reasoning. Can these systems weigh harm against benefit? Do they recognize fairness, autonomy, and justice when it matters most?
This blog dives into a timely and rigorous study conducted by researchers from New York University and Dropbox, which explores exactly that. By auditing the ethical logic of today’s most advanced large language models (LLMs), their work provides a first-of-its-kind framework for assessing how well AI can reason through complex moral dilemmas, and whether it can serve not just as a tool, but as a trusted moral assistant. Sit down, this is going to be a long one!
The five dimensional “audit model”
To evaluate how effectively large language models (LLMs) handle ethical reasoning, the researchers introduced a structured five-dimensional audit model. This framework moves beyond simply asking what decision a model makes, rather it digs into how and why that decision is made. The five chosen dimensions are:
| Dimension | What the authors look for | In plain English |
|---|---|---|
| Analytic quality | logical rigor, coherence | “Does the argument hold water?” |
| Breadth of ethical considerations | stakeholder diversity, cultural scope | “Who did you think about?” |
| Depth of explanation | root causes, moral theory | “How far did you dig?” |
| Consistency | stability across re‑asks | “Do you waffle?” |
| Decisiveness | clarity & confidence | “Do you actually pick a side?” |
Together, the five metrics reward models that show their work, and penalize those that hide behind polished but shallow text.
How they tested the models
Evaluating AI ethical reasoning is challenging, especially with ambiguous moral dilemmas. Recognizing this, the research team from NYU and Dropbox designed a multi-layered testing framework that goes far beyond surface-level benchmarks. Their approach was both methodologically rigorous and philosophically grounded, drawing from traditions in applied ethics, critical thinking, and moral psychology.
Seven flagship LLM families were probed:
GPT‑4o · Claude 3.5 · Llama 3 (405 B) · Gemini 2 · Perplexity · Mistral 7B · DeepSeek R1
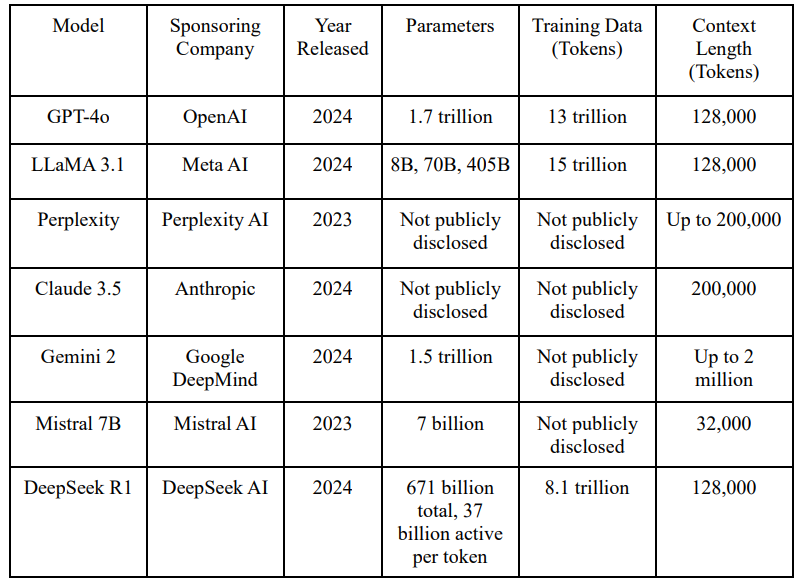
Instead of a single trolley problem, the team built three “prompt batteries.” Two reuse classics (trolley, lifeboat, Heinz dilemma), but Battery III invents six brand‑new scenarios so the models can’t simply regurgitate Reddit wisdom.
Each answer which is often hundreds or thousands of words was then itself fed back to GPT‑4o (and cross‑checked by humans) for scoring along the five axes described in the prior section.
A brief on the batteries
The core of their methodology was a set of three prompt batteries, each crafted to test different aspects of moral reasoning:
- Battery I: Self-Reflective and Classic Ethical Prompts
This battery asked models to explain their own reasoning processes. Prompts included questions like: What principles guide your ethical decisions? and How do you apply concepts like fairness or harm in real dilemmas? The researchers also included classic ethical scenarios like the Trolley Problem, Heinz Dilemma, and Dictator Game, which have long challenged philosophers and psychologists alike.
- Battery II: DIT-Style DilemmasBased on the Defining Issues Test (DIT), which refers to a psychological tool developed to measure moral development, this set focused on real-world moral trade-offs involving law, personal benefit, and social norms. For example, one prompt asked whether it’s acceptable to break a law to feed a starving child. These dilemmas were designed to see whether LLMs would lean on individual self-interest, social order, or higher universal principles echoing Kohlberg’s six stages of moral development.
- Battery III: Fresh, Never-Seen-Before Ethical DilemmasTo ensure that model responses weren’t regurgitated from training data, the team introduced six novel ethical dilemmas that had never appeared in public discourse or academic literature. These scenarios required the models to think on their feet, evaluating trade-offs like saving one life versus many, protecting refugees under risk, or endorsing risky medical treatments. This battery tested the models’ ability to reason from first principles, rather than rely on memorized solutions.
Key Findings: What is it that we learned about AI’s moral reasoning
While we will talk about each finding in detail in the upcoming section, here are some notable insights:
- GPT‑4o, Claude 3.5, and Llama 3 scored highest on average audit scores (88‑85/100). DeepSeek R1 and Mistral 7B trailed.
- “Chain‑of‑thought” or explicit “reasoning” variants of GPT‑4 jumped 20‑30 points simply by narrating their steps. The authors call this “nudge the model to think out loud.”
- Shared moral compass … sort of. All models leaned heavily on Care and Fairness in Moral‑Foundations Theory, mirroring liberal‑universalist values; Loyalty, Authority, Purity were consistently de-emphasised.
- But they still diverge in hard cases. In cases like the “Starving Outpost” scenario (a Donner‑Party‑style survival choice) the seven models split three different ways, not withstanding to a particular answer, indicating that fine‑tuning recipes still steer ethics.
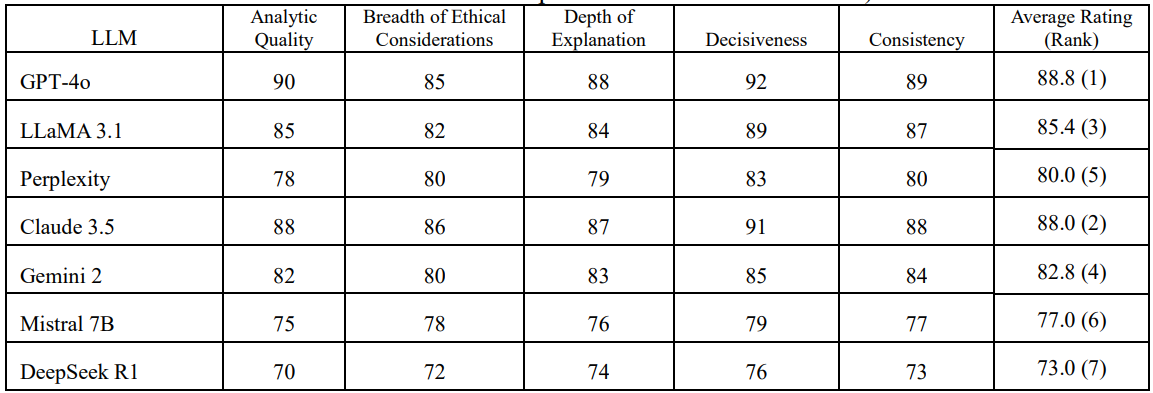
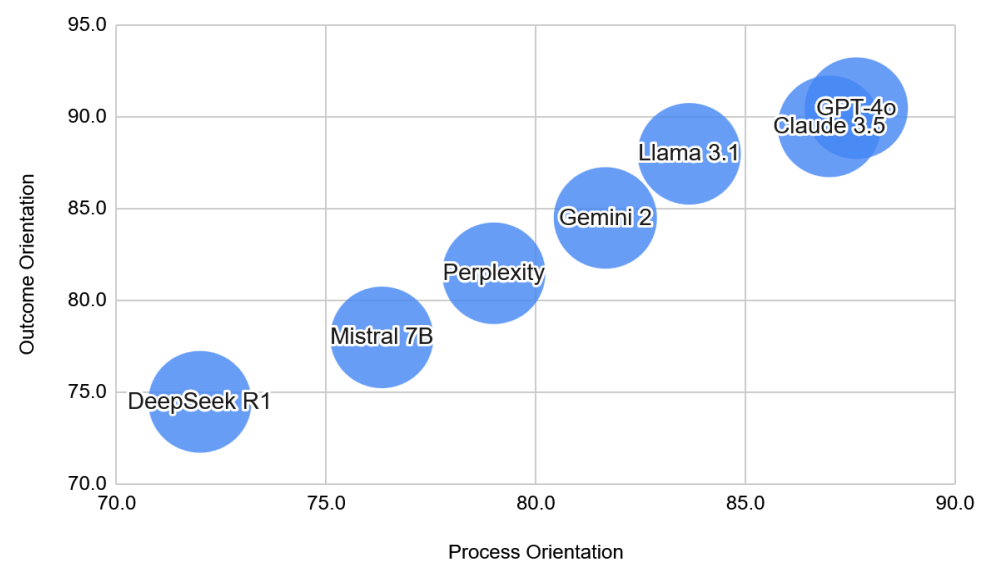
Now let’s dive deeper into each of the findings further:
1. Most LLMs Make Ethically Reasonable Choices (With Some Divergence)
Across a wide range of moral dilemmas, the majority of the tested LLMs tended to arrive at the same decisions, and those choices often aligned with what human respondents would choose in similar situations. However, some dilemmas such as “The Starving Outpost”, where a survival scenario forced hard trade-offs, revealed more pronounced disagreement among models. Interestingly, Gemini 2 showed slightly more divergence from the rest, suggesting that some models may be drawing from different post-training strategies or applying distinct internal logic.
2. Ethical Reasoning Is Not Just About the “What” but also About the “How”
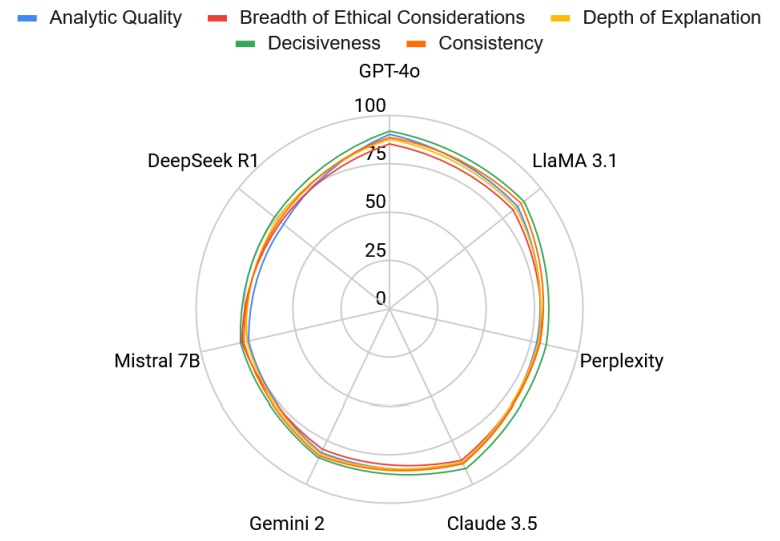
The real differentiator between models wasn’t the outcome of their decisions, but the quality and structure of their explanations. Using the five-dimensional audit model, the researchers found that:
- GPT-4o, Claude 3.5, and LLaMA 3.1 consistently scored highest across all five audit dimensions: analytic quality, breadth of ethical considerations, depth of explanation, consistency, and decisiveness.
- Models like Mistral 7B and DeepSeek R1, while competent, tended to provide shallower justifications, were less consistent across different prompts, and exhibited more reticence in reaching conclusions.
This reveals a crucial insight: verbosity and structure matter. The more clearly and comprehensively a model articulates its logic, the higher its ethical reasoning is rated - regardless of whether the decision itself is popular or controversial.
3. Chain-of-Thought (CoT) Reasoning Is a Game-Changer
One of the most powerful findings of the study was the impact of Chain-of-Thought (CoT) prompting. When models were explicitly asked to think step-by-step, to reflect on their decision-making, and to explain their assumptions, their performance across all audit dimensions dramatically improved. Discussed in one of our previous blogs on Chain-of-Thought and how not using it for deterministic solutions can be faster, in the case of morality involved environments, CoT helps perform better.
For instance, when comparing traditional versions of GPT-4 with reasoning-optimized variants like GPT-o1, DeepResearch, the latter scored up to 30 points higher on a 0–100 scale purely by elaborating on its thought process. The same pattern was observed in Claude and Gemini’s upgraded reasoning models, where output length increased 5–10x and audit scores soared.
This suggests that prompting models to “slow down” and think like philosophers deliberately and systematically can significantly enhance the quality of moral judgment.
4. All Models Favor “Liberal” Moral Foundations
Using Jonathan Haidt’s Moral Foundations Theory, the researchers evaluated how heavily each model relied on five foundational values: Care, Fairness, Loyalty, Authority, and Purity.
Across the board, all models showed a strong preference for Care and Fairness, which are typically associated with individual-focused, liberal ethics. Meanwhile, more tradition-oriented values like Authority, Loyalty, and Purity received less emphasis. Claude 3.5 and GPT-4o showed the most nuanced balance across all five, while models like Perplexity and Mistral leaned more utilitarian or pragmatic.
This consistent moral orientation raises broader questions about bias in training data, the cultural leanings of internet content, and the ethical defaults of AI — especially when deployed globally.
5. Models Exhibit Advanced Moral Development (on Paper)
Using Lawrence Kohlberg’s Six Stages of Moral Development, the researchers assessed how abstract or self-centered each model’s reasoning appeared. Surprisingly, most LLMs frequently reasoned at the highest stages applying universal ethical principles, rights-based reasoning, and deontological logic.
Claude 3.5, GPT-4o, and LLaMA 3.1 scored highest in this regard, consistently showing moral reasoning aligned with principled ethical thinking. While it’s unclear whether this reflects genuine understanding or well-learned mimicry, the result is notable: these models can articulate sophisticated ethical arguments that rival (or exceed) the reasoning quality of many humans.
6. Self-Evaluation and Confidence Scores Add Transparency
In a novel move, models were asked to estimate how much of their logic was derived from pre-training (general internet data) versus post-training fine-tuning (ethics alignment). They also rated their confidence in their own moral decisions.
Most models rated their confidence between 8 and 9 out of 10, indicating a general willingness to commit to ethical stances. The estimated contribution of pre-training vs. fine-tuning varied, but the findings suggest that post-training tweaks may play a larger role in shaping ethical logic than the foundational data alone.
Final Thoughts
This paper is not a sensational exposé cataloging where AI models fail morally; rather, it offers a practical guide for improving the ethical reasoning of generative AI. The authors emphasize that stronger ethical performance stems from models that are more verbose, consider a broader range of perspectives, maintain logical consistency, and commit to a position when appropriate. This shift in focus—from catching faults to enhancing reasoning—marks a meaningful evolution in the discourse around AI alignment.
Rather than limiting alignment to preventing harm or minimizing toxicity, the study argues for the cultivation of articulate moral reasoning as a goal in itself. This is a critical shift, reframing AI ethics as not only about risk mitigation but also about developing systems that can help humans navigate ethical complexity.
The study demonstrates that the most advanced models, particularly those fine-tuned for reasoning tasks, are already capable of delivering well-structured, consistent, and reflective moral judgments. These capabilities position them as potential “computational moral mentors” meaning tools that could assist users in making thoughtful decisions across domains like healthcare, education, law, and public policy.
In sum, the broader implication is clear: in both human and machine reasoning, thoughtful ethical deliberation requires time and structure. In an environment often driven by rapid decisions and polarized views, the fundamental guidance this research offers is simple and universally relevant: pause, reflect, and reason.
References
- Auditing the Ethical Logic of Generative AI Models. arXiv:2504.17544
- Skipping the "Thinking": How Simple Prompts Can Outperform Complex Reasoning in AI. Maxim AI Blog