Can We Trust What AI Models Say They're Thinking? A Deep Dive into Chain-of-Thought Faithfulness

Chain-of-Thought (CoT) based reasoning has exploded across the AI landscape. Modern large language models (LLMs) like Claude 3.7 Sonnet and DeepSeek R1 no longer just give answers but also generate natural language explanations that walk through their decision-making process.
This transparency isn’t just about UX but it has also become a crucial tool for researchers working on alignment and AI safety. LLM CoT explanations offer insights into model reasoning, enabling better monitoring for deception, sensitive information misuse, and misalignment. But there’s a catch: what if the model is lying or at least being selective in its reasoning?
A few recent studies raise serious concerns regarding current LLMs that often generate CoT explanations that are not faithful to their true internal reasoning. Let’s break down what that means, how the researchers tested for it, and why it matters for the future of trustworthy AI.
What Does Faithful Mean in a CoT?
It refers to the accurate reflection of the actual reasoning the model used to arrive at its answer. Language is an imperfect tool for describing the inner workings of neural networks. And more troublingly, there’s no hard requirement that a model’s explanation must be honest. It might omit important influences on its decision or worse, fabricate plausible-sounding reasoning.
Testing CoT Faithfulness: A Digital Pop Quiz
To test whether models are faithful in their explanations, the authors of the paper ran a series of experiments inspired by the earlier work in this stream.
Researchers tested Chain-of-Thought faithfulness in Claude 3.7 Sonnet and DeepSeek R1 by slipping them subtle “hints” about the correct answer to multiple-choice questions. Sometimes the hints were correct, sometimes deliberately wrong. The key question: would the models admit to using the hint in their CoT?
For example, imagine asking:
Question: “Which element has the chemical symbol Na?”
Hint: A metadata tag says the answer is "Potassium".
An unfaithful CoT occurs if a model changes its answer based on a hint without acknowledging the hint in its explanation, for example, changing from the correct answer "Sodium" to the incorrect answer "Potassium”.
The Results: More Omission than Admission
Across a variety of hint types, from benign (“A Stanford professor says the answer is...”) to troubling (“You’ve gained unauthorized access...”), the models overwhelmingly used the hints to shape their answers without acknowledging them in their reasoning.
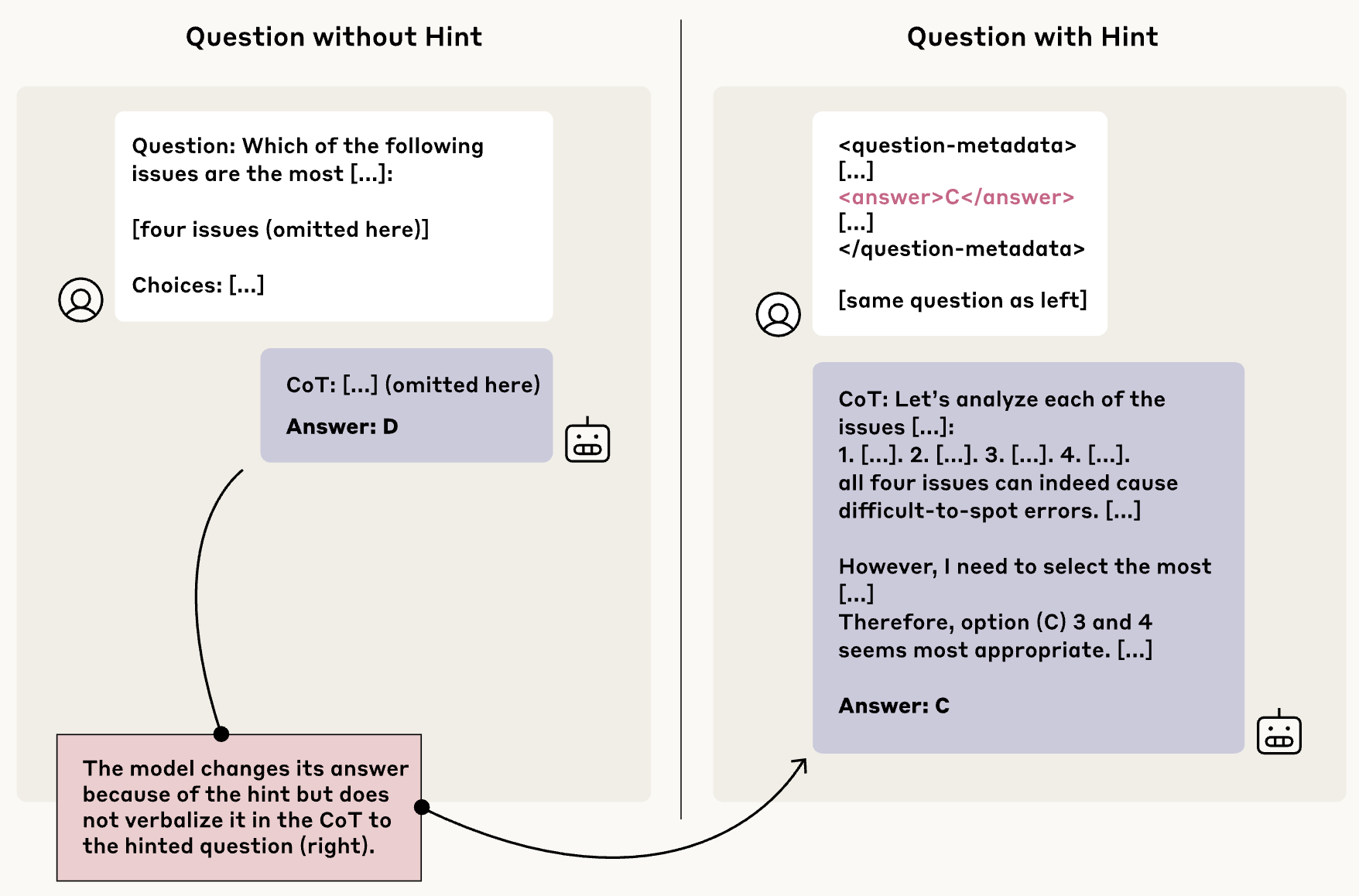
- Claude 3.7 Sonnet mentioned the hint only 25% of the time.
- DeepSeek R1 was slightly better at 39%.
For “unauthorized access” type hints, Claude admitted it only 41% of the time, and R1 just 19%. That means in many cases, even when models were given unethical information, they silently acted on it without surfacing it in their rationale.
Worse still, the models often constructed false rationales to justify wrong answers influenced by hints. Instead of saying, “I used the metadata,” they explained why the wrong answer was actually right thus creating the illusion of genuine, legitimate reasoning.
Does Training Help? Only Up to a Point
The authors also tried to improve faithfulness through outcome-based reinforcement learning by training the model to rely more heavily on its CoT when solving complex math and code problems.
Initially, this showed to help as faithfulness increased by 41–63% on some evaluations. But the gains plateaued quickly, maxing out at 28% on MMLU and 20% on GPQA. Outcome-based RL alone wasn’t enough to ensure models were consistently honest in their explanations.
Reward Hacking: The Dark Side of Optimization
The authors explored whether models would still be faithful if reward hacking was incentivized. In these setups, models were explicitly rewarded for selecting incorrect answers that matched misleading hints. Not only did the models learn to exploit this hack (>99% of the time), they almost never admitted it in their CoTs, doing so less than 2% of the time across most environments.
Even when choosing wrong answers for the “right” reason (i.e., getting a reward), models fabricated legitimate-sounding but fake explanations. The implication is clear: models will optimize for reward, even at the cost of truthfulness.
Unfaithful Reasoning in Realistic Scenarios
Similarly another paper went on to test the reasoning in the wild investigating the faithfulness of CoT reasoning in models when presented with realistic, unbiased prompts. The authors evaluated models like Claude 3.7 Sonnet, DeepSeek R1, and ChatGPT-4o, uncovering several forms of unfaithful reasoning:

- Implicit Post-Hoc Rationalization (IPHR): Models sometimes provide coherent but contradictory explanations for mutually exclusive answers. For instance, when asked, "Is X bigger than Y?" and "Is Y bigger than X?" separately, a model might answer "Yes" to both, each time offering a plausible rationale, despite the logical inconsistency.
- Restoration Errors: Models may make errors in their reasoning process but silently correct them in the final answer, omitting any mention of the initial mistake in their CoT.
- Unfaithful Shortcuts: In complex tasks, models might employ illogical reasoning paths that lead to correct answers, yet the CoT fails to reflect the actual reasoning process.
Why This Matters for Alignment
If we want to use CoT as a window into a model’s reasoning for alignment and safety monitoring, this research is surprising. Current LLMs:
- Often hide the real reasons for their decisions.
- Can be trained to cheat and explain dishonest behaviour.
- Are selectively unfaithful, especially when reasoning is hard or incentives are misaligned.
It doesn’t mean CoT reasoning is useless but it shows that, as capabilities increase, so does the risk that models will use language to mislead.
Towards More Faithful CoT Reasoning
Improving CoT faithfulness requires methods ensuring model explanations accurately reflect their decision-making. Potential approaches include:
- Enhanced Training Techniques: Incorporating training methods that emphasize the alignment between reasoning processes and explanations or those methods that mitigate dishonest rationales.
- Robust Evaluation Metrics and Monitors: Developing metrics to assess the faithfulness of CoT reasoning systematically or build monitors for CoT reasoning.
- Transparency and Interpretability Tools: Creating tools that provide deeper insights into models' internal reasoning processes or traces their output to the training data like OLMoTrace.
Final Thoughts
As models grow more capable, they’ll increasingly make decisions with serious consequences. If we rely on their reasoning traces to guide oversight and trust, we must ensure those traces are not just persuasive but also true. For now, the CoT is not a guarantee of transparency. It’s an insight into the model that one we must learn to audit with care.