Can LLMs Actually Judge Web Development Quality? Spoiler: Not Really

I recently came across a fascinating paper at ICLR’26 that tackles a question many of us AI developers have been wrestling with: can we trust LLMs to evaluate complex, interactive task? The authors focus on the domain of web development, and the short answer: we've got a long way to go.
The Problem: LLM-as-a-Judge Meets Reality
LLM-as-a-judge works reasonably well for static, well-defined tasks: text generation quality, factual QA, instruction following (MT-Bench achieves 63% inter-annotator agreement without structured protocols). But these all share a critical limitation: they evaluate final outputs without considering interaction dynamics or execution behavior.
Web development evaluation requires assessing multiple interconnected dimensions:
- Functional correctness: Does it implement the required features? Handle edge cases?
- UI quality: Visual consistency, layout structure, responsive design across viewports
- Dynamic behavior: Do interactions trigger correct state changes? Do forms submit properly?
- Code quality: Readability, modularity, scalability
This is way more complex than comparing two text outputs. You need to actually interact with the thing, check if buttons work, see if forms submit correctly, verify that the layout doesn't break on mobile.The evaluation space is open-ended (many correct solutions), ambiguous (subjective quality judgments), and requires verifying dynamic behavior through actual user interactions.
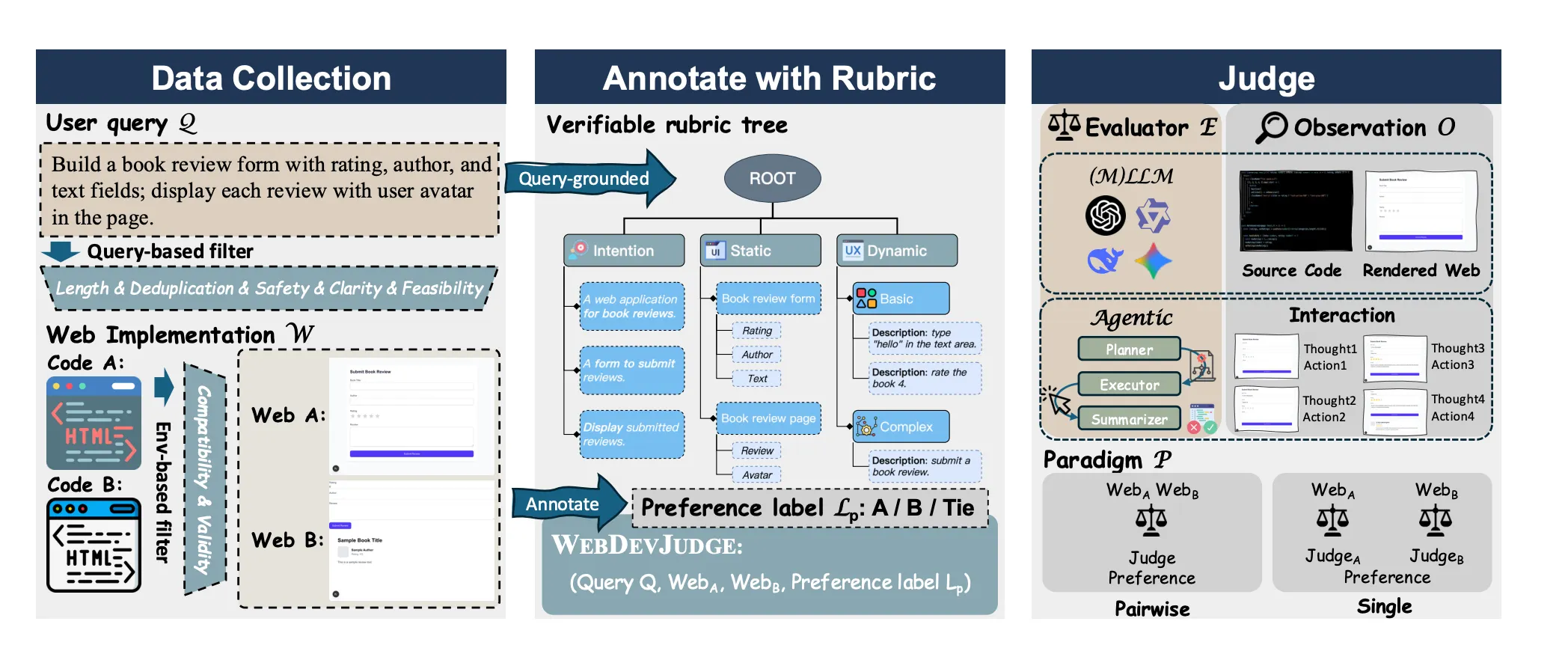
Enter WebDevJudge: A Proper Benchmark
The team built a benchmark with 654 high-quality instances of web development tasks. What makes it solid:
- Real user queries from the WebDev Arena dataset: stuff like "build a book review form" or "create a chess game"
- Rigorous filtering to remove garbage, unsafe content, and broken implementations
- Human expert annotations using structured rubric trees (89.7% inter-annotator agreement!)
- Multiple evaluation modalities: code, screenshots, and live interactive environments
The rubric trees are particularly clever. They break down each task into three dimensions:
- Intention: Does it meet the core requirements?
- Static Quality: UI layout, code quality, aesthetics
- Dynamic Behavior: Do the interactive features actually work?
Each dimension gets broken down into verifiable leaf nodes: binary pass/fail checks that humans (and models) can evaluate.
The Experiment: How Do LLMs Stack Up?
They tested 18+ models, including GPT-4.1, Claude Sonnet 4, Gemini, DeepSeek, and Qwen variants. They also tried different paradigms:
Pairwise vs. Single-Answer Grading
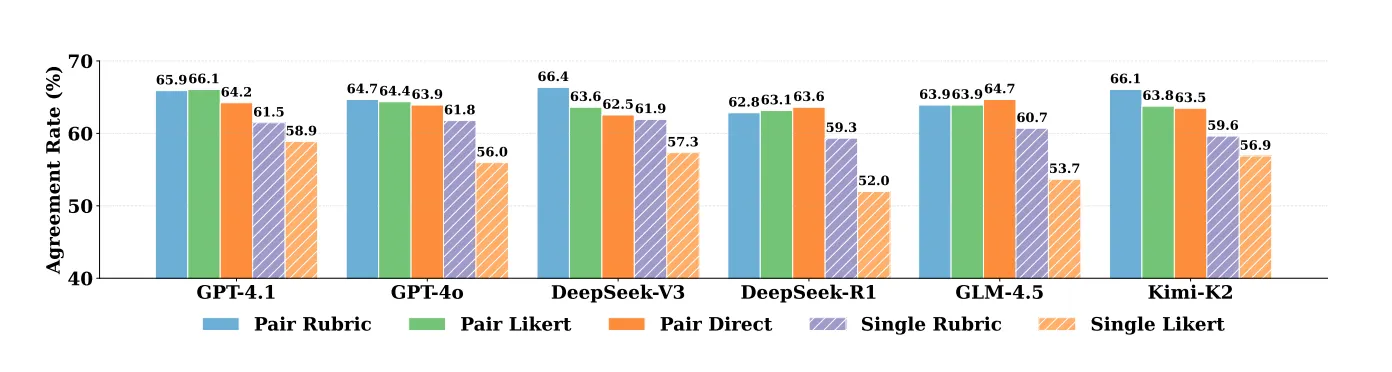
Pairwise comparison (directly comparing two implementations) consistently beat single-answer grading (scoring each implementation independently) by over 8%. Which makes sense, it's easier to say "A is better than B" than to assign absolute quality scores.
What About Agentic Workflows?
Here's where it gets interesting. They built an agentic system with a planner → executor → summarizer pipeline. The executor (UI-TARS-1.5, one of the SOTA GUI agents) actually navigates the web pages and tests functionality. Sounds perfect for this task, right?
Nope. The agentic approach underperformed vanilla models. Why? Compounding errors:
- The planner generates evaluation plans that are often too generic or too specific
- The executor agent fails to reliably navigate and verify states
- Errors accumulate across the pipeline
The Results: A Reality Check
Best performance: ~66% agreement with human experts (Claude Sonnet 4 in pairwise mode). Humans score 84.82%.
That 15-20 point gap is significant. Even more concerning:
- There's a clear performance ceiling. Bigger models don't help much beyond a certain point
- Position bias persists despite explicit instructions to be objective
- Different evaluation protocols (rubrics vs. Likert scales vs. direct judgment) don't move the needle much in pairwise settings
What's Actually Breaking?
The paper digs into failure modes, and two stand out:
1. Functional Equivalence Failures
Models struggle to recognize when different implementations achieve the same goal. Example: a rubric asks for a "Demonstration" rating row, but the implementation has a "Presentation" rating row. Humans correctly recognize these as equivalent; LLMs don't.
This is a fundamental reasoning gap, models can be too literal and miss the intent.
2. Feasibility Verification Problems
They built WebDevJudge-Unit (502 test cases) to specifically test verification capabilities:
- LLM evaluators (code-only): High recall (90%+), low precision (70-72%). They find relevant code but can't verify it actually works.
- Agent evaluators (interactive): High precision (82%), low recall (70%). They're accurate when they complete tests, but often fail due to navigation issues.
It's a classic tradeoff: static analysis lacks execution grounding, while interactive agents are limited by their own operational reliability.
What This Means for Production Systems
If you're deploying LLM evaluators:
1. Don't Trust Blind - Calibrate Against Real Metrics
66% agreement = 1/3 of evaluations are wrong. For production pipelines (code review, QA automation, reward modeling), this error rate is unacceptable without human oversight. Consider:
- Confidence thresholding: Only auto-approve high-confidence judgments, route uncertain cases to humans
- Ensemble approaches: Multiple model judgments + majority voting can improve reliability (though inter-model agreement shows they often fail similarly)
- Ground truth calibration: Regularly benchmark against human judgments to track drift
2. Pairwise > Absolute When You Have a Choice
8-10 point improvement is substantial. If your eval pipeline can structure tasks as A/B comparisons rather than absolute scoring:
- More robust to calibration drift
- Better inter-model consistency (75-85% vs. 50-65%)
- Aligns with how models naturally perform comparative reasoning
Caveat: Positional bias remains (use swapping/debiasing if stakes are high), though it only impacts agreement by ~1-2%.
3. Agentic Workflows: Premature for Reliable Evaluation
Error accumulation (planner brittleness + executor failures) negates the theoretical advantage of interactive verification. Multi-stage pipelines compound failure modes rather than improving robustness.
When agents might work: Narrow, well-specified verification tasks where the test plan is deterministic and execution is reliable. Avoid for open-ended evaluation requiring robust navigation and state interpretation.
4. The Functional Equivalence Problem is Fundamental
35.9% of false negatives stem from semantic mismatch where the model rejects valid implementations due to surface-level differences. This isn't fixable with prompting and is a core reasoning limitation.
Mitigation strategies:
- Explicit few-shot examples of acceptable variations in evaluation prompts
- Looser rubrics that specify functional requirements, not implementation details
- Human review of rejections (models are more likely wrong on "close but not exact" cases)
5. Verification Capability Mismatch
Static evaluators have the opposite error profile from interactive agents. Neither alone is sufficient:
- For recall-critical applications (don't miss valid implementations): Use LLM code analysis
- For precision-critical applications (minimize false positives): Use interactive agents
- For both: Combine approaches, though no existing system does this well
The Path Forward
The paper suggests a few directions:
- Better calibration: Models need to map abstract quality dimensions onto discrete scores more consistently
- Improved verification: We need evaluators that combine the coverage of code analysis with the grounding of interactive testing
- Reasoning about intent: Models must get better at understanding functional equivalence vs. literal matching
This is important work. As we push LLMs into more autonomous roles, whether that's code generation, testing, or evaluation, we need rigorous benchmarks like this to keep us honest about their limitations.
End Notes
Having worked on applied AI evaluation systems, this confirms priors but with rigorous numbers. The 66% vs. 84% gap isn't "we're almost there", it's "fundamental capabilities are missing."
The functional equivalence failure is particularly damning. Even with explicit instructions ("consider equivalent features acceptable"), models fail at semantic reasoning that humans handle trivially. This suggests current architectures lack proper compositionality: they can't decompose "rating category requirement" into its functional essence independent of surface labels.
The guidance insensitivity finding is surprising but instructive. If rubrics/Likert scales don't improve pairwise judgment, it means preference prediction is internalized in the model weights (likely from RLHF/DPO training). We're not teaching models how to evaluate but are hoping they learned it during training. That's a fragile foundation.
For anyone building eval systems: Design for the 66%, not the aspirational 100%. Implement hard error bounds, human escalation for uncertain judgments, and regular ground-truth recalibration. And maybe don't bet your entire QA pipeline on agentic workflows until executor reliability catches up to theory.
The benchmark itself is valuable beyond the results: 654 instances with 89.7% agreement rubrics, supporting both static and interactive evaluation. It's a real testbed for the "can LLMs replace humans for complex evaluation" question. Answer: not yet, and the gaps are structural, not marginal.
Paper: WebDevJudge: Evaluating (M)LLMs as Critiques for Web Development Quality


