Building a Resume Checker with LlamaIndex and Maxim Observability

In this comprehensive tutorial, we'll build an intelligent Resume Checker agent using LlamaIndex that analyzes resumes and provides detailed feedback. We'll also integrate Maxim observability to monitor the agent's performance and gain insights into its decision-making process.
What We'll Build
Our Resume Checker will:
- Analyze resume content for grammar, structure, and impact
- Provide specific improvement suggestions
- Score different aspects of the resume
- Generate a structured JSON report with actionable feedback
- Be fully observable with Maxim tracing
Prerequisites
Before we begin, make sure you have the following installed:
pip install llama-index llama-index-llms-openai llama-index-embeddings-openai maxim-py python-dotenv
Step 1: Set Up Environment Variables
First, create a .env file in your project directory:
# .env
MAXIM_API_KEY=your_maxim_api_key_here
MAXIM_LOG_REPO_ID=your_log_repo_id_here
OPENAI_API_KEY=your_openai_api_key_here
Step 2: Initialize Maxim Logger
Let's start by setting up Maxim for observability:
import os
from dotenv import load_dotenv
from maxim import Config, Maxim
from maxim.logger import LoggerConfig
# Load environment variables
load_dotenv()
# Initialize Maxim logger
maxim = Maxim(Config(api_key=os.getenv("MAXIM_API_KEY")))
logger = maxim.logger(LoggerConfig(id=os.getenv("MAXIM_LOG_REPO_ID")))
print("✅ Maxim logger initialized successfully!")
Step 3: Enable LlamaIndex Instrumentation
Now let's instrument LlamaIndex to automatically trace all agent interactions:
from maxim.logger.llamaindex import instrument_llamaindex
# Instrument LlamaIndex with Maxim observability
instrument_llamaindex(logger, debug=True)
print("✅ LlamaIndex instrumentation enabled!")
Step 4: Create Resume Analysis Tools
Let's build the core tools that our Resume Checker agent will use. These are the Resume Analysis Tools that provides comprehensive feedback on resume quality across four key areas:
- Grammar & Spelling - Detects passive voice, weak verbs, repetitive words, and overly long sentences
- Conciseness - Identifies wordy phrases and redundant language, suggests more concise alternatives
- Impact & Achievements - Analyzes use of metrics, action verbs, and result-oriented language to measure how well the resume demonstrates accomplishments
- Structure & Formatting - Checks for essential resume sections (contact info, summary, experience, education, skills) and proper formatting like bullet points
import json
import re
from typing import Dict, List, Any
from llama_index.core.tools import FunctionTool
def analyze_grammar_and_spelling(text: str) -> Dict[str, Any]:
"""
Analyze grammar and spelling in the provided text.
Returns detailed feedback on grammar issues and suggestions.
"""
# Common grammar patterns to check
grammar_patterns = {
"passive_voice": r"\\b(am|is|are|was|were|be|been|being)\\s+\\w+ed\\b",
"weak_verbs": r"\\b(did|made|got|had|went|came)\\b",
"repetitive_words": r"\\b(\\w+)\\s+\\1\\b",
"long_sentences": r"[^.!?]{100,}",
}
issues = []
suggestions = []
# Check for passive voice
passive_matches = re.findall(grammar_patterns["passive_voice"], text, re.IGNORECASE)
if passive_matches:
issues.append(f"Found {len(passive_matches)} instances of passive voice")
suggestions.append("Consider using active voice for stronger impact")
# Check for weak verbs
weak_verb_matches = re.findall(grammar_patterns["weak_verbs"], text, re.IGNORECASE)
if weak_verb_matches:
issues.append(f"Found {len(weak_verb_matches)} weak verbs")
suggestions.append("Replace weak verbs with action verbs (e.g., 'achieved' instead of 'did')")
# Check for repetitive words
repetitive_matches = re.findall(grammar_patterns["repetitive_words"], text, re.IGNORECASE)
if repetitive_matches:
issues.append(f"Found {len(repetitive_matches)} repetitive word patterns")
suggestions.append("Use synonyms to avoid repetition")
# Check for long sentences
long_sentences = re.findall(grammar_patterns["long_sentences"], text)
if long_sentences:
issues.append(f"Found {len(long_sentences)} sentences that may be too long")
suggestions.append("Break long sentences into shorter, more impactful ones")
return {
"issues": issues,
"suggestions": suggestions,
"score": max(0, 10 - len(issues) * 2) # Score out of 10
}
def analyze_conciseness(text: str) -> Dict[str, Any]:
"""
Analyze the conciseness and clarity of the text.
Returns feedback on wordiness and suggestions for improvement.
"""
# Wordy phrases to identify
wordy_phrases = {
"due to the fact that": "because",
"in order to": "to",
"at this point in time": "now",
"in the event that": "if",
"with regard to": "regarding",
"in the near future": "soon",
"as a matter of fact": "in fact",
"it is important to note that": "",
"it should be noted that": "",
}
issues = []
suggestions = []
word_count = len(text.split())
# Check for wordy phrases
found_wordy_phrases = []
for phrase, replacement in wordy_phrases.items():
if phrase.lower() in text.lower():
found_wordy_phrases.append((phrase, replacement))
if found_wordy_phrases:
issues.append(f"Found {len(found_wordy_phrases)} wordy phrases")
suggestions.append("Replace wordy phrases with concise alternatives")
for phrase, replacement in found_wordy_phrases[:3]: # Show first 3
suggestions.append(f"Replace '{phrase}' with '{replacement}'")
# Check for redundant words
redundant_patterns = [
r"\\b(very|really|quite|extremely)\\s+\\w+\\b",
r"\\b(basic|fundamental)\\s+essentials\\b",
r"\\b(advance)\\s+planning\\b",
r"\\b(close)\\s+proximity\\b",
]
redundant_count = 0
for pattern in redundant_patterns:
matches = re.findall(pattern, text, re.IGNORECASE)
redundant_count += len(matches)
if redundant_count > 0:
issues.append(f"Found {redundant_count} redundant words or phrases")
suggestions.append("Remove redundant words to improve clarity")
# Calculate conciseness score
base_score = 10
if word_count > 500:
base_score -= 2
if found_wordy_phrases:
base_score -= len(found_wordy_phrases)
if redundant_count > 0:
base_score -= min(3, redundant_count)
return {
"issues": issues,
"suggestions": suggestions,
"word_count": word_count,
"score": max(0, base_score)
}
def analyze_impact_and_achievements(text: str) -> Dict[str, Any]:
"""
Analyze the impact and achievement-oriented language in the text.
Returns feedback on how well the text demonstrates achievements.
"""
# Achievement indicators
achievement_patterns = {
"metrics": r"\\b(\\d+%|\\d+x|\\$\\d+|\\d+% increase|\\d+% decrease)\\b",
"action_verbs": r"\\b(achieved|increased|decreased|improved|developed|created|managed|led|implemented|delivered)\\b",
"results": r"\\b(resulted in|led to|achieved|accomplished|completed)\\b",
}
strengths = []
suggestions = []
# Check for metrics
metrics = re.findall(achievement_patterns["metrics"], text, re.IGNORECASE)
if metrics:
strengths.append(f"Found {len(metrics)} quantifiable metrics")
else:
suggestions.append("Add specific metrics and numbers to quantify achievements")
# Check for action verbs
action_verbs = re.findall(achievement_patterns["action_verbs"], text, re.IGNORECASE)
if action_verbs:
strengths.append(f"Used {len(action_verbs)} strong action verbs")
else:
suggestions.append("Use more action verbs to demonstrate impact")
# Check for result-oriented language
results = re.findall(achievement_patterns["results"], text, re.IGNORECASE)
if results:
strengths.append(f"Found {len(results)} result-oriented statements")
else:
suggestions.append("Focus on results and outcomes rather than just responsibilities")
# Calculate impact score
score = 5 # Base score
if metrics:
score += 3
if len(action_verbs) >= 5:
score += 2
if results:
score += 2
return {
"strengths": strengths,
"suggestions": suggestions,
"metrics_count": len(metrics),
"action_verbs_count": len(action_verbs),
"score": min(10, score)
}
def analyze_structure_and_formatting(text: str) -> Dict[str, Any]:
"""
Analyze the structure and formatting of the resume.
Returns feedback on organization and readability.
"""
sections = {
"contact_info": r"(email|phone|address|linkedin)",
"summary": r"(summary|objective|profile)",
"experience": r"(experience|work history|employment)",
"education": r"(education|academic|degree)",
"skills": r"(skills|competencies|technologies)",
}
found_sections = []
missing_sections = []
for section_name, pattern in sections.items():
if re.search(pattern, text, re.IGNORECASE):
found_sections.append(section_name)
else:
missing_sections.append(section_name)
suggestions = []
if "contact_info" in missing_sections:
suggestions.append("Add contact information section")
if "summary" in missing_sections:
suggestions.append("Consider adding a professional summary")
if "experience" in missing_sections:
suggestions.append("Include work experience section")
if "education" in missing_sections:
suggestions.append("Add education section")
if "skills" in missing_sections:
suggestions.append("Include skills section")
# Check for bullet points
bullet_points = re.findall(r"^[\\s]*[•\\-\\*]\\s+", text, re.MULTILINE)
if not bullet_points:
suggestions.append("Use bullet points to improve readability")
# Calculate structure score
score = len(found_sections) * 2 # 2 points per section
return {
"found_sections": found_sections,
"missing_sections": missing_sections,
"suggestions": suggestions,
"bullet_points_count": len(bullet_points),
"score": min(10, score)
}
# Create function tools
grammar_tool = FunctionTool.from_defaults(fn=analyze_grammar_and_spelling)
conciseness_tool = FunctionTool.from_defaults(fn=analyze_conciseness)
impact_tool = FunctionTool.from_defaults(fn=analyze_impact_and_achievements)
structure_tool = FunctionTool.from_defaults(fn=analyze_structure_and_formatting)
print("✅ Resume analysis tools created successfully!")
Step 5: Create the Resume Checker Agent
Now let's create our main Resume Checker agent:
from llama_index.core.agent import FunctionAgent
from llama_index.llms.openai import OpenAI
# Initialize LLM
llm = OpenAI(model="gpt-4o-mini", temperature=0)
# Create the Resume Checker agent
resume_checker_agent = FunctionAgent(
tools=[grammar_tool, conciseness_tool, impact_tool, structure_tool],
llm=llm,
verbose=True,
system_prompt="""You are an expert resume reviewer and career coach. Your job is to analyze resumes comprehensively and provide detailed, actionable feedback.
When analyzing a resume:
1. Use the grammar tool to check for grammar and spelling issues
2. Use the conciseness tool to evaluate clarity and wordiness
3. Use the impact tool to assess achievement-oriented language
4. Use the structure tool to evaluate organization and formatting
After running all analyses, compile the results into a comprehensive JSON report with the following structure:
{
"overall_score": <score out of 40>,
"grammar_and_spelling": {
"score": <score out of 10>,
"issues": [<list of issues>],
"suggestions": [<list of suggestions>]
},
"conciseness": {
"score": <score out of 10>,
"issues": [<list of issues>],
"suggestions": [<list of suggestions>],
"word_count": <total words>
},
"impact_and_achievements": {
"score": <score out of 10>,
"strengths": [<list of strengths>],
"suggestions": [<list of suggestions>],
"metrics_count": <number of metrics found>,
"action_verbs_count": <number of action verbs>
},
"structure_and_formatting": {
"score": <score out of 10>,
"found_sections": [<list of found sections>],
"missing_sections": [<list of missing sections>],
"suggestions": [<list of suggestions>]
},
"priority_improvements": [<top 3 most important improvements>],
"summary": "<brief overall assessment>"
}
Always provide constructive, specific feedback that helps the candidate improve their resume."""
)
print("✅ Resume Checker agent created successfully!")
Step 6: Test with Sample Resume
Let's test our Resume Checker with a sample resume:
# Sample resume for testing
sample_resume = """
JOHN DOE
Software Engineer
[email protected] | (555) 123-4567 | linkedin.com/in/johndoe
SUMMARY
Experienced software engineer with 5 years of experience in developing web applications and mobile apps. Skilled in Python, JavaScript, and React.
EXPERIENCE
Software Engineer | Tech Company Inc. | 2020-2023
• Developed and maintained web applications using Python and Django
• Collaborated with cross-functional teams to deliver high-quality software
• Implemented new features that improved user experience
Junior Developer | Startup XYZ | 2018-2020
• Assisted in the development of mobile applications
• Did bug fixes and code reviews
• Made contributions to the codebase
EDUCATION
Bachelor of Science in Computer Science
University of Technology | 2018
SKILLS
Programming Languages: Python, JavaScript, Java
Frameworks: Django, React, Node.js
Tools: Git, Docker, AWS
"""
# Run the resume analysis
async def analyze_resume(resume_text: str):
print("🔍 Analyzing resume...")
print("=" * 50)
response = await resume_checker_agent.run(
f"Please analyze this resume comprehensively:\\n\\n{resume_text}"
)
print("📊 Analysis Complete!")
print("=" * 50)
print(response)
return response
# Run the analysis
import asyncio
result = await analyze_resume(sample_resume)
Step 7: Create a Complete Resume Checker Application
Let's create a complete application that can handle multiple resumes and provide detailed reports:
import json
from typing import Dict, Any
from datetime import datetime
class ResumeCheckerApp:
def __init__(self):
self.agent = resume_checker_agent
self.analysis_history = []
async def check_resume(self, resume_text: str, candidate_name: str = "Unknown") -> Dict[str, Any]:
"""
Analyze a resume and return a comprehensive report.
"""
print(f"🔍 Analyzing resume for: {candidate_name}")
print("=" * 60)
# Run the analysis
response = await self.agent.run(
f"Please analyze this resume comprehensively and provide a detailed JSON report:\\n\\n{resume_text}"
)
# Try to extract JSON from the response
try:
# Look for JSON in the response
json_start = response.find('{')
json_end = response.rfind('}') + 1
if json_start != -1 and json_end != -1:
json_str = response[json_start:json_end]
analysis_result = json.loads(json_str)
else:
# If no JSON found, create a basic structure
analysis_result = {
"overall_score": 0,
"summary": "Analysis completed but JSON parsing failed",
"raw_response": response
}
except json.JSONDecodeError:
analysis_result = {
"overall_score": 0,
"summary": "JSON parsing error occurred",
"raw_response": response
}
# Add metadata
analysis_result["candidate_name"] = candidate_name
analysis_result["analysis_date"] = datetime.now().isoformat()
analysis_result["resume_length"] = len(resume_text)
# Store in history
self.analysis_history.append(analysis_result)
return analysis_result
def print_report(self, analysis_result: Dict[str, Any]):
"""
Print a formatted analysis report.
"""
print("\\n" + "=" * 60)
print(f"📋 RESUME ANALYSIS REPORT")
print(f"Candidate: {analysis_result.get('candidate_name', 'Unknown')}")
print(f"Date: {analysis_result.get('analysis_date', 'Unknown')}")
print("=" * 60)
# Overall score
overall_score = analysis_result.get('overall_score', 0)
print(f"\\n🎯 OVERALL SCORE: {overall_score}/40")
# Grammar and Spelling
grammar = analysis_result.get('grammar_and_spelling', {})
print(f"\\n📝 GRAMMAR & SPELLING: {grammar.get('score', 0)}/10")
if grammar.get('issues'):
print(" Issues:")
for issue in grammar['issues']:
print(f" • {issue}")
if grammar.get('suggestions'):
print(" Suggestions:")
for suggestion in grammar['suggestions']:
print(f" • {suggestion}")
# Conciseness
conciseness = analysis_result.get('conciseness', {})
print(f"\\n✂️ CONCISENESS: {conciseness.get('score', 0)}/10")
print(f" Word count: {conciseness.get('word_count', 0)}")
if conciseness.get('issues'):
print(" Issues:")
for issue in conciseness['issues']:
print(f" • {issue}")
if conciseness.get('suggestions'):
print(" Suggestions:")
for suggestion in conciseness['suggestions']:
print(f" • {suggestion}")
# Impact and Achievements
impact = analysis_result.get('impact_and_achievements', {})
print(f"\\n🚀 IMPACT & ACHIEVEMENTS: {impact.get('score', 0)}/10")
print(f" Metrics found: {impact.get('metrics_count', 0)}")
print(f" Action verbs: {impact.get('action_verbs_count', 0)}")
if impact.get('strengths'):
print(" Strengths:")
for strength in impact['strengths']:
print(f" • {strength}")
if impact.get('suggestions'):
print(" Suggestions:")
for suggestion in impact['suggestions']:
print(f" • {suggestion}")
# Structure and Formatting
structure = analysis_result.get('structure_and_formatting', {})
print(f"\\n📋 STRUCTURE & FORMATTING: {structure.get('score', 0)}/10")
print(f" Sections found: {', '.join(structure.get('found_sections', []))}")
if structure.get('missing_sections'):
print(f" Missing sections: {', '.join(structure['missing_sections'])}")
if structure.get('suggestions'):
print(" Suggestions:")
for suggestion in structure['suggestions']:
print(f" • {suggestion}")
# Priority improvements
if analysis_result.get('priority_improvements'):
print(f"\\n🎯 PRIORITY IMPROVEMENTS:")
for i, improvement in enumerate(analysis_result['priority_improvements'], 1):
print(f" {i}. {improvement}")
# Summary
if analysis_result.get('summary'):
print(f"\\n📝 SUMMARY:")
print(f" {analysis_result['summary']}")
print("\\n" + "=" * 60)
def save_report(self, analysis_result: Dict[str, Any], filename: str = None):
"""
Save the analysis report to a JSON file.
"""
if filename is None:
candidate_name = analysis_result.get('candidate_name', 'unknown')
date_str = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"resume_analysis_{candidate_name}_{date_str}.json"
with open(filename, 'w') as f:
json.dump(analysis_result, f, indent=2)
print(f"💾 Report saved to: {filename}")
# Create the application instance
resume_checker_app = ResumeCheckerApp()
print("✅ Resume Checker application created successfully!")
Step 8: Test with Multiple Resumes
Let's test our application with different types of resumes:
# Resume 1: Entry-level candidate
entry_level_resume = """
SARAH JOHNSON
Recent Graduate | [email protected] | (555) 987-6543
EDUCATION
Bachelor of Science in Marketing
State University | 2023
EXPERIENCE
Marketing Intern | Local Business | Summer 2022
• Helped with social media posts and content creation
• Assisted in organizing marketing events
• Did some data entry and basic analysis
Volunteer | Community Organization | 2021-2022
• Volunteered at local events
• Helped with fundraising activities
SKILLS
Social Media Marketing, Microsoft Office, Basic Analytics
"""
# Resume 2: Experienced professional
experienced_resume = """
MICHAEL CHEN
Senior Product Manager | [email protected] | linkedin.com/in/michaelchen
SUMMARY
Results-driven Product Manager with 8+ years of experience leading cross-functional teams and delivering innovative products that drive business growth.
EXPERIENCE
Senior Product Manager | TechCorp | 2020-2023
• Led product strategy for flagship SaaS platform, resulting in 40% revenue growth
• Managed team of 12 engineers and designers, delivering 15+ major features
• Implemented data-driven decision making, improving user retention by 25%
• Collaborated with sales and marketing teams to achieve 150% of quarterly targets
Product Manager | StartupXYZ | 2018-2020
• Launched mobile app from concept to 100K+ downloads in first year
• Reduced customer churn by 30% through improved onboarding flow
• Established product metrics framework used across company
EDUCATION
MBA, Business Administration | Top Business School | 2018
BS, Computer Science | Engineering University | 2016
SKILLS
Product Strategy, Agile/Scrum, Data Analysis, User Research, A/B Testing, SQL, Python
"""
# Test both resumes
async def test_multiple_resumes():
print("🧪 Testing Resume Checker with multiple resumes...")
# Test entry-level resume
print("\\n" + "=" * 80)
print("TESTING ENTRY-LEVEL RESUME")
print("=" * 80)
entry_result = await resume_checker_app.check_resume(
entry_level_resume,
"Sarah Johnson (Entry-Level)"
)
resume_checker_app.print_report(entry_result)
resume_checker_app.save_report(entry_result, "entry_level_analysis.json")
# Test experienced resume
print("\\n" + "=" * 80)
print("TESTING EXPERIENCED RESUME")
print("=" * 80)
experienced_result = await resume_checker_app.check_resume(
experienced_resume,
"Michael Chen (Experienced)"
)
resume_checker_app.print_report(experienced_result)
resume_checker_app.save_report(experienced_result, "experienced_analysis.json")
# Compare results
print("\\n" + "=" * 80)
print("COMPARISON SUMMARY")
print("=" * 80)
print(f"Entry-Level Score: {entry_result.get('overall_score', 0)}/40")
print(f"Experienced Score: {experienced_result.get('overall_score', 0)}/40")
return entry_result, experienced_result
# Run the tests
entry_result, experienced_result = await test_multiple_resumes()
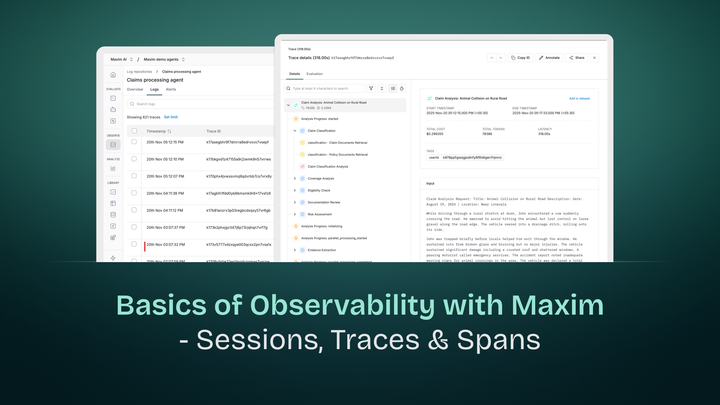
Step 9: View Traces in Maxim Dashboard
All our Resume Checker interactions are automatically traced in Maxim. You can view:
- Agent Execution Traces: See how the agent processes each resume
- Tool Call Performance: Monitor the performance of each analysis tool
- Decision Making Process: Understand how the agent arrives at its recommendations
- Error Handling: Track any issues or failures during analysis
- Node Level Evals: You can enable node level evaluations on your trace components
- Performance Metrics: Monitor Agent Run Token Consumption, Cost & overall latency
Visit your Maxim dashboard to visualise the above components -
Step 11: Create a Web Interface (Optional)
For a complete solution, you might want to create a simple web interface:
from flask import Flask, request, jsonify, render_template_string
import asyncio
app = Flask(__name__)
# HTML template for the web interface
HTML_TEMPLATE = """
<!DOCTYPE html>
<html>
<head>
<title>Resume Checker</title>
<style>
body { font-family: Arial, sans-serif; max-width: 800px; margin: 0 auto; padding: 20px; }
.form-group { margin-bottom: 15px; }
label { display: block; margin-bottom: 5px; font-weight: bold; }
textarea { width: 100%; height: 300px; padding: 10px; }
select { padding: 5px; }
button { background: #007bff; color: white; padding: 10px 20px; border: none; cursor: pointer; }
.result { margin-top: 20px; padding: 15px; background: #f8f9fa; border-radius: 5px; }
</style>
</head>
<body>
<h1>Resume Checker with Maxim Observability</h1>
<form method="POST">
<div class="form-group">
<label for="candidate_name">Candidate Name:</label>
<input type="text" id="candidate_name" name="candidate_name" required>
</div>
<div class="form-group">
<label for="industry">Industry Focus:</label>
<select id="industry" name="industry">
<option value="general">General</option>
<option value="tech">Technology</option>
<option value="marketing">Marketing</option>
<option value="finance">Finance</option>
</select>
</div>
<div class="form-group">
<label for="resume_text">Resume Text:</label>
<textarea id="resume_text" name="resume_text" placeholder="Paste your resume here..." required></textarea>
</div>
<button type="submit">Analyze Resume</button>
</form>
{% if result %}
<div class="result">
<h2>Analysis Results</h2>
<pre>{{ result | tojson(indent=2) }}</pre>
</div>
{% endif %}
</body>
</html>
"""
@app.route('/', methods=['GET', 'POST'])
def index():
result = None
if request.method == 'POST':
candidate_name = request.form['candidate_name']
industry = request.form['industry']
resume_text = request.form['resume_text']
# Run analysis based on industry
if industry == "tech":
checker = tech_resume_checker
elif industry == "marketing":
checker = marketing_resume_checker
elif industry == "finance":
checker = finance_resume_checker
else:
checker = resume_checker_app
# Run the analysis
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
result = loop.run_until_complete(
checker.check_resume_with_industry_focus(resume_text, candidate_name)
)
finally:
loop.close()
return render_template_string(HTML_TEMPLATE, result=result)
if __name__ == '__main__':
print("🌐 Starting Resume Checker web interface...")
print("📱 Visit <http://localhost:5000> to use the web interface")
app.run(debug=True, port=5000)
Summary
In this comprehensive tutorial, we've built a powerful Resume Checker using LlamaIndex and Maxim observability. Here's what we accomplished:
What We Built:
- Comprehensive Analysis Tools: Grammar, conciseness, impact, and structure analysis
- Intelligent Agent: LlamaIndex agent that orchestrates the analysis
- Maxim Integration: Full observability and tracing of all interactions
- Structured Output: Detailed JSON reports with scores and suggestions
- Industry-Specific Analysis: Custom checkers for different industries
- Web Interface: Optional Flask-based web application
Key Features:
- Grammar & Spelling Analysis: Identifies passive voice, weak verbs, and repetitive patterns
- Conciseness Evaluation: Detects wordy phrases and redundant language
- Impact Assessment: Analyzes achievement-oriented language and metrics
- Structure Analysis: Evaluates resume organization and formatting
- Industry Alignment: Industry-specific keyword analysis and scoring
- Comprehensive Reporting: Detailed JSON output with actionable suggestions
Sample Output Structure:
{
"overall_score": 32,
"grammar_and_spelling": {
"score": 8,
"issues": ["Found 2 instances of passive voice"],
"suggestions": ["Consider using active voice for stronger impact"]
},
"conciseness": {
"score": 7,
"issues": ["Found 3 wordy phrases"],
"suggestions": ["Replace 'due to the fact that' with 'because'"]
},
"impact_and_achievements": {
"score": 9,
"strengths": ["Found 5 quantifiable metrics", "Used 8 strong action verbs"],
"suggestions": ["Add more specific metrics to quantify achievements"]
},
"structure_and_formatting": {
"score": 8,
"found_sections": ["contact_info", "summary", "experience", "education", "skills"],
"missing_sections": [],
"suggestions": ["Use bullet points to improve readability"]
},
"priority_improvements": [
"Replace passive voice with active voice",
"Add more specific metrics and numbers",
"Use bullet points for better formatting"
],
"summary": "Strong resume with good structure and achievements. Focus on active voice and specific metrics for maximum impact."
}
Maxim Observability Benefits:
- Real-time Monitoring: Track all resume analysis sessions
- Performance Insights: Monitor tool execution times and success rates
- Error Tracking: Identify and debug analysis failures
- Usage Analytics: Understand patterns in resume submissions
- Quality Assurance: Ensure consistent analysis quality
The Resume Checker is now ready for production use with full observability through Maxim. You can extend it further by adding more analysis tools, custom scoring algorithms, or integrating it with other systems.