Bifrost: A Drop-in LLM Proxy, 50x Faster Than LiteLLM

When you’re building with LLMs, day-to-day tasks like writing, brainstorming, and quick automation feel almost effortless. But as soon as you try to construct a robust, production-grade pipeline, the real challenges emerge. One of the first hurdles is interface fragmentation: every provider exposes a different API, with its own rate limits, input quirks, and error formats. Switching models can mean rewriting large parts of your stack just to keep things running.
And yes, that’s a real problem. But it’s also the obvious one.
Most LLM gateways do a good job at first: they unify APIs, hide output quirks, and let you swap providers without rewriting your code. It feels like future-proofing, until you scale. Once you're handling thousands of RPS, juggling live fallbacks, key rotation, latency SLAs, and token-level accounting, those clean abstractions start to buckle. What helped you move fast in dev becomes the bottleneck in prod.
That’s why we built Bifrost - not just another LLM proxy, but the fastest, most scalable LLM gateway out there, engineered specifically for high-throughput, production-grade AI systems.
- ⚡️ Blazing fast: Built in Go, Bifrost introduces <15µs* internal overhead per request at 5000 RPS.
- 📊 First-class observability: Native Prometheus metrics built-in - no wrappers, no sidecars, just drop it in and scrape.
- 🔌 Flexible transport: Supports HTTP and gRPC (planned) out of the box, so you don’t have to contort your infra to fit the tool. Bifrost bends to your system, not the other way around.
Checkout the official bifrost github repository -
To give you an idea, we ran some benchmark tests at 500 RPS to compare performance of Bifrost and LiteLLM. Here are the results:
Beyond this scale, LiteLLM starts failing; resulting in more than 4 minutes latency on an average.
| Metric | Bifrost | LiteLLM |
|---|---|---|
| Success Rate | 100% | 88.78% |
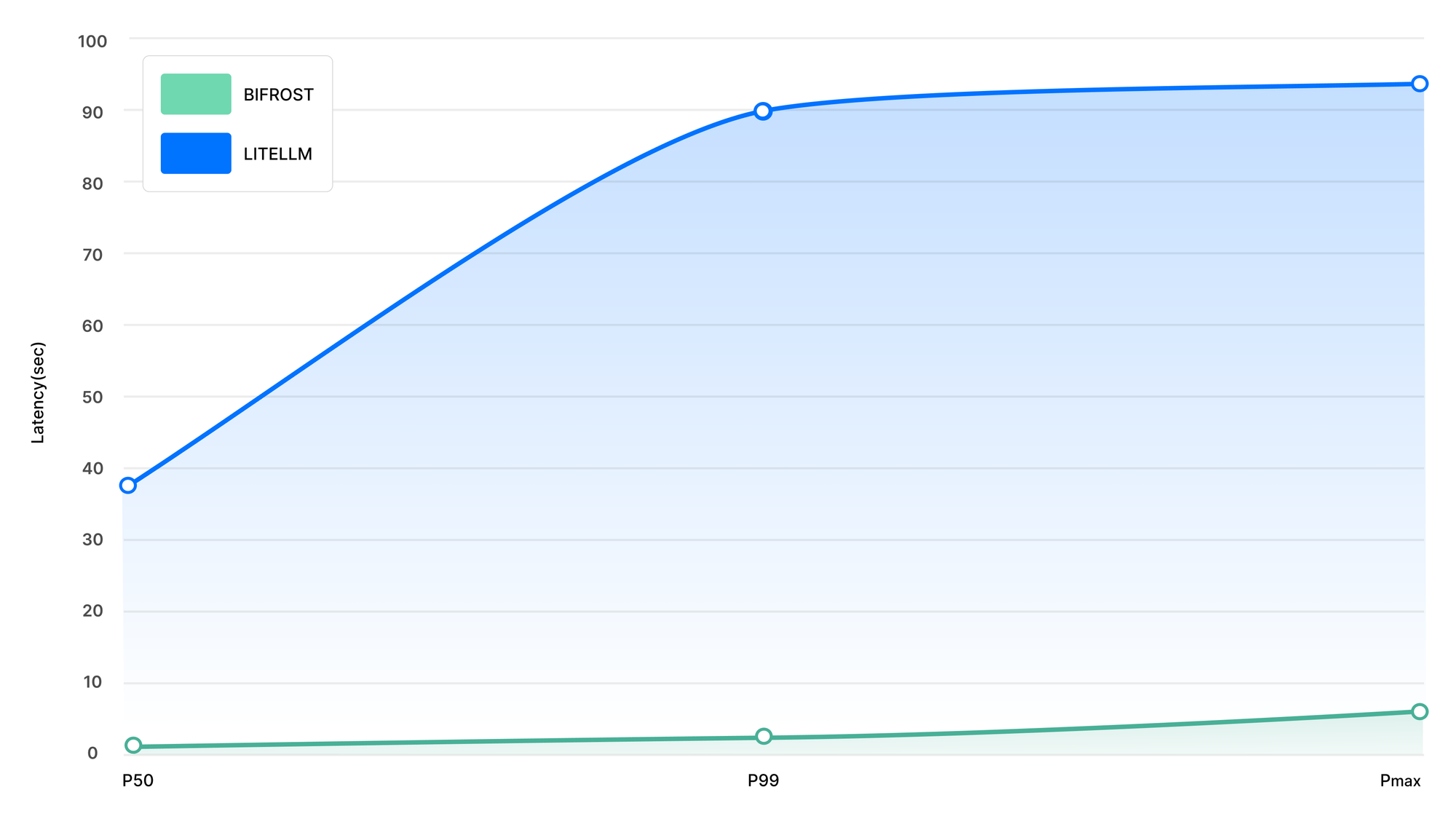
| P50 Latency | 804ms | 38.65s |
| P99 Latency | 1.68s | 90.72s |
| Max Latency | 6.13s | 92.67s |
| Throughput | 424/s | 44.84/s |
| Peak Memory | 120MB | 372MB |
Both Bifrost and LiteLLM were benchmarked on a single instance for this comparison.
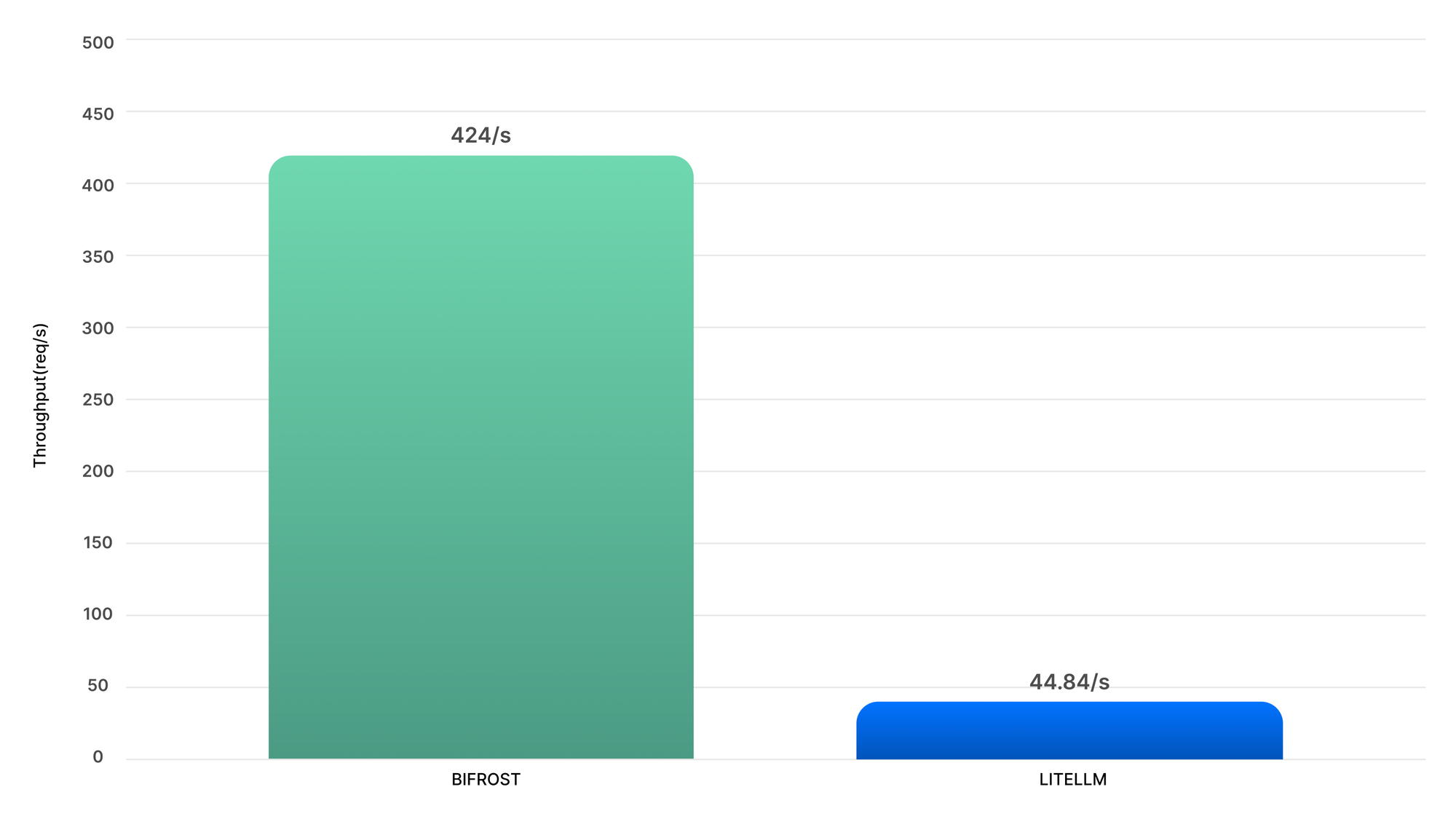
~9.5x faster, ~54x lower P99 latency, and uses 68% less memory than LiteLLM — on t3.medium instance (2 vCPUs) with tier 5 OpenAI Key.
We also ran a like-for-like benchmark based on the LiteLLM proxy’s own benchmarking setup - same load, same mocking behaviour, same hardware profile. Why? To get a clean, apples-to-apples comparison of real-world overheads from the gateway layer itself.
Below are the results comparing Bifrost and LiteLLM, both running on a single instance:
| Metric | Bifrost | LiteLLM |
|---|---|---|
| RPS | 500 | 475 |
| Median Latency (ms) | 60.99 | 100 |
| Latency Overhead | 0.99 ms | 40 ms |
Note: Latency Overhead = Median latency - mocked OpenAI call latency (60ms). This includes request/response parsing and all middleware logic.
If you’re building real LLM-powered products, Bifrost is the gateway designed to scale with you. No duct tape. No edge case rewrites. Just raw performance and production-ready control. In simple terms it's an abstraction layer that connects your application to multiple LLM providers with reliability, flexibility, and scale in mind.
How Bifrost is designed differently, and faster?
| Design Choice | Benefit | Impact |
|---|---|---|
| Go-based architecture | Single lightweight binary | <15µs overhead, 5,000+ RPS |
| Plugin-first middleware | No callback hell, clean data patterns | Write custom plugins in minutes |
| Multi-protocol support | HTTP/gRPC flexibility | Drop into any architecture |
| SDK-agnostic design | Just change the base URL | Works with OpenAI, Anthropic, Mistral, etc. |
| Native Prometheus | Built-in metrics, no setup | Production-ready observability |
Instead of tying your logic to individual APIs, you talk to Bifrost. It handles the complexity behind the scenes: Key rotation, Provider fallbacks, Input/output normalization, Retry logic, observability, and versioed configuration. Whether you're building an AI-powered feature or handling millions of requests a day, Bifrost gives you a consistent, fast, and configurable foundation to build on, so you can focus on your product, not the plumbing.
What Bifrost Does (and Doesn’t) Do
- Unified Gateway: Seamlessly connect to providers like OpenAI, Anthropic, Azure, Bedrock, and Cohere through a consistent, unified API.
- Fallback Mechanisms: Automatically falls back on failed requests to alternative providers, maintaining service continuity.
- Key Management: Handles API keys across multiple accounts and providers, including key usage weightage across different providers and model-specific key restrictions.
- Request/Response Normalization: Standardises inputs and outputs, allowing your application to remain agnostic to provider-specific formats.
- Connection Pooling: Efficient sync pools reduce memory overhead and speed up execution (zero runtime memory allocation when configured right).
- Full Configuration Control: Offers granular control over pool sizes, network retry settings, fallback providers, and network proxy configurations, ensuring optimal performance and adaptability. Bifrost provides sensible defaults but lets you tweak it for peak performance.
What Bifrost Doesn’t Do:
❌ Crash at scale: Bifrost is built to handle high-throughput traffic without buckling, even when things get extremely busy.
❌ Break your app with minor updates: We believe in versioned, predictable releases. No surprises, no silent regressions, and no “wait, why did that stop working?”
❌ Control your business logic: Bifrost stays in its lane, handling LLM plumbing while you focus on building actual product value.
❌ Lock you into a single provider: You're free to switch or mix providers like OpenAI, Anthropic, Mistral, Grok, or Bedrock without worrying about your LLM abstractions.
❌ Magically make you a better developer: But it will make your LLM stack cleaner, more scalable, and way less annoying to maintain.
How to Start Using Bifrost
Setting up Bifrost is very straightforward. There are two ways to use it: as an API server that your application calls, or directly as a Go package in your application.
Prerequisites
- Go 1.23 or higher (not needed if using Docker)
- Access to at least one AI model provider (OpenAI, Anthropic, etc.)
- API keys for the providers you wish to use
A. Using Bifrost as an HTTP Server
- Create
config.json: This file should contain your provider settings and API keys.
{
"openai": {
"keys": [{
"value": "env.OPENAI_API_KEY",
"models": ["gpt-4o-mini"],
"weight": 1.0
}]
}
}
- Setup your Environment: Add your environment variable to the session.
export OPENAI_API_KEY=your_openai_api_key;
Note: Make sure to add all the variables specified in your config.json file.- Start the Bifrost HTTP Server:You have two options to run the server, either using Go Binary or a Docker setup if go is not installed.
a. Using Go Binary
- Install the transport package:
go install github.com/maximhq/bifrost/transports/bifrost-http@latest
- Run the server (make sure Go is present in the PATH):
bifrost-http -config config.json -port 8080
b. OR Using Docker
- Download the Dockerfile:
curl -L -o Dockerfile https://raw.githubusercontent.com/maximhq/bifrost/main/transports/Dockerfile
- Build the Docker image:
docker build \
--build-arg CONFIG_PATH=./config.json \
--build-arg PORT=8080 \
-t bifrost-transports .
- Run the Docker container:
docker run -p 8080:8080 -e OPENAI_API_KEY bifrost-transports
Note: Make sure to add all the variables specified in your config.json file.- Using the API: Once the server is running, you can send requests to the HTTP endpoints.
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"provider": "openai",
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me about Bifrost in Norse mythology."}
]
}'
Built in Prometheus/Grafana Support at /metrics endpoint.B. Using Bifrost as a Go Package
- Go Get Bifrost: Run the following command to install Bifrost as a golang package in your project.
go get github.com/maximhq/bifrost/core@latest- Implement Your Account Interface: You first need to create your account which follows Bifrost's account interface.
type BaseAccount struct{}
func (baseAccount *BaseAccount) GetConfiguredProviders() ([]schemas.ModelProvider, error) {
return []schemas.ModelProvider{schemas.OpenAI}, nil
}
func (baseAccount *BaseAccount) GetKeysForProvider(providerKey schemas.ModelProvider) ([]schemas.Key, error) {
return []schemas.Key{
{
Value: os.Getenv("OPENAI_API_KEY"),
Models: []string{"gpt-4o-mini"},
},
}, nil
}
func (baseAccount *BaseAccount) GetConfigForProvider(providerKey schemas.ModelProvider) (*schemas.ProviderConfig, error) {
return &schemas.ProviderConfig{
NetworkConfig: schemas.DefaultNetworkConfig,
ConcurrencyAndBufferSize: schemas.DefaultConcurrencyAndBufferSize,
}, nil
}
Bifrost uses these methods to get all the keys and configurations it needs to call the providers. You can check Additional Configurations for further customisations.
- Initialize Bifrost: Set up the Bifrost instance by providing your account implementation.
account := BaseAccount{}
client, err := bifrost.Init(schemas.BifrostConfig{
Account: &account,
})
- Use Bifrost: Make your First LLM Call!
bifrostResult, bifrostErr := client.ChatCompletionRequest(
context.Background(),
&schemas.BifrostRequest{
Provider: schemas.OpenAI,
Model: "gpt-4o-mini", // make sure you have configured gpt-4o-mini in your account interface
Input: schemas.RequestInput{
ChatCompletionInput: bifrost.Ptr([]schemas.Message{{
Role: schemas.RoleUser,
Content: schemas.MessageContent{
ContentStr: bifrost.Ptr("What is a LLM gateway?"),
},
}}),
},
},
)
// you can add model parameters by passing them in Params: &schemas.ModelParameters{...yourParams} in ChatCompletionRequest.
For more settings and configurations, check out the Documentation.
Bonus: You can use Maxim’s pre-made plugin from github.com/maximhq/bifrost/plugins to add observability to Bifrost in just a single line!
- Install the package
go get github.com/maximhq/bifrost/plugins/maxim
- Observability is only 1 step away!
maximPlugin, err := maxim.NewMaximLoggerPlugin(os.Getenv("MAXIM_API_KEY"), os.Getenv("MAXIM_LOG_REPO_ID"))
client, err := bifrost.Init(schemas.BifrostConfig{
Account: &account,
Plugins: []schemas.Plugin{maximPlugin},
})
Get your Maxim API Key and Log Repo ID from here.
Benchmarks
We’ve stress-tested Bifrost under 5000 RPS on real AWS infrastructure to see how it performs under load. TL;DR: it holds up extremely well with single-digit microsecond latency overhead and full success rates, even under pretty lean configurations.
Test Environment
We ran Bifrost inside Docker containers with realistic memory and CPU limits, across two common EC2 instance types:
- t3.medium (2 vCPUs, 4GB RAM)
- Buffer Size: 15,000
- Initial Pool Size: 10,000
- t3.xlarge (4 vCPUs, 16GB RAM)
- Buffer Size: 20,000
- Initial Pool Size: 15,000
Performance Metrics
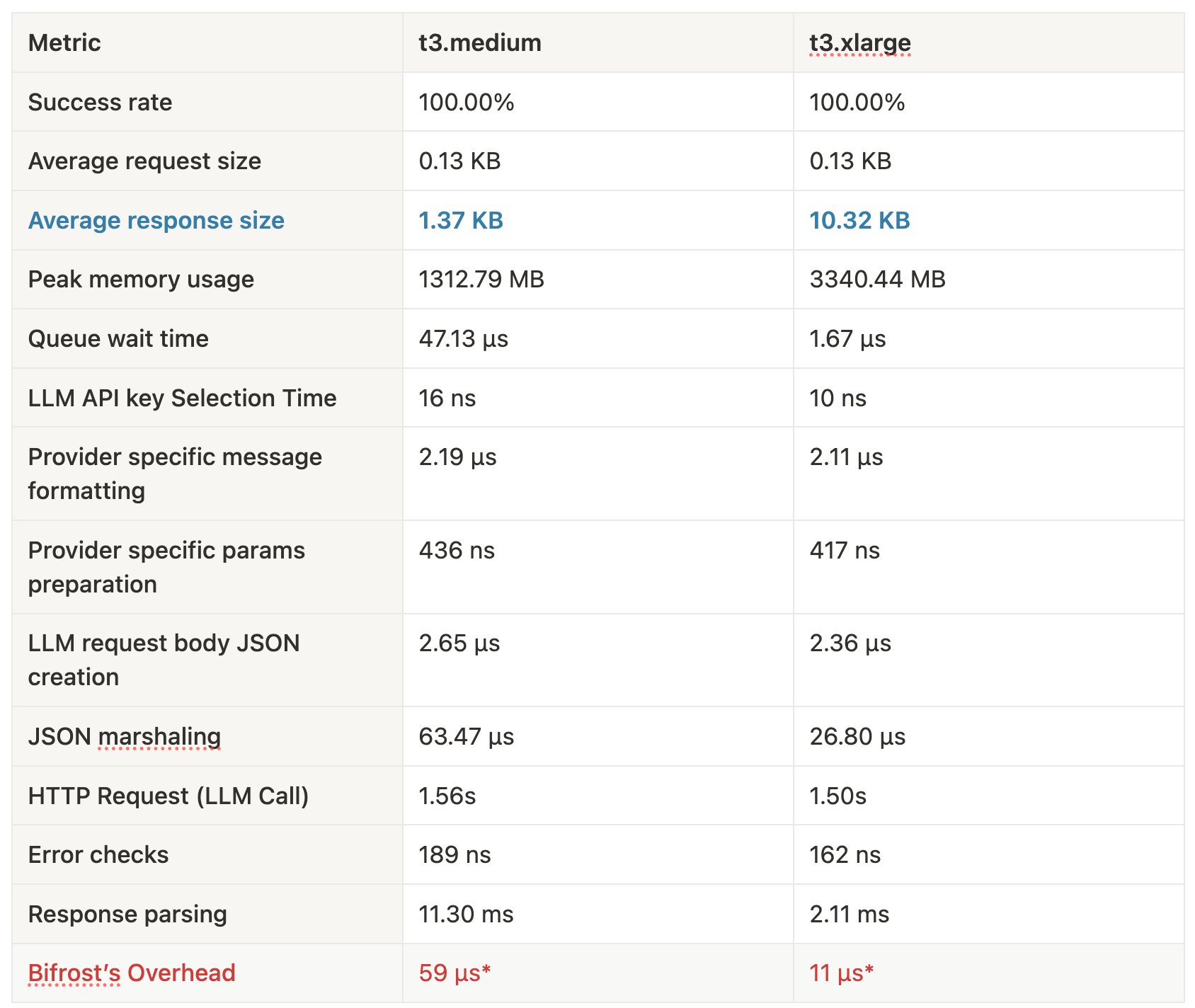
*Bifrost's overhead is measured at 59 µs on t3.medium and 11 µs on t3.xlarge, excluding the time taken for JSON marshalling and the HTTP call to the LLM, both of which are required in any custom implementation.
Note: On thet3.xlarge, we tested with significantly larger response payloads (~10 KB average vs ~1 KB ont3.medium). Even so, response parsing time dropped dramatically thanks to better CPU throughput and Bifrost's optimized memory reuse.
Why This Matters?
These aren’t synthetic hello-world tests. This is Bifrost running at 5K RPS, with full HTTP calls to upstreams, memory pooling enabled, and all core middlewares active.
- Even the t3.medium (an entry-level instance) handled it without flinching.
- On the xlarge, latency dropped across all internal steps.
- Total overhead? Less than 15µs added per request on average.
- All of this is configurable - you decide the pool sizes, retry logic, and buffer depths based on your needs. Want low memory? Dial the pools down. Want throughput? Turn it up. Either way, you’re not rewriting code, you’re just flipping knobs.
Curious? Run your own benchmarks. The Bifrost Benchmarking repo has everything you need to test it in your own environment.
Open Source and Built for the Community
Bifrost is fully open source, developed with transparency and extensibility at its core. It's licensed under Apache 2.0 and hosted on GitHub, where the codebase is actively maintained by contributions from the Maxim team at the moment. It's designed to be transparent, extensible, and community-driven from day one.
We believe infrastructure like this should be built in the open, shaped by real-world needs, and available for anyone to use, improve, or extend. Whether you're running Bifrost in production or experimenting on a side project, you're part of the community.
From clean abstractions to detailed documentation, everything in Bifrost is designed to be approachable. If something’s missing, confusing, or could be better, you're encouraged to help make it so.
What’s Next / Contribution Guide
We’re just getting started. The core foundation of Bifrost is stable and production-ready, but the roadmap is full of exciting directions for more provider integrations and plugins. We welcome contributions of all kinds, whether it's bug fixes, features, documentation improvements, or new ideas. Feel free to open an issue, and once it's assigned, submit a Pull Request.
Here's how to get started (after picking up an issue):
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request and describe your changes
Even if you’re not writing code, feedback, docs, use cases, and real-world stories are all valuable. Bifrost is better because of its community, and we’d love for you to be part of it.
Built with ❤️ by Maxim


