Beyond Autoregression: LLaDA2.1 and the Case for Self-Editing Language Models

Introduction
Every mainstream large language model today generates text the same way: one token at a time, left to right, no looking back. It works remarkably well, but it has a structural flaw that's easy to overlook until you care about speed at scale. The model can never go back and fix a mistake. Once a token is committed, everything downstream conditions on it, errors included. Diffusion language models (dLLMs) offer a theoretical alternative: start with a sequence of [MASK] tokens and iteratively "denoise" them into real text, in parallel. But in practice, dLLMs have been stuck in a frustrating middle ground. They're fast at generating drafts, but those drafts are riddled with inconsistencies because each token is decoded independently. And the standard mask-to-token (M2T) approach offers no mechanism to go back and fix errors once tokens are committed.
LLaDA2.1, from Ant Group's InclusionAI team, doesn't try to patch around this limitation. It confronts it head-on by introducing a mechanism that lets the model edit already-generated tokens during the diffusion process, not just unmask new ones. And it pairs this with the first large-scale reinforcement learning framework designed for diffusion LLMs. The result is a 100B-parameter model that hits 892 tokens per second on HumanEval+ while staying competitive on quality across 33 benchmarks. Those two things weren't supposed to happen at the same time.
The problem: parallel decoding is fast but fragile
In the conventional dLLM setup, the model starts with a fully masked sequence and progressively unmasks tokens based on confidence thresholds. If the model is confident enough about a position, it commits a token there. This M2T process is inherently parallel: the model can unmask hundreds of positions in a single forward pass.
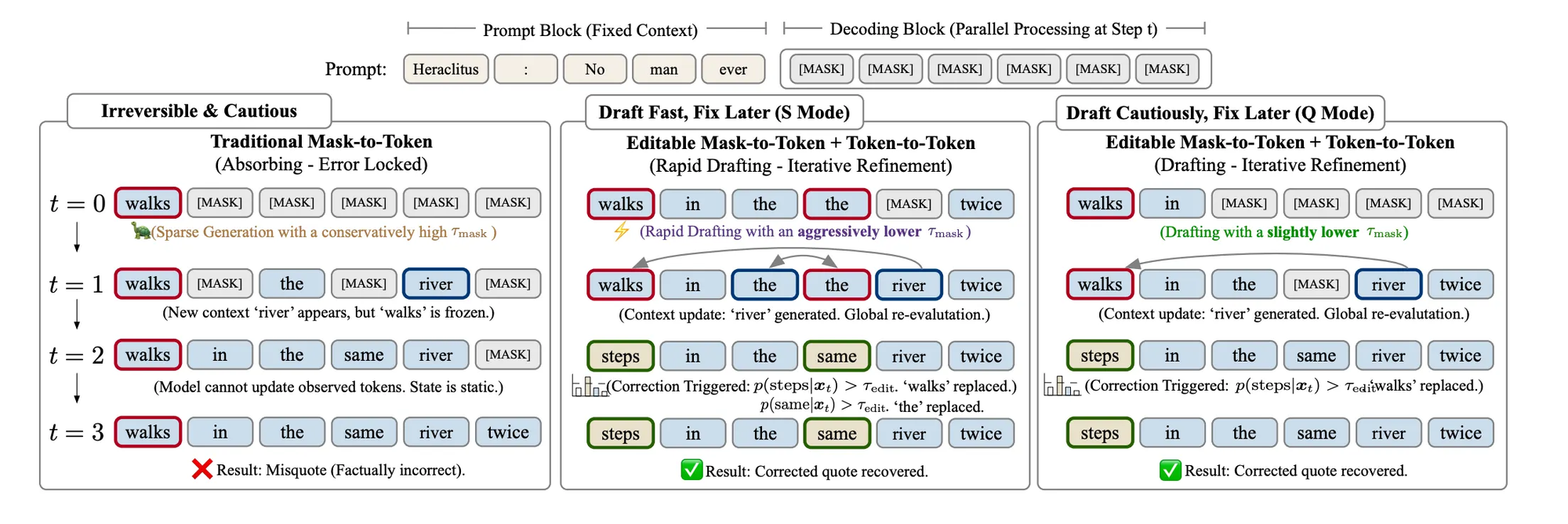
The problem is what happens when the model gets something wrong. Once a token is placed, it stays. If position 47 gets "walk" when it should have gotten "step," every subsequent denoising step conditions on that error. This creates a dilemma: set your confidence threshold high, and you get accurate but slow generation. Set it low, and you get fast but noisy output with compounding errors. There's no middle ground, just a cliff between speed and quality.
LLaDA2.0 proved you could scale diffusion models to 100B parameters and reach 535 tokens/second. But it also honestly acknowledged that the speed-quality tradeoff remained binary. You could be fast or you could be good.
LLaDA2.1's core move: draft first, edit after
The way I read LLaDA2.1 is this: instead of trying to get every token right the first time, accept that parallel decoding will produce errors and build a mechanism to fix them on the fly.
The paper introduces Token-to-Token (T2T) editing alongside the existing M2T unmasking. At each denoising step, the model now maintains two dynamic sets. The Unmasking Set covers positions where [MASK] tokens are replaced with real tokens, same as before. The Editing Set covers positions where an already-committed token is replaced with a better one because the model's confidence has shifted given new context.
Think of it like writing a first draft and revising simultaneously. The model aggressively fills in blanks (M2T) while scanning what it's already written and fixing anything that looks wrong (T2T). Both operations happen in the same forward pass, governed by two separate confidence thresholds. Because the model can now correct its own mistakes, you can afford to be much more aggressive with the initial unmasking threshold. The rigid tradeoff between speed and quality becomes a continuous, tunable spectrum.
One model, two personas
LLaDA2.1 crystallizes the tunable threshold idea into two explicit operating modes within a single model.
Speedy Mode (S Mode) drops the M2T confidence threshold aggressively. The model accepts more tokens per step, even uncertain ones, and relies heavily on T2T editing to clean up. This is where you get the headline numbers: 892 TPS on HumanEval+, 801 on BigCodeBench. It's optimized for scenarios where throughput matters more than perfection.
Quality Mode (Q Mode) takes the conservative path. Higher thresholds mean fewer tokens accepted per step, but each one is more likely correct. Less editing needed, higher benchmark scores, slower throughput. This is for critical reasoning and production deployments where accuracy is non-negotiable.
The important thing: this isn't two separate models. It's one set of weights with different inference configurations. Previous LLaDA iterations required separate model versions for speed versus quality, doubling management overhead. Now you adjust a threshold parameter and get a different point on a smooth speed-quality curve.
Training the model to be its own editor
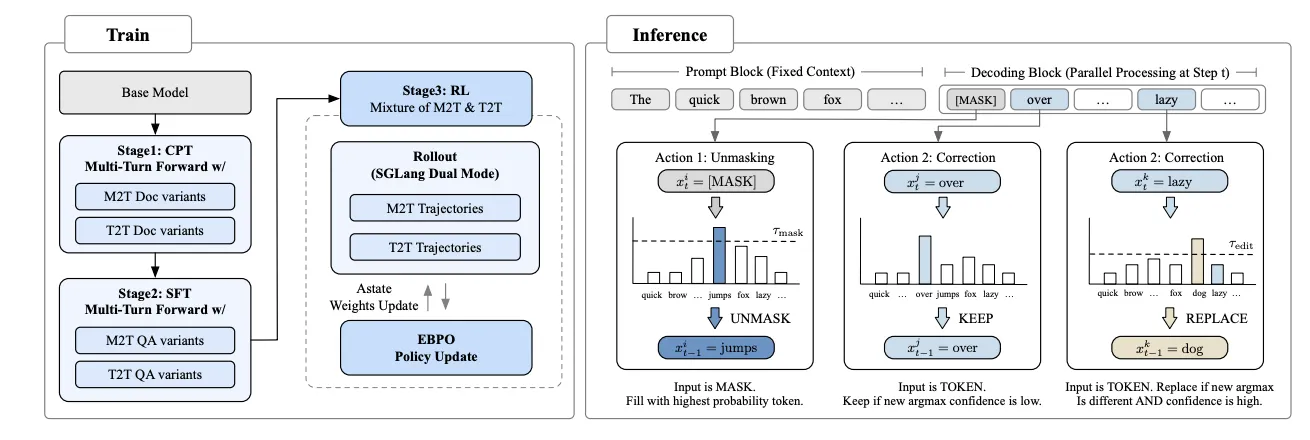
You can't just bolt an editing mechanism onto inference and expect it to work. The model has to learn how to edit during training.
LLaDA2.1 uses a unified training objective they call the Mixture of M2T and T2T. During both continual pre-training and supervised fine-tuning, the model is exposed to two types of tasks simultaneously. The M2T stream trains it to fill in masked positions. The T2T stream deliberately introduces perturbed tokens and trains the model to identify and fix them. This dual-stream approach ensures the model develops both capabilities in a single parameter space.
They also introduce Multi-turn Forward (MTF) data augmentation, which simulates iterative editing scenarios the model will encounter during inference. Instead of seeing one-shot corrections, the model practices multiple rounds of refinement.
The RL stage is perhaps the most technically ambitious piece. Applying policy gradients to block-autoregressive diffusion models hits a fundamental wall: you can't easily compute the sequence-level log-likelihood that standard methods require. The paper's solution is EBPO (ELBO-based Block-level Policy Optimization), which approximates this using block-conditional probabilities computed in parallel under a block-causal mask. This is the first time anyone has applied RL at this scale to a diffusion language model, and the fact that it works without collapsing the parallel decoding advantage is significant.
Experiments: what changes in practice
Across 33 benchmarks, the results tell a consistent story. In Q Mode, LLaDA2.1 outperforms LLaDA2.0 on both the mini (16B) and flash (100B) versions, so the new architecture isn't just faster, it's better at the quality end too. In S Mode, task scores dip slightly, but throughput jumps dramatically.
The speed numbers are where things get striking. LLaDA2.1-Flash in S Mode hits 892 TPS on HumanEval+, 801 on BigCodeBench, and 663 on LiveCodeBench. After quantization, the mini version pushes to 1,587 TPS. These aren't cherry-picked results on trivial tasks. These are complex coding benchmarks requiring logical consistency and syntactic correctness.
Multi-Block Editing (MBE) adds another dimension. By allowing the model to revisit previously decoded blocks based on newly generated context, MBE consistently improves scores on reasoning and coding benchmarks with only modest throughput reduction. The domain breakdown is also revealing: coding tasks benefit most from aggressive speed settings, likely because code has strong structural constraints that make T2T editing particularly effective. Instruction-following tasks show more sensitivity to threshold settings, which makes sense given their open-ended nature.
When diffusion models still fall short
Despite the impressive speed numbers, diffusion language models still exhibit higher base error rates than autoregressive models. The editing mechanism compensates for this, but it's compensation, not elimination. Under very aggressive masking settings, the model can still produce what the paper calls "stuttering" artifacts, essentially n-gram repetitions where phrases or words loop on themselves, a direct consequence of independent parallel sampling.
The inference infrastructure described in the paper (Alpha-MoE megakernels, per-block FP8 quantization, customized SGLang, radix caching) isn't something you spin up over a weekend. And the paper acknowledges a key gap: the RL stage and T2T editing mechanism currently operate separately. Future work aims to merge them, using RL to directly optimize self-correction behavior. That could be transformative, but it's not here yet.
If your bottleneck isn't token-level throughput on structured tasks, LLaDA2.1 definitely isn't your next deployment. But if you're doing high-volume code generation or batch processing where tokens-per-second directly impacts cost, this is worth watching closely.
Conclusion
The core tension in diffusion language models has always been the same: parallelism gives you speed, but independence gives you errors. Every prior attempt to solve this was essentially choosing a point on that tradeoff curve and living with it.
LLaDA2.1 shows that the curve itself can be reshaped. By making editability a first-class capability, trained into the model rather than bolted on at inference, it transforms the binary speed-quality tradeoff into a configurable spectrum. The deeper lesson isn't about diffusion models specifically. It's about the value of architectures that can revise their own output. Autoregressive models are getting faster through speculative decoding and hardware optimization, but they're still structurally unable to go back and fix mistakes. LLaDA2.1 suggests that self-correction during generation isn't just a nice-to-have. It might be a fundamental capability that any high-throughput generation system eventually needs.
For a deeper dive into the paper and the math behind the decoding and training framework - LLaDA2.1: Speeding Up Text Diffusion via Token Editing


