Base vs. Aligned: Why Base LLMs Might be Better at Randomness and Creativity

Introduction
As large language models (LLMs) continue to improve in tasks ranging from education to enterprise automation, alignment techniques like Reinforcement Learning from Human Feedback (RLHF) have become the standard. These methods make models safer, more helpful, and generally better at following instructions. However, recent findings challenge the assumption that alignment always enhances a model's utility.
In this blog, we delve into a recent paper that systematically investigates how alignment affects a model's performance on tasks requiring unpredictability such as random number generation, strategy games, and creative writing. Their interesting conclusion is that base models outperform aligned ones when unpredictability is crucial.
Why Unpredictability Matters
In many real-world scenarios, predictability is a weakness. Consider:
- Game theory: Success in games like Rock-Paper-Scissors or Hide & Seek hinges on mixed strategies essentially, randomizing your choices.
- Creative writing: The hallmark of impactful art is originality, which often stems from unpredictability.
- Secure systems: Random number generation is fundamental in cryptographic protocols and simulations.
Unfortunately, these capabilities seem to degrade as LLMs undergo alignment procedures meant to make them more human-friendly.
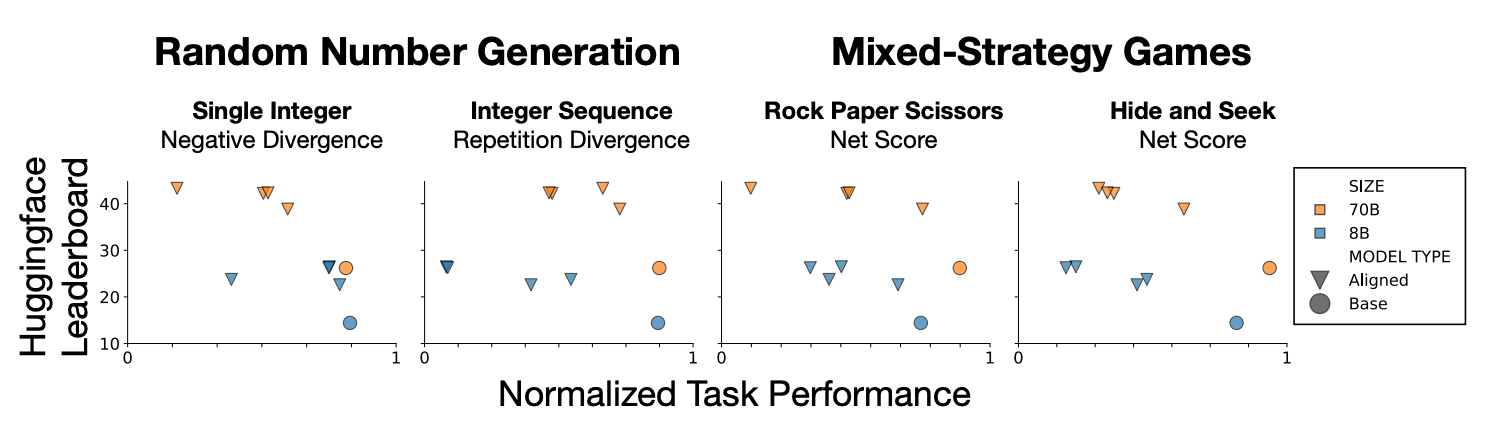
Experiment 1: Can LLMs Generate Random Numbers?
Setup
The authors tested several variants of LLaMA 3.1 (8B and 70B), both base and aligned, on their ability to generate:
- Single random integers between 0 and 10.
- Sequences of 10 such integers.
Findings
- Bias Toward 7: Aligned models overwhelmingly prefer the number 7, a well-known human bias, deviating significantly from uniform randomness.
- Reduced Repetition: Aligned models avoid repeating numbers in sequences i.e. a heuristic that feels more random to humans but is actually less random in statistical terms.
- Larger Isn’t Better: Surprisingly, 70B models were worse than 8B models at mimicking true randomness.
Experiment 2: Playing Mixed Strategy Games
In competitive games, randomness ensures resilience against adversaries. The researchers evaluated models in:
Rock-Paper-Scissors
- Adversary: A greedy agent with access to model output probabilities.
- Result: Aligned models became more deterministic after winning or tying, mirroring human overconfidence.
- Best Performer: The base model consistently held the highest net score.
Hide & Seek
- A one-vs-one game with 7 hiding spots.
- Goal: Avoid being found by an adversary guessing the most probable spot.
- Outcome: Base models again dominated, achieving scores closest to the theoretical optimum.
Insight: Alignment not only fails to help, it even actively makes models vulnerable by eliminating beneficial randomness.
Experiment 3: Creative Poetry Generation
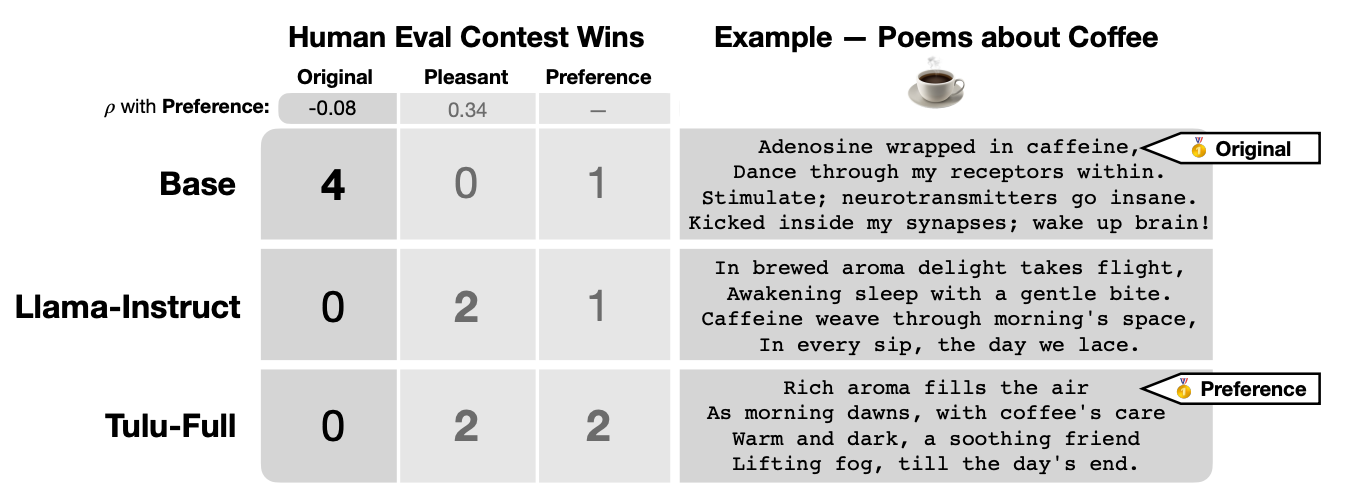
Using human evaluators, the study compared poems generated by base and aligned 70B models on:
- Originality
- Pleasantness
- Overall preference
Key Takeaways:
- Base models were rated highest for originality in all prompts.
- Aligned models won for pleasantness and were generally preferred by annotators.
- Correlation: Pleasantness correlated positively with preference (ρ = 0.34), but originality correlated negatively (ρ = –0.08).
This suggests that alignment optimizes for likeability rather than artistic merit, potentially reducing the creative expressiveness of models.
The Tradeoff: Safety vs. Serendipity
The research reveals a crucial tension:
The more a model is optimized to be safe and helpful, the less capable it becomes in tasks requiring serendipity or strategic unpredictability.
While alignment improves benchmark performance and user safety, it appears to suppress latent capabilities critical for gaming, negotiation, ideation, and art.
Implications
For Developers:
- Don’t always default to aligned models for tasks needing creativity or randomness.
- Consider fine-tuning base models for specific domains like game theory or generative art.
For Researchers:
- Future alignment techniques should aim to preserve or explicitly recover unpredictability when needed.
- Investigate hybrid methods such that we can conditionally unlock base behavior?
For Users:
- Understand the tradeoff in behavior between aligned model helpfulness and open-ended creativity.
- Sometimes the raw base model might surprise you in a good way.
Conclusion
The authors challenge a fundamental assumption of modern AI practice that alignment is always beneficial. Their work offers compelling evidence that base models, though less safe or controllable, often retain essential capabilities that alignment dampens.
As the field matures, we may need to rethink alignment not just as a safety mechanism but as a dial, balancing predictability with unpredictability depending on the task.
To learn more, read the paper: https://arxiv.org/pdf/2505.00047


