Inside OpenAI’s o1: Part 1
Introduction
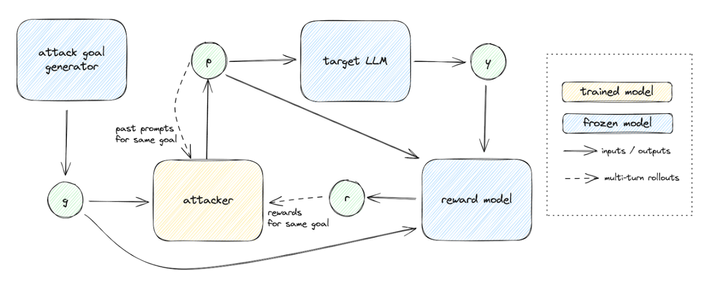
The o1 family of models is trained using reinforcement learning to perform complex reasoning. It is baking in the now familiar chain of thoughts before giving the output. Through the training, the models learn to refine their thinking, explore different strategies, and identify mistakes in those exploration paths. It