AgentFold : What If AI Agents Managed Memory Like Humans Do?

Introduction
If you've spent time working with LLM agents for web research, coding assistance in cursor or even extended conversations in ChatGPT, you've probably noticed something: as tasks or multi turn conversations grow longer and more complex, the quality of responses deteriorates - essentially because of context overload. I've experienced this firsthand with both Cursor (for coding) and Exa (for web research). Summarization works reasonably well in coding contexts where you're iterating on the same files / codebase and can compress completed refactors. But in web research? I’m not sure summarisation is the best solution. When you're searching across dozens of sources, each containing fragments of the answer, aggressive summarization becomes risky. That crucial detail from an early source - the one you'll need to connect dots 50 steps later - gets compressed away because it seemed less relevant at the time.
Here's the current landscape: today's agents face a difficult trade-off. They either retain every interaction in full (which leads to noise overwhelming the signal after dozens of steps), or they compress history progressively (which risks losing critical information). Consider the compounding effect: even with a conservative 1% information loss per compression step, by step 100 only 37% of early findings remain intact. For tasks like deep research or complex investigations that demand reasoning over hundreds of steps, this has been a real constraint. The recently published AgentFold framework tackles this head-on with a fundamentally different (and interesting) approach to how agents manage their working memory. Let’s dig into it.
AgentFold: What If Context Was a Workspace, Not a Log?
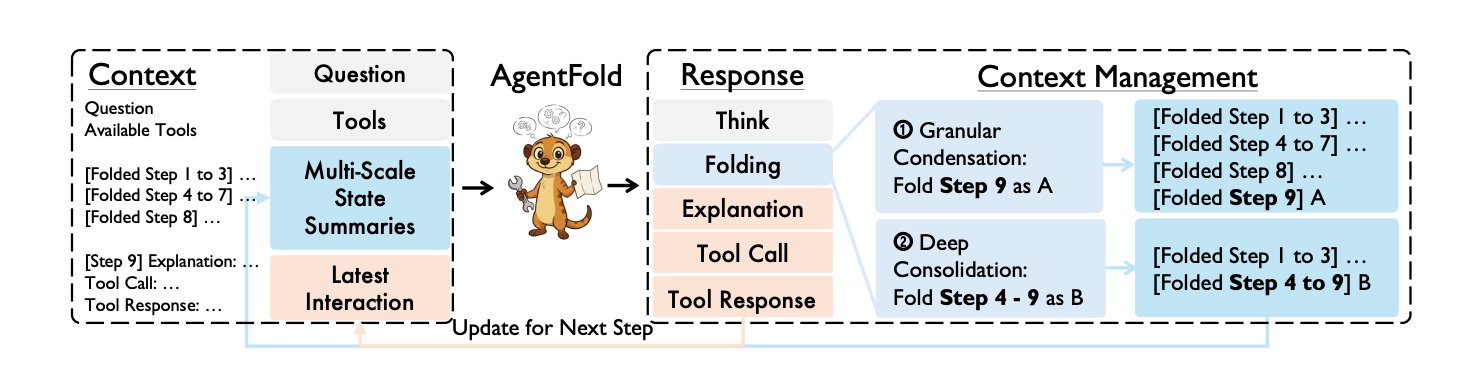
AgentFold reframes how we think about context. Instead of treating it as a passive history dump, it treats context as a dynamic workspace that the agent actively manages, much like how humans handle complex projects.
When you're working on something that spans days or weeks, you don't remember everything equally. You keep recent details fresh, compress completed sub-tasks into conclusions ("tried approach X, didn't work"), preserve critical findings at full detail ("this API endpoint returns format Y"), and discard noise entirely. AgentFold formalizes this into an architecture where context has two parts:
- Multi-Scale State Summaries: Compressed historical blocks where each block can represent either a single important step OR an entire folded sub-task
- Latest Interaction: The full, uncompressed record of the most recent action - nothing lost yet
At every step, the agent makes two decisions: what action to take next, and how to fold its memory - which parts of history to compress, at what granularity, and when.
Two Types of Folding: Granular vs. Deep
AgentFold operates with a dual-scale folding mechanism:
Granular Condensation
When a step contains important information that might be needed later, the agent performs a granular fold - compressing just that one step into a distinct summary block. This protects critical details from being lost in future consolidations.
Example: [Compressed Step 5] Found API endpoint /v2/users returns JSON with 'created_at' timestamp in UTC format
Deep Consolidation
When the agent completes a sub-task or realizes a line of investigation is a dead end, it performs a deep fold - merging multiple steps (sometimes 10+ steps) into a single coarse-grained summary.
Example: [Compressed Step 6 to 16] Attempted to locate GPS coordinates for target location via multiple map services and business directories. All attempts unsuccessful. Coordinates remain unknown.
This is where it gets clever. Look at Figure 5 in the paper: after spending 11 steps failing to find McDonald's coordinates through different methods, AgentFold recognizes the dead end, folds steps 6-16 into one conclusive statement, and pivots strategy. It's not just saving tokens - it's learning from failure and cleaning up its workspace to think clearly about what to try next.
How They Built It: Fine-Tuning, Not Prompting
Here's something critical that's easy to miss: AgentFold isn't achieved through clever prompting. The authors tried that. It doesn't work.
Getting an LLM to reliably output structured, multi-part responses (thinking → folding directive → explanation → tool call) while also making intelligent folding decisions? That requires the behavior to be baked into the model weights.
Their approach:
- Fold-Generator Pipeline: Built a specialized data collection system using powerful LLMs to generate training trajectories demonstrating sophisticated folding behaviour
- Rejection Sampling: Filtered out any trajectory with formatting errors or environmental failures - only clean, correct examples make it through
- Supervised Fine-Tuning: Trained Qwen3-30B on these curated trajectories
The resulted in a 30B parameter model that intrinsically knows when and how to fold well!
The Results: Small Model, Massive Performance
The benchmarks are striking:
Context Efficiency
By step 100, a standard ReAct agent is using 80k+ tokens. AgentFold? Just ~7k tokens. That's a 92% reduction and translates to roughly 7GB of memory savings per inference instance.
But here's what's wild: they scaled AgentFold to 500 steps, and the context size sometimes actually decreased as the agent folded away completed investigations. Most agents break down around 64-100 steps due to context saturation. AgentFold kept going.
Benchmark Performance
On BrowseComp (a challenging benchmark for web browsing agents that tests the ability to locate hard-to-find information through multi-step web navigation), their AgentFold-30B achieved 36.2% accuracy.
Compare that to:
- DeepSeek-V3.1 (671B parameters): 30.0%
- GLM-4.5 (355B parameters): 26.4%
- OpenAI o4-mini: 28.3%
Their 30B fine-tuned model is beating models 20x its size and matching proprietary frontier agents. They also tested scaling properties: when they increased the turn limit from 16 to 256 steps, GLM-4.5's performance plateaued and crashed beyond 64 turns (context overload). AgentFold's accuracy kept climbing steadily - the longer it could run, the better it performed.
Why This Matters Beyond Web Agents
While AgentFold was demonstrated on web research tasks, this problem and this solution can be applied to any long-horizon agent task:
- Research assistants synthesizing information from dozens of papers
- Customer service bots handling complex, multi-turn troubleshooting
- Data analysis agents running exploratory workflows with hundreds of intermediate steps
The core insight is universal: agents need to actively manage their memory, not passively accumulate it.
Limitations Worth Considering
No approach is perfect. A few things to think about:
Generalization Beyond Web Search
While the paper demonstrates AgentFold on information-seeking benchmarks, it's an open question how well this exact architecture transfers to fundamentally different domains. Coding tasks, for instance, might need different folding heuristics than web research.
When Folding Goes Wrong
The paper shows impressive results, but what happens when the agent makes a bad folding decision? If it prematurely consolidates information that turns out to be critical 200 steps later, there's no recovery mechanism. The authors acknowledge this ("irreversible loss") but it's worth noting that AgentFold trades the certainty of context saturation (ReAct) for the risk of premature information loss (though that risk is much lower than uniform summarization).
What's Next
The authors note they kept the training approach simple (just SFT) to prove the paradigm works. The obvious next step? Reinforcement learning to let agents discover even more sophisticated, non-obvious folding policies by directly optimizing for task success.
Imagine agents that learn:
- When to speculatively preserve details that might matter later
- How to recognize patterns in dead ends and fold them more aggressively
- Task-specific folding strategies (web research vs. coding vs. data analysis)
The Takeaway
If you're building agents that need to handle complex, multi-step tasks - whether for web research, coding, or any domain requiring long-horizon reasoning - context engineering can't be an afterthought anymore.
AgentFold shows us that the future of capable agents isn't just bigger context windows or smarter prompts. It's agents that curate, abstract, and forget strategically - just like we do.
The context crisis has a solution. And it looks a lot like teaching our agents to think like investigators, not archivists.
AgentFold paper: arXiv:2510.24699
Code & models: GitHub - Alibaba-NLP/DeepResearch


