A Recipe for Privacy Preserving Autocorrect in GBoard: FL, DP, and Synthetic Data Sprinkles

The Personalisation Paradox
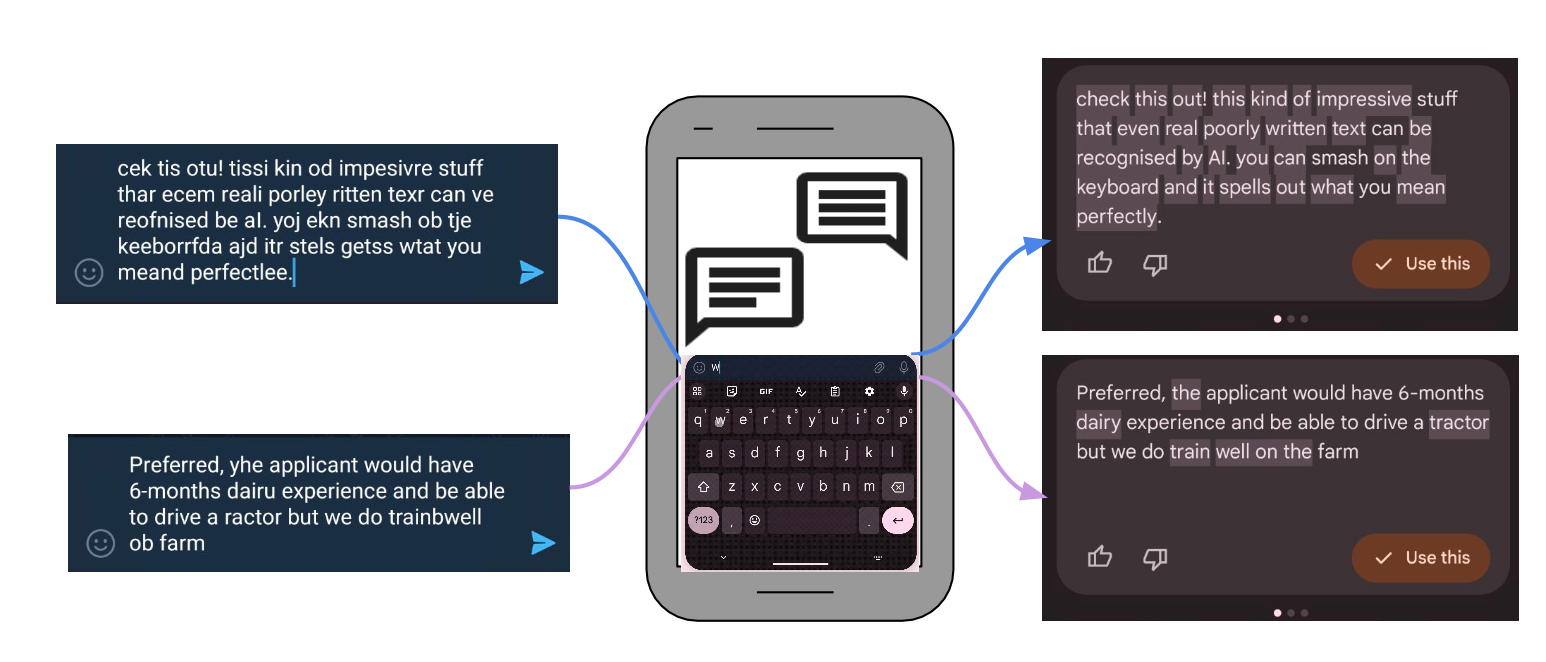
Training language models for tasks such as autocomplete or error correction isn’t just a matter of fixing typos. Sure, you can turn “pleaes” into “please”, that’s easy. But what about Dave, who always types “frmly” when he means “formally”? You don’t just need autocorrect, you need your autocorrect. Getting that right requires personalisation. And personalisation means data. Here’s the catch: you can’t look at the very data you need. What people type on their phones is private, personal, and often wildly sensitive. Using it directly for training? Yeah, that’s a one-way ticket to privacy jail.
Not only that, the non-private data you have access to, the public web data, it isn’t quite representative of user typing data obtained from mobile phones (Fig-1). Using that directly ends up being low-signal.
So, how do you get better without ever seeing the thing you're trying to get better at?
God Bless GBoard (and the researchers behind it)
Long before GPTs were talk of the town, before “on-device LLM” was something startups were pitching at $100M valuations, the engineers at Google were quietly solving one of the messiest ML problems in production: how do you personalise language models without ever seeing user data? Enter Federated Learning.
Standard machine learning involves accumulating data and then training a model using that. Federated learning (FL) flips this paradigm. Instead of shipping your data to the model, you ship the model to various data owners. Users train the model on their data for an epoch and send back the gradients to the central model. The accumulated gradients are aggregated (via averaging or something else), an update is made to the central model, and the updated model is sent to the users for further training, this loop continues. In the context of GBoard this works as follows:
- Your phone locally trains on your keystrokes (yes, on your own device)
- It computes a weight update: basically “Hey model, here’s how you can improve based on what I type”
- It sends back just that update, not the data itself.
- Google aggregates updates from lots of phones and applies them to improve the central model.
It’s like crowdsourcing personalisation without ever peeking at what the crowd said. Unfortunately, while FL doesn’t share your data directly, it doesn’t provide a privacy guarantee. A significant section of AI Safety research is dedicated to creating adversarial attacks to find gaps that can be leveraged by attackers. Such attacks have uncovered vulnerabilities within FL that may lay to privacy leakage. The solution to this? Differential Privacy (DP).
Here’s a quick refresher on DP. Imaging plotting your datasets by frequency of occurrence. Look closely and you’ll find a structure: common patterns in the centre , rare(and often sensitive) stuff on the long tail ends. These tails are where PII hides: the uncommon names, weird typing habits, phrases unique to you, or one-off typos that make the data yours.
Now, the gradients computed during training reflect this distribution. Rare data points can lead to large or unique gradient updates, which in turn become privacy risks. An attacker can potentially trace those gradients back to specific inputs. DP tackles this in two steps:
- Gradient Clipping: Each user’s gradient update is clipped to a fixed norm. This prevents any single user from dominating the learning signal, especially if their data is outlier-ish.
- Noise Addition: Then it sprinkles in carefully calibrated random noise, usually sampled from a Gaussian or Laplace Distribution. This makes it statistically hard to reverse-engineer any one user’s data.
The result? A mathematically provable privacy guarantee, controlled by two parameters:
- ε (epsilon): the privacy budget, ie, how much privacy you’re spending to retain utility.
- δ (delta): the small probability that privacy could fail.
Lower delta means stronger privacy, but worse model utility. It’s a trade-off, and tuning this trade-off is basically half the game in privacy-preserving ML.
Circling back to GBoard, the team uses a strong DP variant called BLT-DP-FTRL which blends FTRL (Follow-the-Regularised-Leader) optimisation with DP. It also uses the BLT (Bloom-Light-Tail) mechanism to calibrate noise more effectively. This leads to better privacy-utility trade-offs and scalability.
Why FL + DP Still Falls Short (and SynthData Steps In)
So far, we’ve established that GBoard uses FL to keep user data local, and DP to add a formal privacy guarantee. Problem solved, right?
Not quite.
Here’s the bit: DP doesn’t just hide rare user data, it silences it. And in the world of personalisation, rare is everything.
Dave’s habit of typing “frmly” instead of “formally” is:
- low frequency (he’s likely the only one doing it)
- high value (it’s core to tailoring the model to him)
- easily drowned out by the DP noise.
So while FL+DP ensure data privacy, the personalisation signal ends up being crippled. This holds especially true for:
- edge-case typos
- personal slang
- low-resource languages or dialects
- unusual phrasing or grammar.
The core realisation here becomes: If we can’t trust the model to learn from real private data, maybe we can teach it with fake-but-useful data instead. This is where Synthetic Data comes in.
A recent paper by Google proposes a pipeline for generating synthetic data tailored to the error-correction task, but does so without touching real user keystrokes. The goal is to recover some of that long-tailed personalisation signal that DP tends to suppress without violating privacy.
In essence:
- FL keeps the model training local.
- DP keeps the the training data private.
- Synthetic data keeps the training useful.
It’s like summoning the ghosts of private data, but using public corpora and small LMs, not surveillance.
Crafting Synthetic Data For Error Correction
The paper at hand proposes a pipeline for realistic synthetic data creation with three core steps:
- simulate typing errors in public data
- reweigh samples based on relevance to real-world data
- continue training on reweighted data
Step-1 : Error Generation Using a Small LM
Start with a clean, public dataset, C4 in this instance. Sample the dataset to get a smaller yet diversity rich subset, with shorter examples mimicking texting patterns. The sampling uses a clustering based mechanism in this case. Next, these clean texts are “corrupted” with two kinds of errors: grammar errors and typing errors. The grammar error is added by Gemini Ultra using the prompt template in Table-1.

The grammatical errors are related to verbs (52%), missing words(15%), plural terms (10%) and capitalisation (5%). The typing errors are added using heuristic rules, that induce errors such as transposition, omission, repetition and spatial errors. The compiled dataset is then filtered and finally takes the structure of a pair of (corrupted, clean) sentences. This is referred to as the EC-synth dataset.
Step-2: Privacy Preserving Domain Adaptation by Reweighing
Here’s the interesting bit: not all errors are equally useful. Some generated samples may be too weird, some might be too clean. So how do you determine how realistic a synthetic data sample is without comparing it to the real private data?
Easy, you do it indirectly.
Start by training two small language models, each around 8 million parameters:
- Sp: trained purely on the public C4 dataset
- Sf: initialised from Sp, but further fine-tuned on private user data via a production Federated Learning setup with formal DP guarantee. This means Sf captures domain-specific signals from real mobile text while keeping strict privacy guarantees.
Now for the scoring bit. Both Sp and Sf are used to evaluate the synthetic pairs. Specifically, you compute the average log-likelihood of the clean target sentence under each model. If Sf (trained on private data) assigns a high likelihood to a sentence, that’s a strong signal: this looks like something real users would actually type.
To discretise this score, a lightweight reweighing parametric model is trained. It takes these likelihood scores and learns to predict how well each synthetic pair is likely to perform: based on real-world A/B test metrics gathered from deployed systems. The model is trained with a regression objective to minimise the gap between predicted and actual performance lift.
Thus, every synthetic sample gets a reweighing score, nudging the data distribution closer to the real world, without ever looking at user data directly. This brings the public web-data dependant synthetic data into the same domain as mobile application text data: real-world, mobile-typed, error-ridden text.
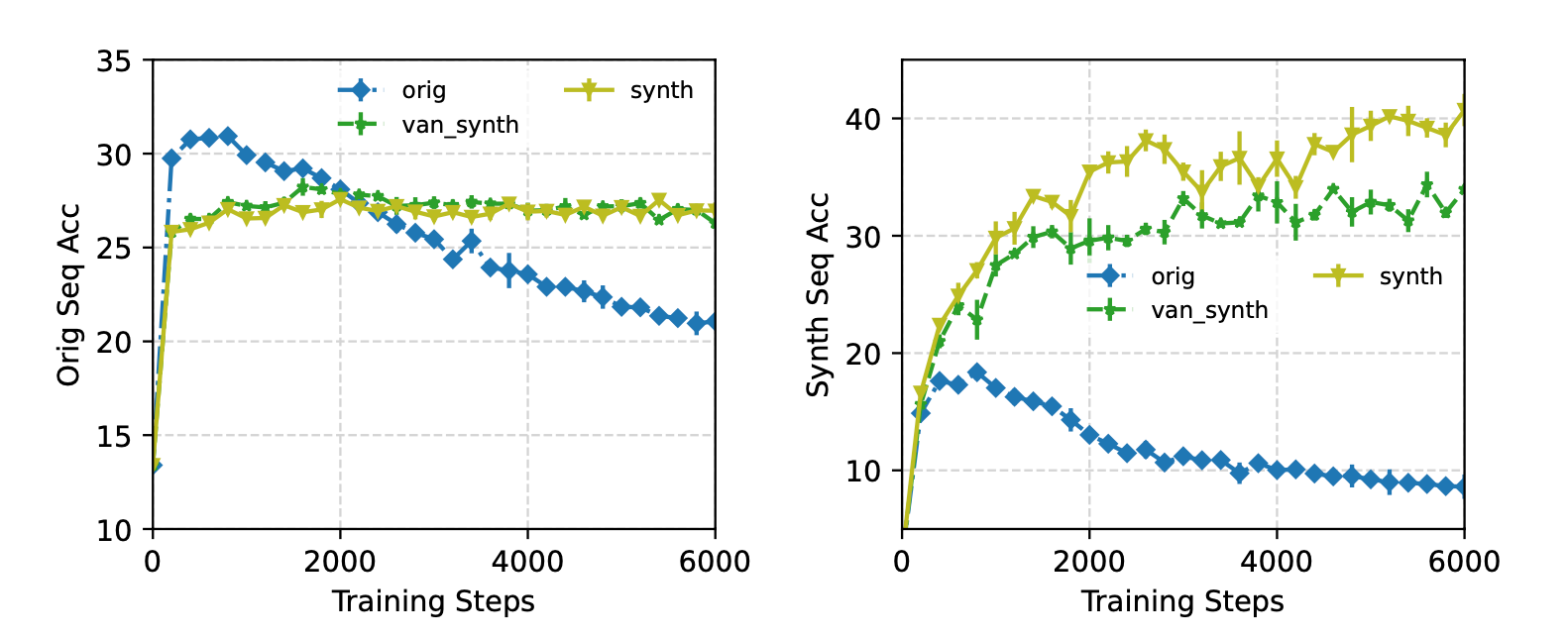
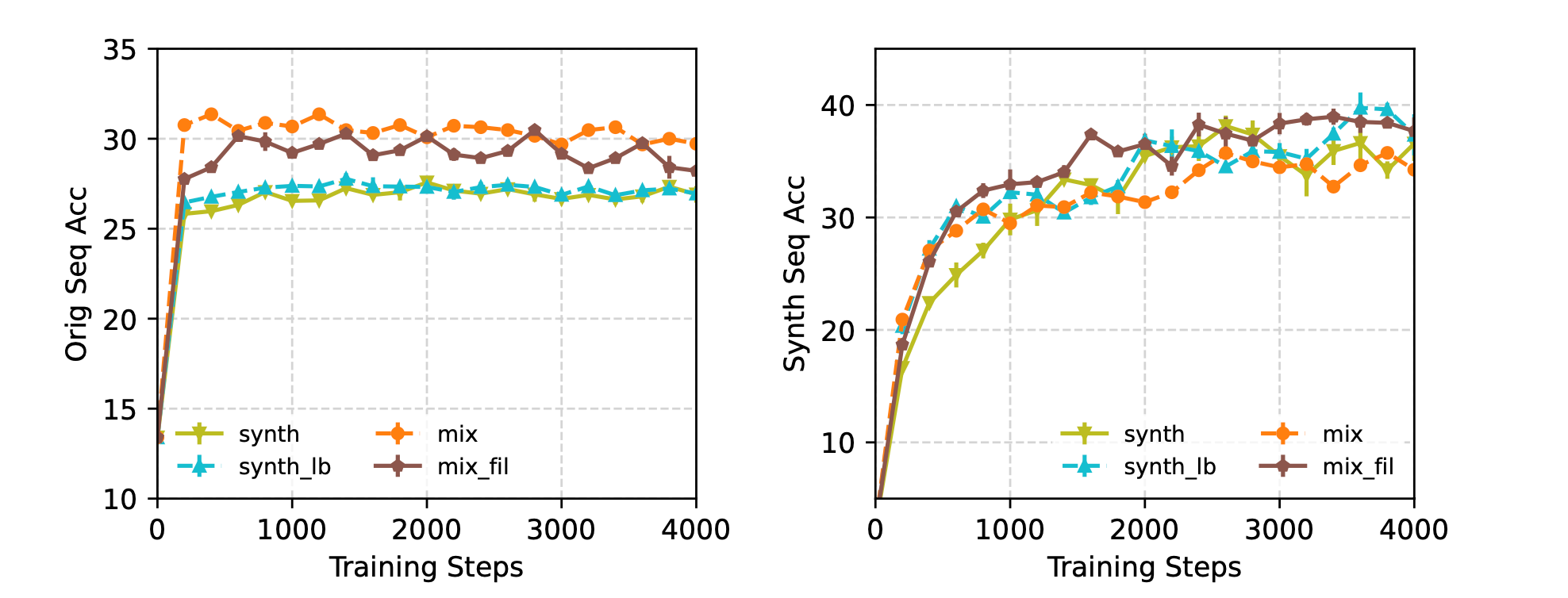
Step-3: Continued Training on Mixed and Reweighted Data
Once the synthdata has been reweighed using the privacy-preserving proxy model, it’s ready to be used in fine-tuning.
But instead of simply mixing all these datasets together into a giant stew and throwing them at the model in one go, the authors use a multi-stage “continue training” strategy that balances scale with domain precision.
Here’s how it works:
- Start with synthetic data: First the Gemini Nano model is LoRA-fine-tuned on the full, reweighed synthetic dataset for one epoch. This gives it a broad understanding of diverse, realistic text errors at scale.
- Then continue training using one of the following strategies:
- ContOrig: Continue training solely on a small “original dataset”. These original EC pairs aren’t user data but are mined from public web sources: grammatical error detection models first flag noisy sentences, and a mobile-style typing simulator introduces realistic typos and corrections. The result is a small but high-quality set of mobile-relevant EC sample pairs.
- ContMix: Continue training on a mixture of this original + full synthetic data
- ContMixFil: Continue training on a mixture of the original + filtered synthetic data (ie: only samples above a certain reweighing threshold).
Why this approach?
Because the synth dataset is much larger than the original, training directly on a mixture can cause the model to lean too much into synthetic patterns. By switching to a second training stage helps shift the model back towards the target mobile domain, especially when using the filtered high-quality synthetic samples in ContMixFil.
This strategy lead to the best offline and live A/B testing results, with ContMixFil achieving:
- Strong performance on both original and synthetic validation data.
- A 2.47% - 7.18% boost in live A/B testing on production metrics like click-through and accept rate.
In short, by not treating all synthetic data equally and by staging training carefully, the authors manage to get the best of both worlds: the scale of synthdata and the nuance of real mobile typing patterns.
Conclusion
This paper nails a tough trade-off: better mobile error correction without bloated models or privacy compromises. The authors pull it off by fine-tuning Gemini Nano using synthetic, centrally generated data (carefully reweighted to reflect real mobile usage).
The core model training is done centrally. The reweighting model is learned via federated + differentially private trained models, and the final LoRA adapter is trained on a mix of synthetic and real-world correction data. Once trained, a single lightweight LoRA module is shipped to all devices and runs directly on top of Gemini Nano right on your phone.
No per-user tuning, no personal data leakage: just a clever use of domain-adaptive filtering and LoRA efficiency to get the best of both worlds: smart, private, on-device language modelling.
Check out the full paper : Synthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications