Your Semantic Cache Has a Grey Zone Problem
Vrinda Kohli
May 05, 2026 · 6 min read

If you're running LLMs in production, you've probably built (or thought about building) a semantic cache. The pitch is simple: embed incoming prompts, find near-duplicates, serve the cached response, skip inference. It works. Except when it doesn't.
A new paper from Apple introduces Krites, a caching policy that quietly fixes one of the most annoying problems in semantic caching, ie. the similarity grey zone, without adding a single millisecond to your serving latency. Let's break it down.
The Setup: Tiered Caching for LLMs
Production LLM deployments typically run a two-tier cache. The static tier is a read-only store of curated, offline-vetted responses mined from historical logs, think gold-standard answers produced by larger models or human review. The dynamic tier is a standard read-write cache populated on the fly as new prompts come in, governed by LRU or TTL eviction.
In front of both sits the standard GPTCache-style policy: embed the incoming prompt, find its nearest neighbor in each tier, and check if cosine similarity clears a fixed threshold. If it does, serve the cached answer. If not, call the backend.
v_q = embed(prompt)
(h_static, s_static) = nearest_neighbor(C_static, v_q)
if s_static >= τ_static:
return answer(h_static) # Static hit — curated, gold answer
(h_dynamic, s_dynamic) = nearest_neighbor(C_dynamic, v_q)
if s_dynamic >= τ_dynamic:
return answer(h_dynamic) # Dynamic hit
a_gen = backend(prompt) # Full inference — expensive
insert(C_dynamic, prompt, a_gen)
return a_gen
This is clean, fast, and well-understood. The problem is the threshold τ.
The Grey Zone Problem
Here's the tension: you want your static threshold high enough to avoid serving wrong answers, but low enough to actually get cache hits. The vCache benchmark showed something uncomfortable: the similarity distributions for correct and incorrect cache hits overlap heavily. There's a range of similarity scores where embedding geometry alone simply can't tell you whether two prompts are interchangeable.
Consider these pairs:
| Incoming prompt | Cached neighbor |
|---|---|
| "What's the word on my dog having honey?" | "Can my dog have honey?" |
| "Was anyone successful in the lottery last night?" | "Anybody win the lottery last night?" |
These are clearly the same intent. A human would serve the same answer. But they can fall below a conservative cosine similarity threshold, which means the system throws away a perfectly good curated answer and calls the backend instead.
The grey zone is the interval [σ_min, τ_static) — prompts close enough to be suspicious, but not close enough to clear the bar. Every prompt in this range represents a curated static answer that might be correct but is left on the table.
You're stuck: lower the threshold and you get false hits. Keep it high and you're paying for inference you don't need.
Krites: Off-Path Verification
Krites' insight is that you don't need to resolve the grey zone during the request. You can resolve it after.
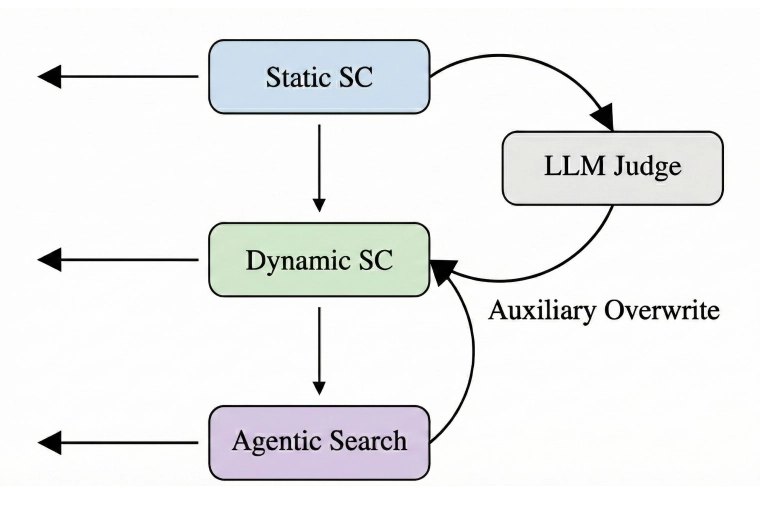
The architecture has three moving parts:
1. The serving path is untouched
On every request, Krites runs exactly the same threshold policy as the baseline. Same thresholds, same decisions, same latency. The user never waits for anything extra.
2. Grey-zone detection triggers a background job
When a prompt misses the static tier but its nearest static neighbor has similarity in [σ_min, τ_static), Krites enqueues an async verification task. The request is already served (from the dynamic cache or the backend) and this is purely background work.
3. An LLM judge decides, then promotes
The background worker sends the prompt pair (and the cached answer) to an LLM judge with a strict rubric: check intent alignment, entity consistency, freshness requirements. Binary output: APPROVE or REJECT. If approved, the curated static answer is upserted into the dynamic cache under the new prompt's key.
Here's the flow:
Request arrives
│
├── Static cache lookup
│ │
│ ├── HIT (s >= τ_static) → serve curated answer [done]
│ │
│ └── MISS
│ │
│ ├── Dynamic cache / backend → serve response to user [done]
│ │
│ └── If s ∈ [σ_min, τ_static):
│ │
│ └── ASYNC: enqueue VerifyAndPromote
│ │
│ ├── LLM judge → REJECT → discard
│ │
│ └── LLM judge → APPROVE
│ │
│ └── Upsert static answer into
│ dynamic cache under new key
This is the key idea: the dynamic cache becomes a mutable pointer layer over the static cache. The next time the same prompt (or a nearby paraphrase) arrives, it hits the dynamic tier and gets the curated static answer without anyone waiting for a judge.
Why This Matters in Production
The value here isn't just hit rate. It's the quality of what gets served. In enterprise search, medical assistants, or any domain where safety review matters, there's a meaningful difference between "a response the model generated on the fly" and "a curated, offline-vetted gold answer." Krites shifts the composition of cache hits toward the latter.
The paper evaluates on two benchmarks from the vCache suite, using an oracle judge derived from ground-truth equivalence classes to keep the evaluation policy-centric and judge-agnostic:
| Dataset | Baseline | Krites | Relative Gain |
|---|---|---|---|
| SemCacheLMArena (conversational) | 8.2% | 19.4% | +136.5% |
| SemCacheSearchQueries (search) | 2.2% | 8.6% | +290.3% |
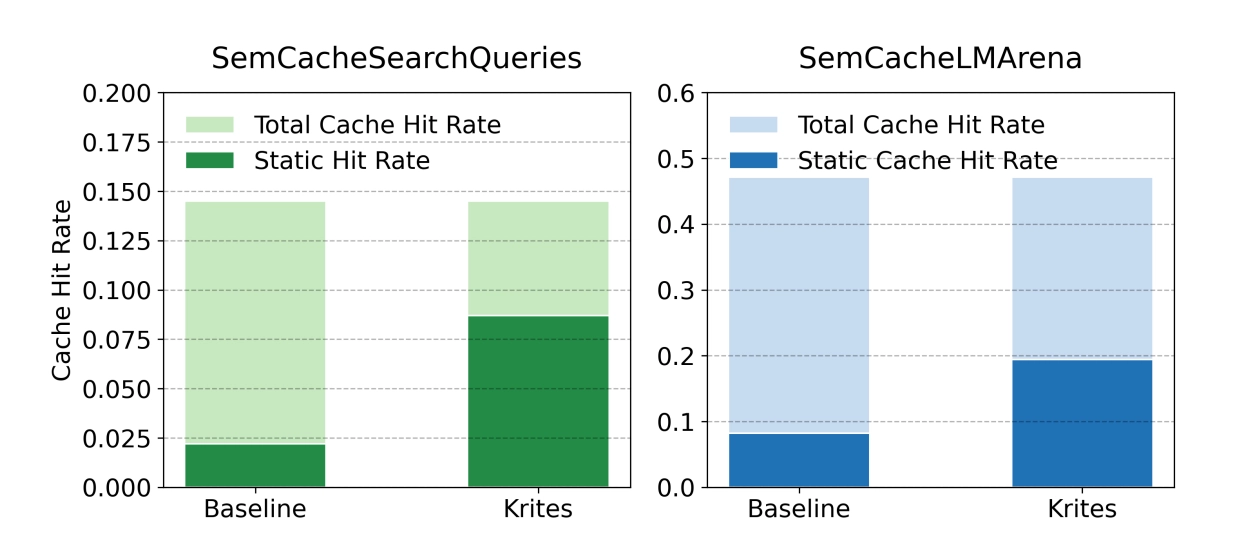
That "static-origin served fraction" metric is the percentage of requests getting curated answers (either direct static hits or promoted-to-dynamic hits). Krites nearly quadruples it on search workloads. And the total cache hit rate stays the same, shifting the composition towards higher-quality responses.
Because Krites leaves the on-path decision rule unchanged, the critical-path latency and error behavior of the baseline are preserved for the request that triggers verification.
The Judge: How Realistic Is It?
A fair question. The main results use an oracle judge (ground-truth labels), which isolates the policy evaluation from judge imperfections. But to sanity-check feasibility, the authors ran Claude Opus 4.5 as a strict binary judge on 100 human-audited pairs drawn from the grey zone. Result: 99 out of 100 agreed with human labels.
The error analysis is also worth noting. Since verification is off-path, a judge mistake never affects the request that triggered it. It can only affect future requests that hit the promoted entry. If the judge has a false-approve rate of ε and promoted traffic is p_prom, the incremental error contribution is bounded by ε · p_prom, a small product of two small numbers.
False rejects just reduce how many promotions happen (you leave performance on the table). False approves can introduce errors on promoted entries, but only for subsequent hits, never for the triggering request.
Cost Tradeoffs
Krites trades background compute for higher static-origin coverage. The judge invocation rate is roughly λ · p_grey (request rate × fraction landing in the grey zone), before deduplication and rate limiting.
Whether a single judge call pays for itself depends on the approval rate and how many times the promoted entry gets reused before eviction. In workloads with recurring paraphrases (which is... most conversational and search workloads), the ROI is straightforward: one judge call can save dozens of future backend invocations.
The σ_min knob lets you control the tradeoff directly. Raise it to reduce judge volume (but recover fewer static hits). Lower it to expand coverage (but pay more in judge compute). The paper uses σ_min = 0 in their experiments — the most aggressive setting.
Promoted entries also follow standard dynamic-tier eviction (LRU/TTL). If a promoted pointer isn't reused, it gets evicted naturally. If the query shows up again later, it re-enters the grey zone and gets re-judged. No special pinning, no capacity bloat.
What Makes This Interesting
It's additive and non-invasive: You don't rip out your existing cache or retune your thresholds. Krites bolts onto whatever GPTCache-style policy you already run. The serving path is literally unchanged as you're just adding a background worker that occasionally enriches the dynamic tier.
The "dynamic cache as pointer layer" framing is elegant: Instead of trying to make the static cache bigger (which requires offline curation pipelines), you make the dynamic cache point to static answers for new keys. The static tier's quality guarantee propagates through the dynamic tier without modifying the static tier at all.
It's a systems paper, not a model paper: There's no new embedding model, no new fine-tuning recipe. It's a caching policy. The architecture is simple enough to implement in a week, and the moving parts (worker queue, deduplication, idempotent upserts) are standard distributed systems primitives.
It's complementary to other improvements. Better embeddings (via fine-tuning) shrink the grey zone. Learned thresholds (like vCache proposes) improve the hit-error frontier. Krites sits on top of both. Whatever grey zone remains after those optimizations, Krites can work to recover it.
Wrapping Up
Semantic caching is one of those areas where the gap between "works in a demo" and "works in production" is enormous. The grey zone is a real obstacle, and most teams either eat the false hits or eat the cost. Krites offers a third option: eat neither, at the cost of some background compute that doesn't touch your serving latency.
For any team running a tiered LLM cache with curated static answers, this seems like an obvious win to evaluate.
Paper: Asynchronous Verified Semantic Caching for Tiered LLM Architectures — Singh et al., Apple, 2026