Code Mode and the Architecture of Token-Efficient MCP Agents
Vrinda Kohli
May 16, 2026 · 8 min read

The Context Window Problem
If you've built an agent that connects to more than a handful of MCP servers, you've already run into this. Every tool definition from every connected server gets loaded into the model's context window on every request. Five servers with 30 tools each means 150 tool definitions sitting in context before the model reads a single word of your prompt.
This is more than a theoretical concern. Anthropic's engineering team documented a five-server setup where tool definitions alone consumed roughly 55,000 tokens. Scale that to a production environment with a dozen servers, and you're burning through six-figure token counts just to describe what the agent could do, before it does anything.
The second cost is less obvious but equally painful: intermediate results. In a standard MCP loop, every tool call's output flows back through the model so it can decide what to do next. If your agent is chaining four or five tools together (look up a customer, fetch their order history, apply a discount, send a confirmation) every intermediate payload passes through the context window. The model is effectively acting as a router, copying data from one function call to the next. You're paying inference-tier prices for what is essentially a pipe operation.
What Code Mode Actually Is
The core idea behind Code Mode is straightforward: instead of giving the model a massive list of tool definitions and having it call them one by one through the standard tool-use protocol, you let the model write code that calls those tools.
The model gets a small set of meta-tools, typically something like search (to discover what's available) and execute (to run a script against the tools it found). Tool definitions live on the server side, not in the context window. The model reads only what it needs, writes a short program to orchestrate the calls, and a sandboxed runtime executes it.
This flips the economics of tool use. Context cost becomes proportional to what the agent actually uses, not to what exists. And intermediate results stay inside the execution environment. They never touch the context window unless the agent explicitly logs them back.
The idea has converged independently across multiple organizations. Anthropic's engineering team published a detailed exploration of code execution with MCP in late 2025, framing it around filesystem-based tool discovery where each MCP tool becomes a TypeScript file the agent can explore on demand. They reported reducing token usage from 150,000 to 2,000 in a Google Drive-to-Salesforce workflow, which is a 98.7% reduction.
Cloudflare arrived at the same pattern from a different direction. Their Cloudflare API surface spans over 2,500 endpoints. Expressed as native MCP tools with minimal schemas, that's still around 244,000 tokens. With Code Mode, they collapsed it to roughly 1,000 tokens, two tools (search and execute) backed by a V8 isolate sandbox. The model writes JavaScript to explore the API spec and make calls, and the isolate ensures the code can't do anything beyond what the bindings expose.
The alignment between these approaches isn't coincidental. LLMs are trained on vastly more code than they are on tool-call JSON schemas. Asking a model to write a Python or TypeScript function that chains three API calls together is playing to its strengths. Asking it to emit a sequence of structured tool-call objects with correct argument threading across turns is fighting the training distribution.
How It Works in Practice
A typical Code Mode implementation provides the agent with three to four meta-tools:
Discovery: a way to list what servers and tools are available, usually returning lightweight summaries rather than full schemas. Think of it as ls for your tool catalog.
Inspection: a way to read the full signature or documentation of a specific tool before using it. The agent pulls this on demand rather than having everything preloaded.
Documentation (optional): detailed docs or usage examples for a tool, fetched only when the agent needs more context to use it correctly.
Execution: a sandboxed runtime that accepts a script, resolves tool calls within it, and returns the output.
Here's what a multi-step workflow looks like under each model:
Standard MCP: The model receives all 150 tool definitions. It calls lookup_customer, waits for the result to flow back through context, calls get_order_history, waits again, calls apply_discount, waits again, calls send_confirmation. Four round trips, each carrying the full tool list and the growing context of intermediate results.
Code Mode: The model calls listTools to see what's available (~200 tokens). It reads the signatures for the four tools it needs (~400 tokens). Then it writes a single script:
customer = lookup_customer(email="alice@example.com")
orders = get_order_history(customer_id=customer["id"])
latest = max(orders, key=lambda o: o["date"])
apply_discount(order_id=latest["id"], percent=10)
send_confirmation(customer_id=customer["id"], order_id=latest["id"])
One execution call. No intermediate results in the context window. The model gets back a single final output.
The Security Model
Letting an LLM write and execute arbitrary code sounds like a recipe for disaster. The key constraint is sandboxing.
Cloudflare runs Code Mode scripts inside V8 isolates. This is the same lightweight runtime that powers Workers. Each execution spins up a fresh isolate in milliseconds, with no filesystem access, no network access beyond the explicitly bound MCP servers, and no visibility into API keys (the bindings handle authentication on the host side).
Starlark, the language Google designed for Bazel build configurations, is another popular sandbox choice. It's deliberately limited: no imports, no I/O, no threading. Just basic Python-like logic and whatever functions you explicitly expose. This makes it fast, deterministic, and easy to reason about from a security perspective.
The sandboxing also solves a subtle problem with key leakage. In standard tool calling, the model never sees credentials directly. But when it writes code, a naive implementation might expose API keys as variables. Binding-based approaches avoid this entirely: the model calls mcp_server.some_tool(args), and the binding handles authentication transparently on the host side. The generated code literally cannot contain credentials because it never has access to them.
Where Code Mode Breaks Down
Code Mode isn't universally better. A few scenarios where standard tool calling still wins:
- Small tool sets. If you have three or four tools total and they rarely chain, the overhead of discovery-inspect-execute adds latency for no meaningful token savings.
- Highly interactive workflows. If the agent needs to make decisions based on each intermediate result and not just pass data forward but change strategy, code execution collapses the decision points. The model has to anticipate branches up front rather than reacting turn by turn.
- Debugging and observability. A sequence of individual tool calls is easier to trace than a script. You can see exactly what the model decided at each step. With code execution, you get the script and the final output, but the intermediate reasoning is baked into code the model wrote, which may or may not be easy to follow.
- Model capability variance. Code Mode depends on the model being a competent programmer. Frontier models handle this well. Smaller or specialized models might struggle with correct function signatures, error handling, or data transformation logic.
Bifrost 🤝 Code Mode
Bifrost ships Code Mode as a native feature of its MCP Gateway. The implementation follows the same conceptual pattern but adds a few things specific to running this in a governed production environment.
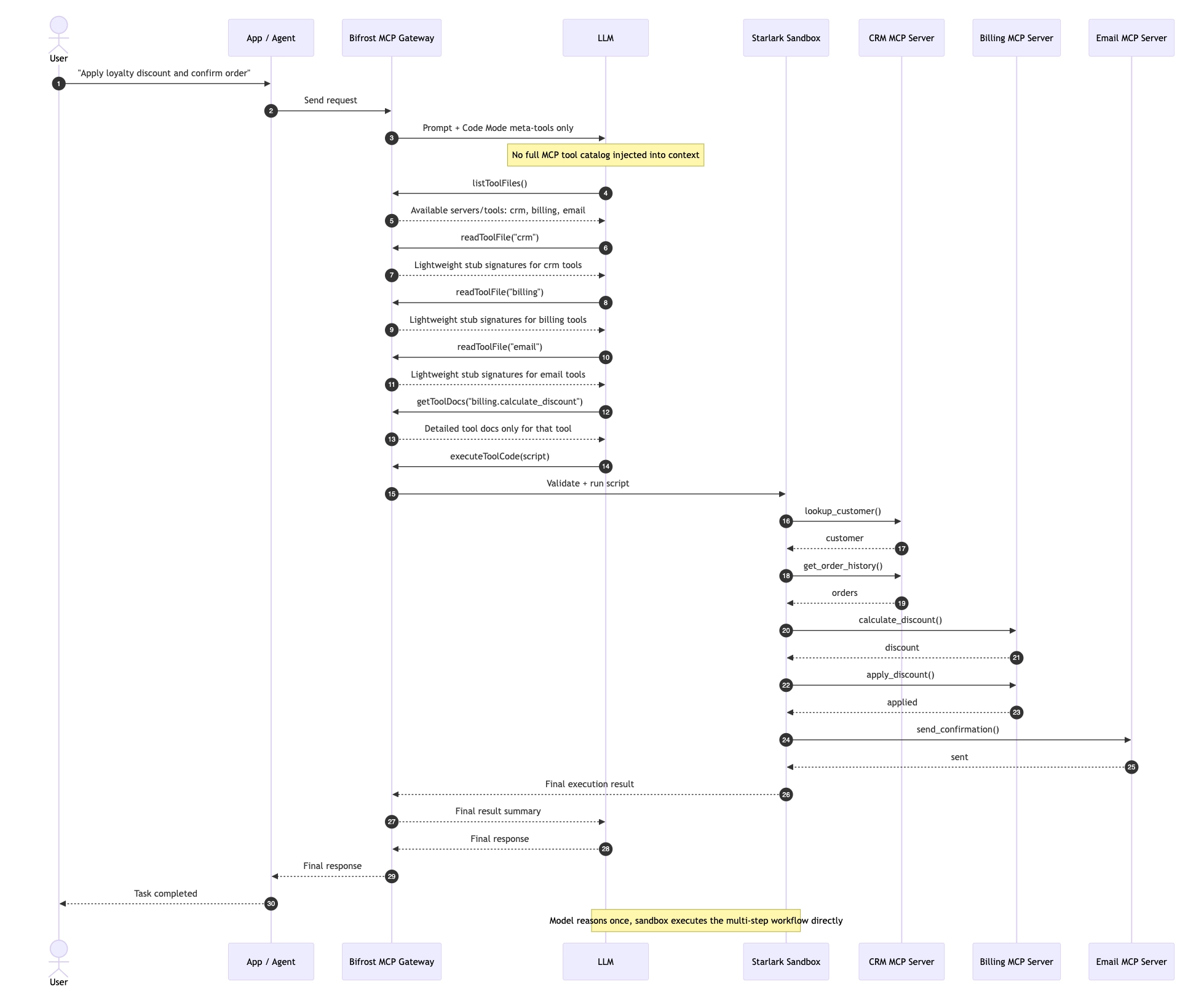
The Meta-Tool Set
Bifrost exposes four meta-tools to the model:
| Meta-tool | Purpose |
|---|---|
listToolFiles | Discover available servers and tools |
readToolFile | Load Python function signatures for a specific server or tool |
getToolDocs | Fetch detailed documentation for a tool on demand |
executeToolCode | Run the orchestration script in a sandboxed Starlark interpreter |
The choice of Python stubs (rather than TypeScript) is deliberate. LLMs have been trained on substantially more Python than JavaScript, which tends to produce more reliable generated code. The addition of getToolDocs as a separate meta-tool (rather than bundling docs into the stub files) keeps the initial discovery step lightweight while still giving the model access to detailed usage information when it needs it.
Bifrost supports both server-level and tool-level bindings. You can expose one stub per server for compact discovery, or one stub per tool for more granular lookup and execution. This flexibility matters when some servers have a handful of well-known tools and others have dozens of specialized endpoints.
Sandboxed Execution
The execution environment is Starlark, intentionally constrained with no imports, no file I/O, and no network access beyond the bound tool calls. This makes execution fast, deterministic, and safe for autonomous agent loops.
Integration With Access Control
This is where Bifrost's implementation diverges from standalone Code Mode libraries. Code Mode sits behind the same governance layer as the rest of the gateway:
Virtual keys scope which tools a given consumer can access, at the tool level rather than the server level. A key provisioned for a customer-facing agent can reach crm_lookup_customer but not crm_delete_customer, even though both live on the same MCP server. In Code Mode, this means the model's discovery step only ever surfaces tools the key is authorized to see.
MCP Tool Groups let you define named collections of tools and attach them to keys, teams, or users. Bifrost resolves the correct tool set at request time in memory, meaning no database queries. If a request matches multiple groups, the allowed tools are merged and deduplicated. The model only sees what it's supposed to see.
Auto-execute controls govern which tools can run without manual approval. In Code Mode, listToolFiles, readToolFile, and getToolDocs are always auto-executable since they're read-only. executeToolCode only runs autonomously when every tool called within the generated script is on the auto-execute allowlist. This means you can let agents loop freely through discovery while still gating destructive operations behind human approval.
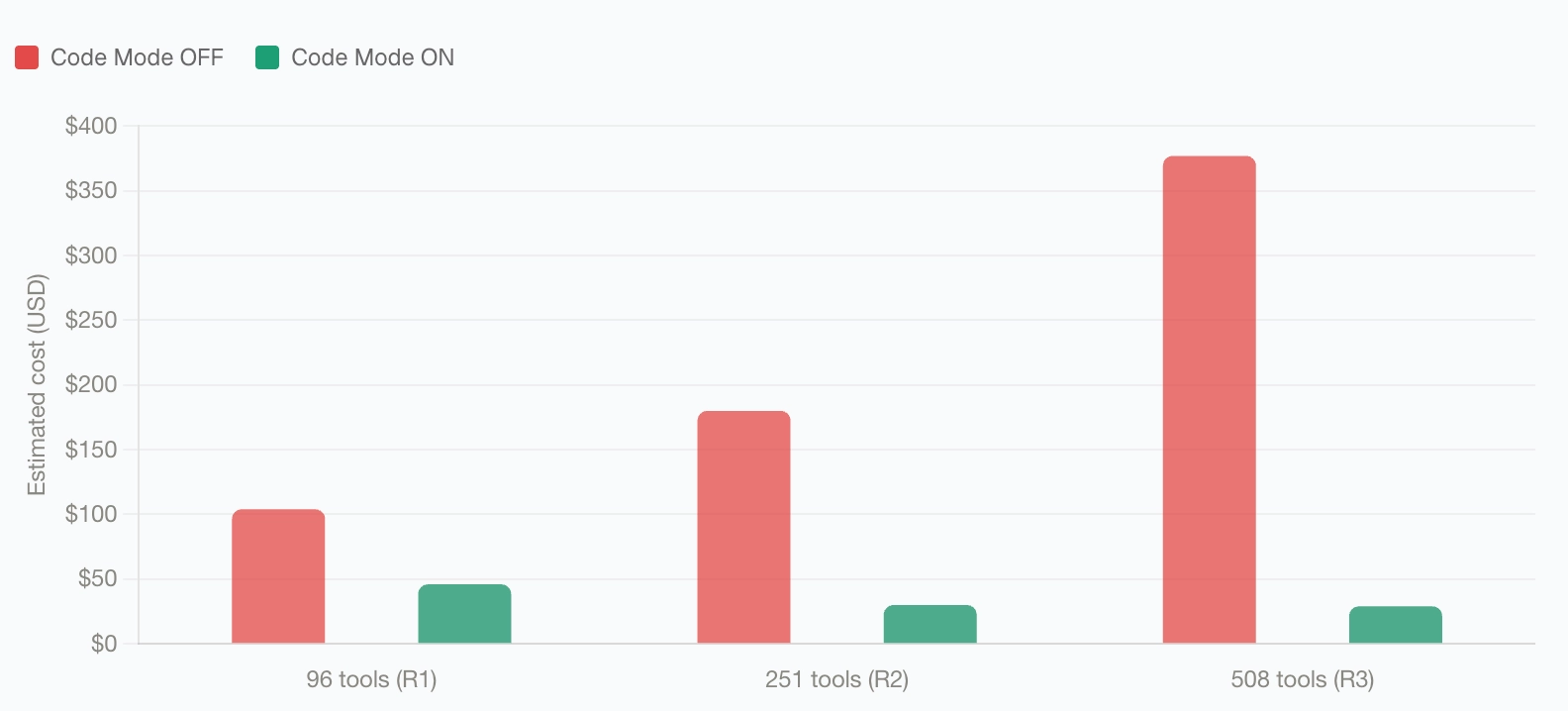
The Cost Numbers
Bifrost published benchmark results across three rounds of controlled testing, scaling tool count between rounds:
- 96 tools (6 servers): Code Mode reduced input tokens by 58% and estimated cost by 56%.
- 251 tools (11 servers): Token reduction hit 84.5%, cost dropped 83%.
- 508 tools (16 servers): Token reduction reached 92.8%, cost savings hit 92%.
The key insight from these numbers: savings compound as you add MCP servers. Standard MCP loads every tool definition on every request, so cost grows linearly with tool count. Code Mode's cost is bounded by what the model actually reads, not by what exists. Pass rate held at 100% across all rounds, confirming that accuracy isn't traded away to get the savings.
Audit and Cost Visibility
Every tool execution under Code Mode is a first-class log entry: tool name, originating server, arguments, result, latency, the virtual key that triggered it, and the parent LLM request. Per-tool cost tracking lets you assign dollar costs to tools that call paid external APIs (search, enrichment, code execution services), so you get a complete picture of what each agent run actually cost, not just the model's token charges.
Where This Is Heading
Code Mode is still early, but the trajectory is clear. Anthropic recently shipped two related features in their API: Programmatic Tool Calling (letting Claude orchestrate tools through code rather than individual round-trips) and Tool Search Tool (deferred tool loading with on-demand discovery). Internal testing showed accuracy improvements from 49% to 74% on Opus 4 and 79.5% to 88.1% on Opus 4.5 when using tool search with large tool libraries.
Cloudflare is building Code Mode into their MCP Server Portals, so you can front multiple MCP servers with a single gateway that provides progressive tool discovery and sandboxed execution, regardless of how many services sit behind it.
The pattern that's emerging is consistent: treat your MCP tools as a discoverable catalog, not a static context payload. Let agents explore what they need, write code to orchestrate it, and execute in a sandbox. The infrastructure layer: whether it's Bifrost, Cloudflare Workers, or a custom runtime, handles governance, sandboxing, and observability.
If you're running more than a few MCP servers in production, the question isn't whether to adopt Code Mode. It's how soon your token bill will force you to.
Bifrost’s Code Mode benchmarks are available on GitHub.