Top 7 Performance Bottlenecks in LLM Applications and How to Overcome Them

Large Language Models have revolutionized how enterprises build AI-powered applications, from customer support chatbots to complex data analysis agents. However, as organizations scale their LLM deployments from proof-of-concept to production, they encounter critical performance bottlenecks that impact user experience, inflate costs, and limit scalability.
Research surveys examining 25 inference engines and system-level innovations reveal that reducing computational costs while maintaining performance remains a core focus for LLM deployment. Understanding and addressing these bottlenecks is essential for building reliable AI agents that deliver value at scale.
This comprehensive guide explores the seven most critical performance bottlenecks facing LLM applications today and provides actionable strategies, including how Maxim AI's evaluation and observability platform helps overcome each challenge.
1. High Latency and Slow Response Times
The Problem
Latency is one of the most frustrating issues in LLM applications. Low latency is crucial for delivering smooth, real-time user experiences, especially in applications like chatbots, coding assistants, customer support, and translation tools, where inference performance directly affects user satisfaction. High latency leads to frustrated users, reduced engagement, and abandoned interactions.
LLM latency comprises two critical metrics:
- Time-to-First-Token (TTFT): The delay before the model starts generating a response
- Inter-Token Latency: The time between successive tokens during generation
During the decode phase, LLMs generate output tokens autoregressively one at a time, with each sequential output token needing to know all previous iterations' output states. The speed at which data is transferred to the GPU from memory dominates the latency, making this a memory-bound operation.
Common Causes
- Large model sizes requiring extensive computational resources
- Inefficient attention mechanisms processing long contexts
- Suboptimal hardware utilization
- Network latency in distributed systems
- System bottlenecks due to large parameter sizes and real-time constraints
Solutions
Technical Optimizations:
- Implement quantization to reduce model precision (FP32 to INT8 or INT4)
- Use Key-Value caching to eliminate redundant work by storing and reusing past attention scores
- Deploy efficient attention mechanisms like Flash Attention
- Enable streaming responses to improve perceived performance
How Maxim AI Helps:
Maxim AI's Observability platform provides real-time latency monitoring across your entire LLM stack, tracking:
- Time-to-first-token distributions
- End-to-end response times
- Token generation rates
- Performance degradation patterns
With Agent Simulation Evaluation, you can benchmark different model configurations, quantization strategies, and infrastructure setups before deploying to production, identifying the optimal balance between speed and quality for your specific use case.
2. Context Window Management and Memory Constraints
The Problem
The evolution of LLMs shows dramatic improvements in context length capability: from GPT-3.5 Turbo's initial 4,096-token context window to the latest models supporting up to 2 million token context windows. However, managing these expanded context windows efficiently remains challenging.
Memory constraints create a critical bottleneck as context grows. Even cutting-edge hardware like the H100 GPU with 80 GB of VRAM has its limits, and cache compression techniques can achieve up to a 2.9× speedup while nearly quadrupling memory capacity.
Common Causes
- Exponential growth of Key-Value cache with context length
- Inefficient context utilization sending unnecessary information
- Memory bandwidth limitations on GPU hardware
- Poor context pruning strategies
Solutions
Context Optimization Strategies:
- Implement intelligent context pruning to remove redundant information
- Use sliding window attention for long sequences
- Apply semantic chunking to retain only relevant context
- Employ KV cache compression and quantization to reduce memory footprint while allowing for longer input sequences
How Maxim AI Helps:
Maxim AI's Experimentation feature enables you to:
- A/B test different context management strategies
- Measure the impact of context length on accuracy and latency
- Identify optimal context window sizes for your use cases
- Track memory utilization patterns across model variants
The platform's detailed tracing capabilities help you visualize exactly how your agents use context, revealing opportunities to optimize without sacrificing performance.
3. Inefficient Prompt Engineering and Token Usage
The Problem
Every token processed by an LLM incurs computational and financial costs. Many LLM providers employ a token-based pricing model, where you're charged based on the number of tokens processed. Optimizing token usage can yield substantial cost savings, particularly for applications with high-volume or real-time requirements.
Poor prompt engineering doesn't just waste tokens. It degrades output quality, increases latency, and compounds costs at scale. In many cases, prompts that work haven't been optimized, which leaves significant potential on the table for improving response quality while reducing costs.
Common Causes
- Verbose, unfocused prompts with unnecessary context
- Lack of structured formatting (XML tags, clear instructions)
- Repetitive information across multiple prompts
- Missing few-shot examples that could improve accuracy
- Inefficient prompt templates that don't scale
Solutions
Prompt Optimization Techniques:
- Utilize XML structuring to delineate instructions, context, and examples clearly
- Apply prompt compression to remove redundant tokens
- Implement modular prompt engineering for complex tasks
- Break down complex tasks using modular prompt engineering and assign them to appropriate models or tools
- Position critical information strategically (question at end for better caching)
How Maxim AI Helps:
Maxim AI's Prompt Management system provides:
- Version Control: Track all prompt iterations and their performance metrics
- A/B Testing: Compare prompt variants side-by-side with statistical significance testing
- Token Analytics: Monitor token usage per prompt and identify optimization opportunities
- Template Library: Build reusable, optimized prompt templates with variable injection
The platform's evaluation framework automatically tests prompt variants against your custom test cases, measuring accuracy, cost, and latency to help you find the sweet spot between performance and efficiency.
4. Poor Caching Strategies
The Problem
Response caching typically provides the most immediate cost savings with the least effort, offering a 15-30% cost reduction almost instantly for applications with repetitive queries. Yet many LLM applications fail to implement effective caching, resulting in redundant API calls and unnecessary expenses.
Without intelligent caching, your application processes identical or semantically similar queries multiple times, wasting compute resources and increasing response times.
Common Causes
- No semantic similarity matching for near-duplicate queries
- Cache invalidation strategies that are too aggressive or too conservative
- Lack of cache warming for high-frequency queries
- Missing cache layer between application and LLM API
- No prompt caching for repeated system instructions
Solutions
Caching Implementation Strategies:
Create multi-tier caching architecture (see implementation example):
- Exact Match Cache: Hash-based lookup for identical queries
- Semantic Cache: Embedding-based similarity matching for related queries
- Prompt Caching: Cache repeated system instructions and context
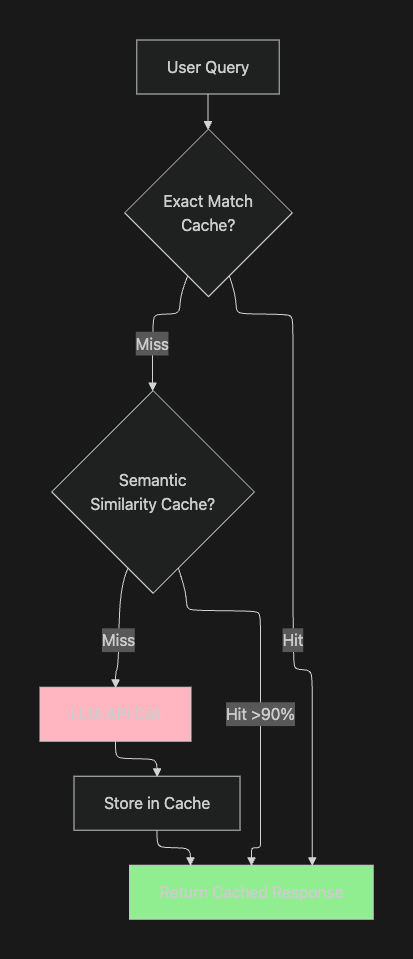
How Maxim AI Helps:
Maxim AI's observability features track cache performance in real-time:
- Cache Hit Rate Monitoring: Measure effectiveness of your caching strategy
- Latency Comparison: Compare cached vs. non-cached response times
- Cost Analysis: Calculate actual savings from cache hits
- Pattern Recognition: Identify high-frequency queries that should be cached
Combined with Bifrost LLM Gateway, you can implement intelligent routing that checks multiple cache layers before hitting the LLM API, maximizing cache utilization while maintaining response quality.
5. High Inference Costs
The Problem
As LLM applications scale, inference costs can quickly spiral out of control. Most developers see a 30-50% reduction in LLM costs by implementing prompt optimization and caching alone, with comprehensive implementation of all strategies reducing costs by up to 90% in specific use cases.
The challenge isn't just the per-token pricing. It's optimizing the entire inference pipeline to minimize waste while maintaining quality standards.
Common Causes
- Using expensive flagship models for simple tasks
- Lack of model routing based on task complexity
- No cost monitoring or budget alerts
- Inefficient batch processing strategies
- Missing fallback to cheaper models when appropriate
Cost Breakdown Table
| Cost Component | Typical % of Total | Optimization Potential |
|---|---|---|
| Input Tokens | 20-30% | High (prompt compression, caching) |
| Output Tokens | 40-50% | Medium (response length control) |
| Model Selection | 30-40% | High (task-appropriate routing) |
| API Overhead | 5-10% | Low (batching, connection pooling) |
Solutions
Cost Optimization Strategies:
- Intelligent Model Routing
- Select smaller, less expensive models for simpler tasks to avoid unnecessary expenses, optimizing the cost-to-performance ratio
- Route simple queries to smaller models (e.g., GPT-4o Mini, Claude Haiku)
- Reserve flagship models for complex reasoning tasks
- Token Optimization
- Write concise prompts, avoid unnecessary repetitions, and structure instructions efficiently
- Implement aggressive response length limits
- Use structured outputs to minimize tokens
- Batch Processing
- Group similar requests for efficient processing
- Balance latency requirements with throughput optimization
How Maxim AI Helps:
Maxim AI provides comprehensive cost management:
- Real-Time Cost Tracking: Monitor spending per model, prompt, and user session
- Budget Alerts: Set thresholds and receive notifications before exceeding budgets
- Cost Attribution: Break down costs by feature, user, or workflow
- Model Comparison: Evaluate cost-quality tradeoffs across model variants
The Bifrost LLM Gateway enables intelligent model routing, automatically selecting the most cost-effective model that meets your quality requirements. This ensures you're never overpaying for simple tasks while maintaining high accuracy for complex queries.
6. Agent Orchestration and Tool Calling Overhead
The Problem
As AI applications evolve beyond simple chat interfaces into autonomous agents that can use tools, call APIs, and coordinate multiple steps, orchestration overhead becomes a significant bottleneck. Performance differences between frameworks stem from tool deliberation and context synthesis, not agent handoffs. Tool execution patterns and context management matter most for orchestration performance.
Many AI systems are slower than they need to be because they handle tasks one after another. The agent might wait to finish retrieving memory before it even starts calling an external API, adding delay at every stage.
Common Causes
- Sequential execution when parallel processing is possible
- Agent-to-Tool Gap: Excessive deliberation time before tool invocation
- Context aggregation inefficiencies where complete, unmodified output of each previous task is passed directly into subsequent contexts
- Blocking operations in the orchestration layer
- Inefficient message passing between agents
- Overlooking latency impacts of multiple-hop communication
Orchestration Pattern Comparison
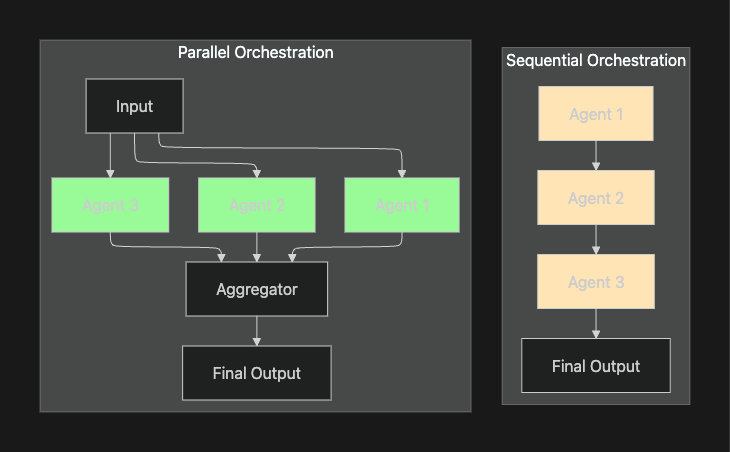
Solutions
Optimization Strategies:
- Async-First Architecture
- Allow the system to start multiple tasks at the same time by implementing asynchronous operations
- Use non-blocking I/O for tool calls
- Implement parallel execution where possible
- Smart Context Management
- Summarize agent outputs before passing to next stage
- Implement context compression for multi-agent workflows
- Track performance and resource usage metrics for each agent to establish baselines and find bottlenecks
- Specialized Orchestration Frameworks
- Use production-ready frameworks designed for performance
- Implement proper error handling and retry logic
- Monitor agent-to-agent communication latency
How Maxim AI Helps:
Maxim AI's Agent Simulation platform is specifically designed to address orchestration challenges:
- Workflow Visualization: See exactly how your agents interact, identify bottlenecks, and optimize execution paths
- Tool Call Monitoring: Track latency for each tool invocation and identify slow dependencies
- Parallel Execution Testing: Simulate concurrent agent execution to validate performance improvements
- Context Flow Analysis: Understand how information flows between agents and identify redundant data transfer
The Observability dashboard provides real-time insights into agent behavior, helping you:
- Measure agent-to-tool gaps
- Track end-to-end workflow latency
- Identify which tools are performance bottlenecks
- Optimize coordination patterns based on actual execution data
7. Rate Limiting and Throughput Bottlenecks
The Problem
Even with optimized prompts, efficient caching, and smart orchestration, your application can hit hard limits imposed by LLM API rate limits. Throughput optimizations via quantization or MoE architectures are emerging trends for performance-constrained applications.
Rate limiting becomes especially problematic during:
- Traffic spikes or viral growth
- Batch processing operations
- Multi-agent systems making concurrent calls
- Development and testing phases with high request volumes
Common Causes
- Insufficient request rate planning for production load
- No queue management or request throttling
- Single API provider dependency
- Lack of request prioritization
- Missing fallback strategies for rate limit errors
- Fluctuating demand throughout the day without proper capacity planning
Solutions
Throughput Optimization Strategies:
- Rate Limit Management
- Use 95% of expected peak requests per second as a reference point to balance underutilization during valleys and capacity constraints during peaks
- Implement exponential backoff for retries
- Queue requests with priority levels
- Multi-Provider Strategy
- Distribute load across multiple LLM providers
- Implement automatic failover when hitting rate limits
- Maintain provider-specific request pools
- Batch Processing Optimization
- Group requests dynamically to maximize throughput through continuous batching
- Balance batch size with latency requirements
- Implement request coalescing for similar queries
- Self-Hosting Consideration
- The self-hosting versus API decision emerges as a key inflection point, with companies demonstrating that self-hosting becomes advantageous at high query volumes and when privacy concerns grow
How Maxim AI Helps:
Maxim AI's Bifrost LLM Gateway provides intelligent request routing and rate limit management:
- Multi-Provider Support: Route requests across OpenAI, Anthropic, Google, and custom endpoints
- Automatic Failover: Seamlessly switch providers when rate limits are hit
- Request Queuing: Intelligent queue management with priority levels
- Load Balancing: Distribute requests optimally across available providers
- Rate Limit Monitoring: Track usage against provider limits in real-time
The Observability platform helps you plan capacity by:
- Analyzing request patterns and peak usage times
- Forecasting rate limit breaches before they occur
- Identifying which features or users consume the most tokens
- Providing actionable insights for capacity planning
Building Reliable AI Agents: A Holistic Approach
Overcoming these performance bottlenecks requires a comprehensive strategy that addresses optimization at multiple layers:
1. Measurement First
You can't optimize what you don't measure. Implement end-to-end observability covering:
- Latency metrics (TTFT, end-to-end, per-stage)
- Cost tracking (per request, per model, per feature)
- Quality metrics (accuracy, hallucination rates, user satisfaction)
- Resource utilization (token usage, cache hit rates, API limits)
2. Continuous Experimentation
Performance optimization is iterative. Use systematic experimentation to:
- Test prompt variants against production traffic patterns
- Benchmark different models on your specific use cases
- Validate caching strategies with real query distributions
- Measure the impact of architectural changes before full deployment
3. Intelligent Automation
Automate decisions that don't require human judgment:
- Model routing based on task complexity
- Cache invalidation based on content freshness
- Request prioritization based on user tier or urgency
- Failover when providers hit rate limits
4. Production-Ready Infrastructure
Build on reliable foundations:
- Use battle-tested orchestration frameworks
- Implement proper error handling and retry logic
- Plan for graceful degradation during outages
- Monitor everything with actionable alerts using observability platforms
Why Maxim AI for LLM Performance Optimization
Maxim AI provides the complete platform for building reliable, high-performance AI agents:
Comprehensive Observability
Track every aspect of your LLM application performance in real-time, from latency and costs to quality metrics and user experience.
Powerful Experimentation
Test prompt variants, model configurations, and architectural changes with statistical rigor before deploying to production.
Agent Simulation
Validate complex multi-agent workflows under various load conditions, identifying bottlenecks and optimization opportunities early.
Bifrost LLM Gateway
Intelligent request routing, caching, and failover across multiple LLM providers, all with zero code changes to your application.
Enterprise-Grade Prompt Management
Version control, A/B testing, and performance tracking for all your prompts, with team collaboration features built-in.
Conclusion
The evolution of LLMs from basic models to sophisticated systems with extended context windows and mixture-of-experts architectures demonstrates the industry's successful efforts to create more efficient models. However, building production-ready LLM applications still requires careful attention to performance bottlenecks across the entire stack.
By addressing these seven critical bottlenecks (latency, context management, prompt efficiency, caching, costs, orchestration, and throughput), you can build AI agents that deliver value reliably and at scale.
The key is taking a systematic, data-driven approach: measure everything, experiment continuously, and optimize based on evidence. With the right tools and strategies, you can achieve the performance and cost-efficiency needed for successful LLM applications in production.
Ready to optimize your LLM application performance? Maxim AI provides the evaluation, observability, and experimentation tools you need to build reliable AI agents. Request a demo to see how our platform helps engineering teams overcome performance bottlenecks and deliver exceptional AI experiences.
Want to learn more about building production-ready AI agents? Check out our related guides:
- Advanced Prompt Engineering Techniques for AI Agents
- The Complete Guide to LLM Cost Optimization
- Multi-Agent System Design: Best Practices for 2025
- Observability Best Practices for LLM Applications
Additional Resources:


