> ## Documentation Index
> Fetch the complete documentation index at: https://www.getmaxim.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Groq SDK
> Learn how to integrate Maxim observability with the Groq SDK for fast language model inference.
export const MaximPlayer = ({url}) => {
return ;
};
## Requirements
```
"groq"
"maxim-py"
```
## Env Variables
```
MAXIM_API_KEY=
MAXIM_LOG_REPO_ID=
GROQ_API_KEY=
```
## Initialize Logger
The first step is to set up the Maxim logger that will capture and track your Groq API calls. This
logger connects to your Maxim dashboard where you can monitor performance, costs, and usage
patterns.
```python {10, 13} theme={null}
import os
from maxim import Config, Maxim
from maxim.logger import LoggerConfig
# Get your API keys from environment variables
maxim_api_key = os.environ.get("MAXIM_API_KEY")
maxim_log_repo_id = os.environ.get("MAXIM_LOG_REPO_ID")
# Initialize Maxim with your API key
maxim = Maxim(Config(api_key=maxim_api_key))
# Create a logger instance for your specific repository
logger = maxim.logger(LoggerConfig(id=maxim_log_repo_id))
```
## Initialize Groq Client with Maxim
Once you have the logger, you need to instrument the Groq SDK to automatically capture all API
calls. The `instrument_groq` function wraps the Groq client to send observability data to Maxim.
```python {5} theme={null}
from groq import Groq
from maxim.logger.groq import instrument_groq
# Instrument Groq with Maxim logger - this enables automatic tracking
instrument_groq(logger)
# Initialize Groq client normally
client = Groq()
```
## Make LLM Calls Using Groq Client
After instrumentation, all your Groq API calls will be automatically logged to Maxim. You can use
the Groq client exactly as you normally would - no additional code needed for logging.
```python theme={null}
from groq import Groq
client = Groq()
# Create a chat completion request
# This call will be automatically logged to Maxim including:
# - Request parameters (model, messages, temperature, etc.)
# - Response content and metadata
# - Latency and token usage
# - Cost calculations
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explain the importance of fast language models"
}
],
model="llama-3.3-70b-versatile"
)
# Extract and use the response as normal
response_text = chat_completion.choices[0].message.content
print(response_text)
```
## Streaming Support
Groq excels at fast inference, and streaming responses provide real-time output. Maxim automatically
tracks streaming calls, capturing the full conversation flow and performance metrics.
### Make Streaming Calls
```python theme={null}
user_input = "Explain the importance of fast language models"
final_response = ""
response_chunks = []
# Create a streaming request
# Maxim will track the entire streaming session as one logged event
# including total tokens, time to first token, and streaming rate
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": user_input
}
],
model="llama-3.3-70b-versatile",
temperature=0.5,
max_completion_tokens=1024,
top_p=1,
stop=None,
stream=True # Enable streaming
)
# Process each chunk as it arrives
for chunk in stream:
chunk_content = chunk.choices[0].delta.content
if chunk_content:
response_chunks.append(chunk_content)
# Print the streamed text chunk in real-time
print(chunk_content, end="", flush=True)
# Combine all chunks to get the complete response
final_response = "".join(response_chunks)
```
## Async Chat Completion
For applications that need to handle multiple requests concurrently, Groq supports async operations.
Maxim seamlessly tracks async calls alongside synchronous ones.
### Make Async Calls
```python theme={null}
async def main():
# Create async Groq client
client = AsyncGroq()
# Make an async chat completion request
# This will be logged to Maxim just like sync calls
# Maxim tracks async patterns and concurrent request handling
chat_completion = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explain the importance of fast language models"
}
],
model="llama-3.3-70b-versatile",
temperature=0.5,
max_completion_tokens=1024,
top_p=1,
stop=None,
stream=False
)
# Extract and use the response
print(chat_completion.choices[0].message.content)
# Run the async function
await main()
# Use asyncio.run(main()) if not working in jupyter environment
```
## Async Completion with Streaming
Combining async operations with streaming gives you the best of both worlds - non-blocking execution
with real-time response streaming.
```python theme={null}
async def main():
client = AsyncGroq()
# Create an async streaming request
# Maxim logs the complete async streaming session
# including timing for async setup and streaming performance
stream = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explain the importance of fast language models"
}
],
model="llama-3.3-70b-versatile",
temperature=0.5,
max_completion_tokens=1024,
top_p=1,
stop=None,
stream=True # Enable streaming in async mode
)
# Process streaming chunks asynchronously
async for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
await main()
```
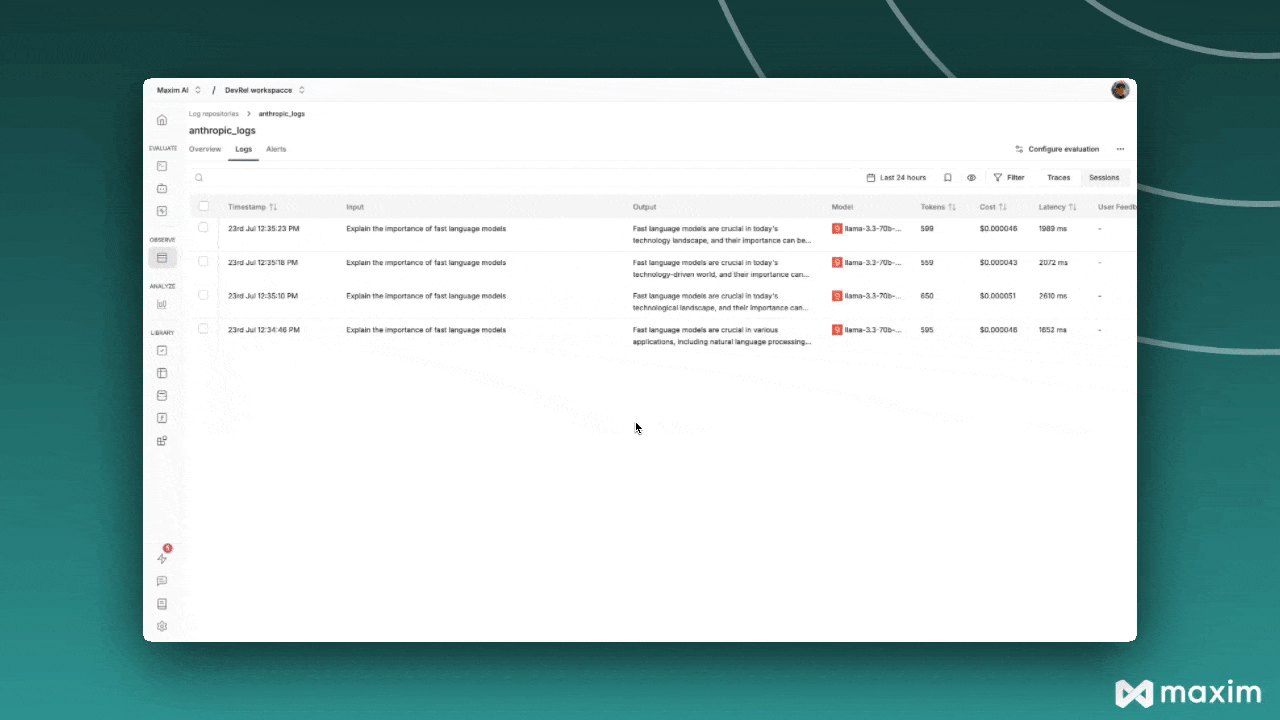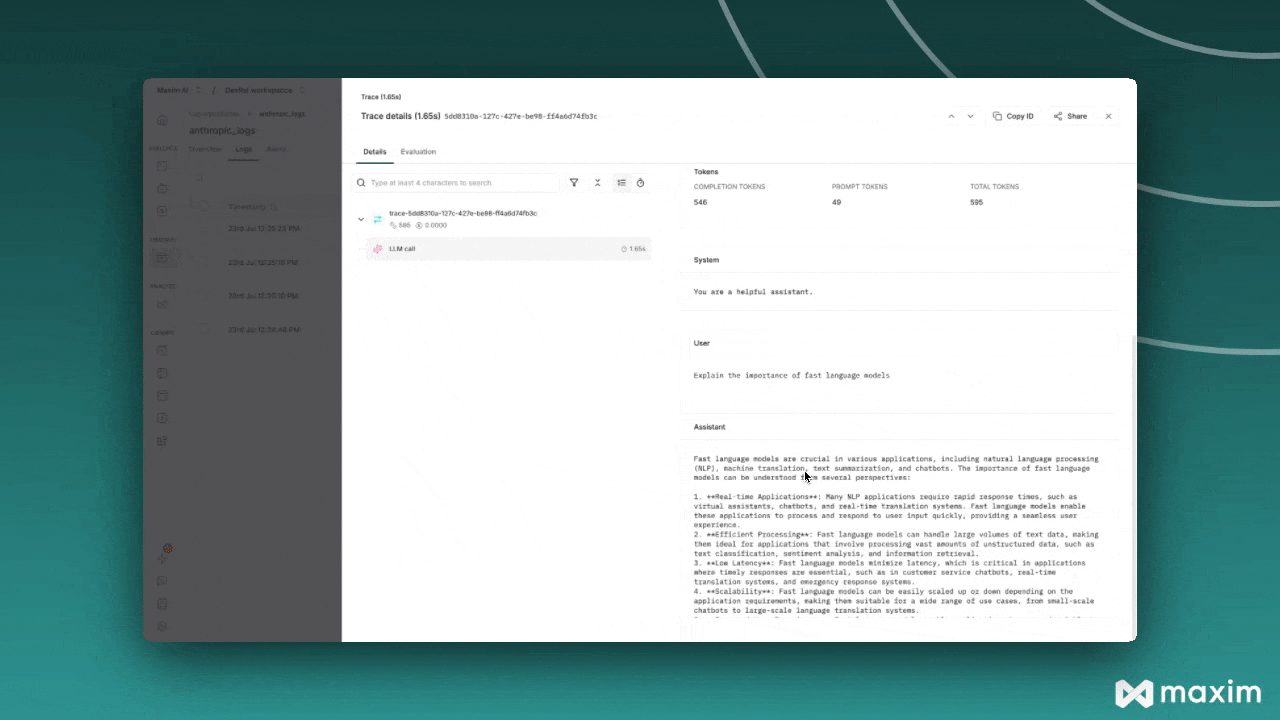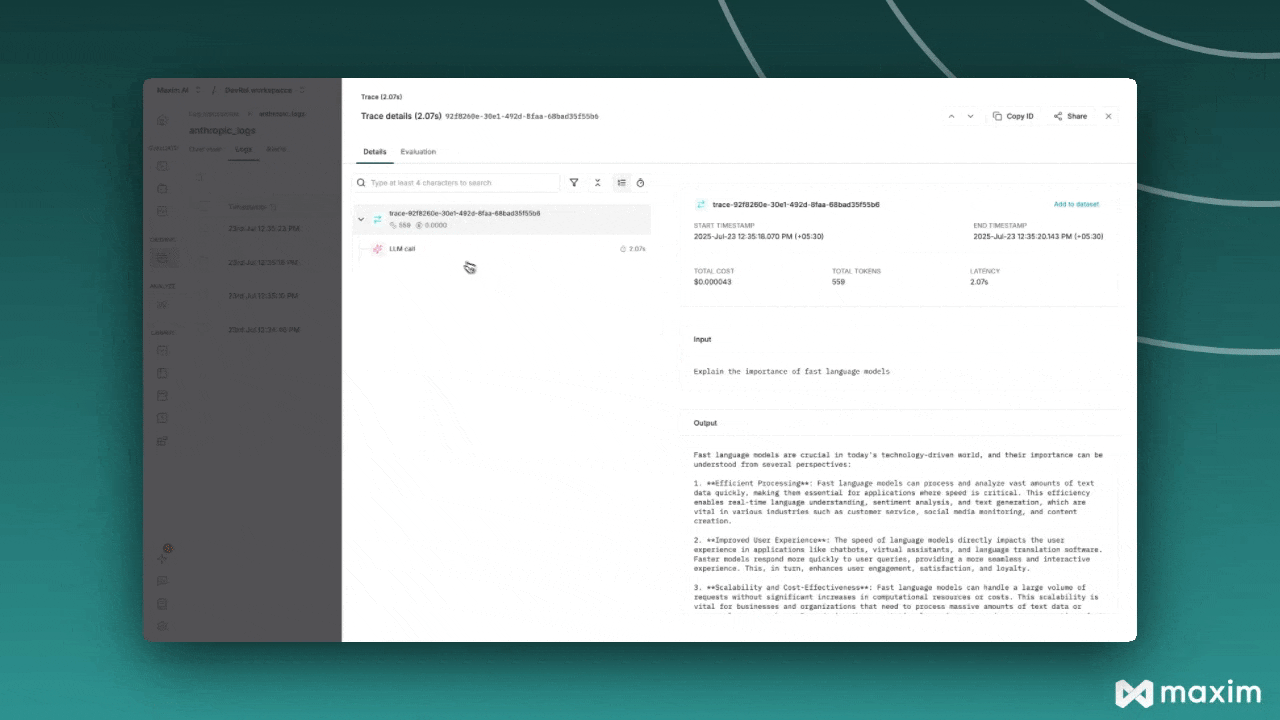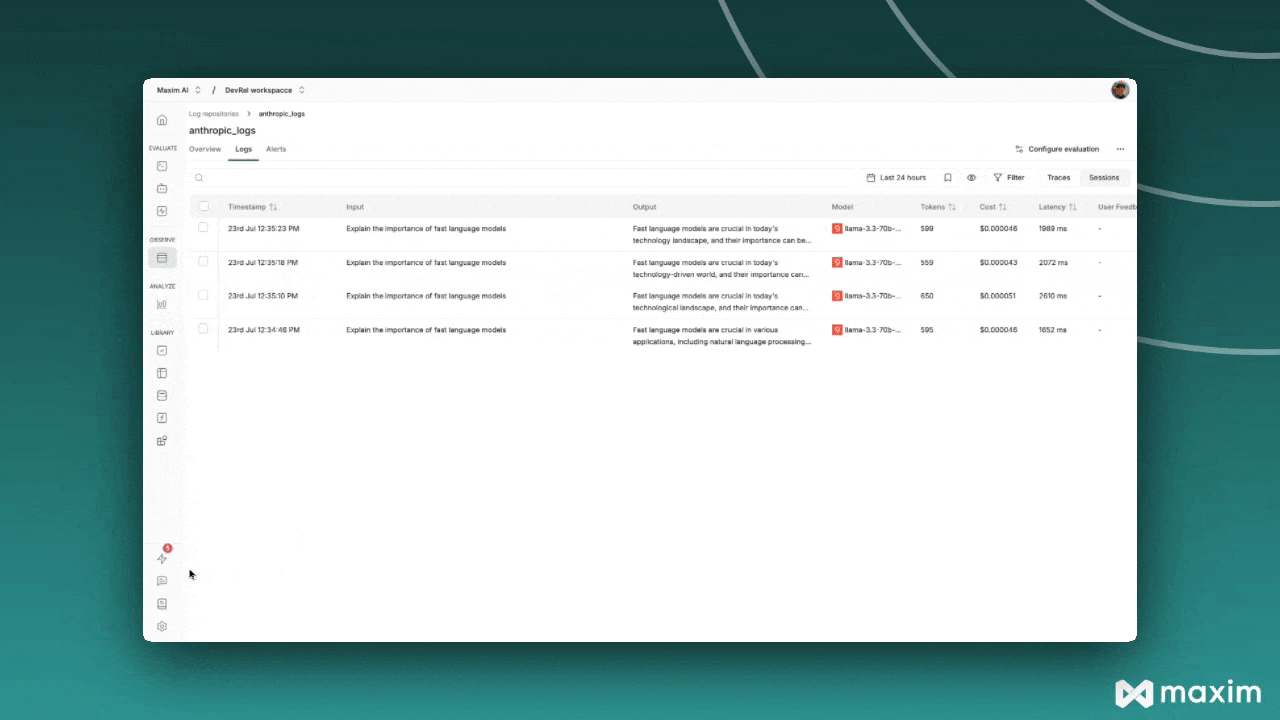
## What Gets Logged to Maxim
When you use Groq with Maxim instrumentation, the following information is automatically captured
for each API call:
* **Request Details**: Model name, temperature, max tokens, and all other parameters
* **Message History**: Complete conversation context including system and user messages
* **Response Content**: Full assistant responses and metadata
* **Usage Statistics**: Input tokens, output tokens, total tokens consumed
* **Cost Tracking**: Estimated costs based on Groq's pricing
* **Error Handling**: Any API errors or failures with detailed context
 ## Resources
## Resources